我可能是从币安上线 OPEN 现货交易对的时候才开始真正注意到这个项目的。老实说,当时市场上 AI+Crypto 的项目一抓一大把,但大多数要么在做算力租赁,要么在做模型训练平台,同质化严重得很。OpenLedger 倒是选了一条少有人走的路:它在琢磨怎么让数据贡献者像 YouTube 创作者一样,躺着就能从 AI 的推理收益里拿到分成。这个切入点,至少在叙事层面,抓住了当前 AI 行业一个相当根本的痛点。
OpenLedger 的核心叙事可以拆成三个关键词:Datanets、归因证明和 $OPEN 代币。它们就像是三根骨架,撑起了整个"可支付人工智能"(Payable AI)的经济框架。一个个来说。
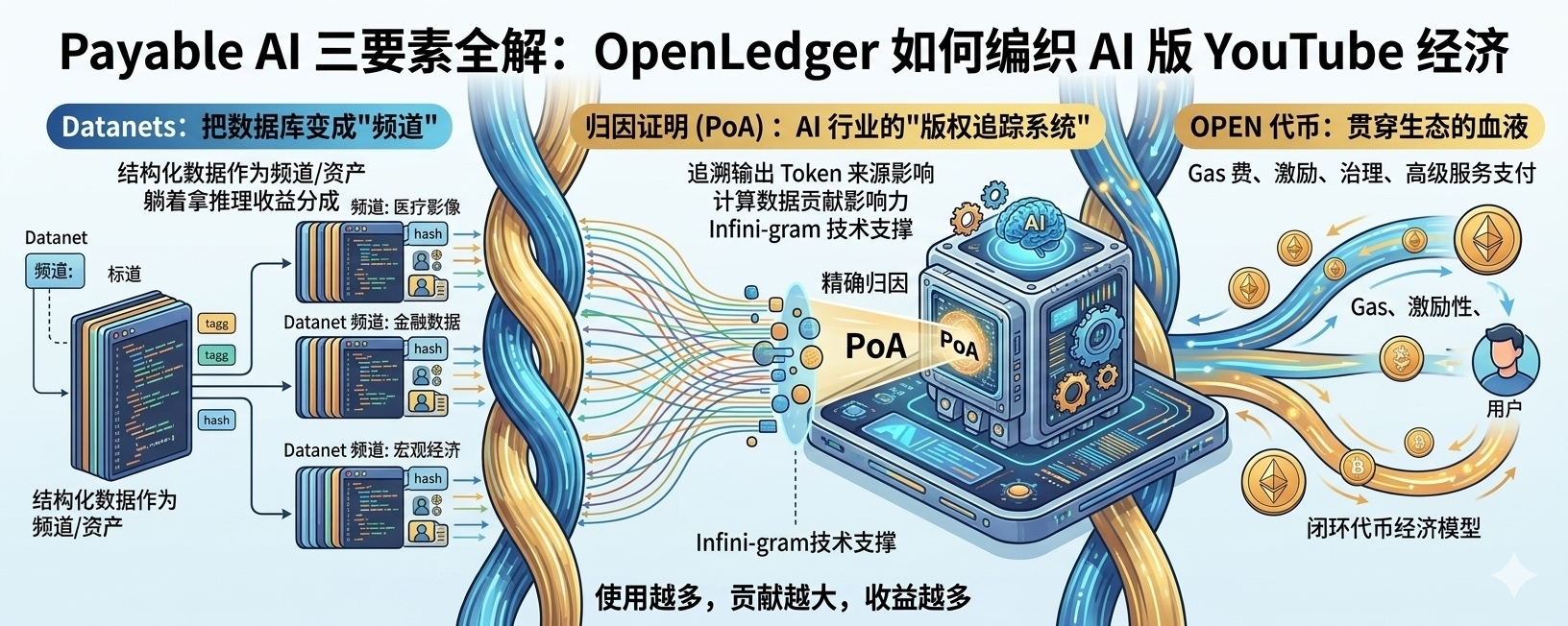
Datanets:把数据库变成"频道"
先说 Datanets。这个词是"Data Networks"的缩写,乍一听有点抽象,但你把它想象成 YouTube 上的一个频道,就好理解了。
在 YouTube 上,一个创作者经营一个频道,持续发布某个领域的内容,积累订阅者。Datanets 做的其实是类似的事——只不过上传的不只是视频,而是结构化的、带有明确来源标签的数据集。比如一个放射科医生可以创建一个专门标注医学影像的 Datanet,一个金融分析师可以维护一套宏观经济指标的 Datanet。每个数据点在链上都有哈希记录和贡献者元数据,谁传的、什么时候传的、被谁用过,一目了然。
关键区别在哪里?在传统的世界里,数据标注基本是一锤子买卖。你帮某家 AI 公司标完一批数据,拿一次钱,后面模型再怎么赚钱都跟你没关系了。Datanets 试图改变这个逻辑——数据不再是消费品,而是资产。只要你的数据持续被模型调用、持续产生推理输出,你就可以持续获得收益分成。
不过说实话,这个设想虽然美好,但有个挺现实的张力我一直在琢磨:真正高质量的数据,往往是那些拥有者最不愿意公开的数据。医疗影像也好、企业内部工作流也好、真实的交易记录也好,这些东西的价值恰恰在于它们的稀缺性和私有性。一旦放到公开的 Datanets 里,稀缺性就被稀释了,竞争壁垒也随之消失。所以 Datanets 最终演化成的形态,可能不是理想中那种开放的"数据公地",而更像是一堆各自为政的半封闭数据联盟——谁能手握高质量数据的入口,谁就掌握了话语权。这一点,我觉得是讨论 Datanets 的时候绕不开的一个现实问题。
归因证明:AI 行业的"版权追踪系统"
第二个要素是归因证明,Proof of Attribution,简称 PoA。这是整个体系里技术含量最高的部分,也是 OpenLedger 跟其他 AI 区块链项目拉开差距的地方。
它的逻辑不难理解:当你的数据被模型训练之后,模型在推理时产生了某个输出,PoA 能从技术上追溯这个输出到底受哪些数据的影响、影响程度有多大。每个数据贡献者根据实际的影响力占比,拿到对应比例的报酬。换句话说,PoA 给数据贡献建立了一套"版权追踪系统",把过去那个"AI 公司免费扒数据、模型赚钱、贡献者颗粒无收"的黑箱模式,变成了一套透明、可验证的分配机制。
有意思的地方在于技术实现的细节。给几百万参数的小模型做归因还算简单,可以用影响函数来估算每个数据点对输出的贡献。但面对几亿甚至上千亿参数的大模型,这种方法基本歇菜——计算量指数级增长,商业上不可行。OpenLedger 的解法是引入一种叫 Infini-gram 的技术。它不分析模型内部结构,而是直接在原始训练数据中做后缀数组匹配,追踪每个输出 Token 的最长匹配来源。1.4 万亿 Token 的数据集,查询只需要 20 毫秒,每 Token 存储成本仅 7 字节。对于那些把模型权重视为商业机密的 AI 公司来说,这套方案不需要访问模型内部就能完成归因,算是找到了一个精妙的平衡点。
但我必须说,PoA 这套机制在实践中能做到什么精度,我个人是持谨慎乐观态度的。AI 模型的输出本质上是对海量数据的压缩和重组,一个 Token 的生成可能同时受到几万条数据的影响,要把每个 Token 精确归因到具体的贡献者,这个难度不亚于在一锅煮好的汤里分辨出每一粒盐来自哪个盐场。技术方向是对的,但距离"精确归因"可能还有相当长的路要走。
OPEN 代币:贯穿生态的血液
第三个要素是$OPEN 代币。它是整个生态系统的血液,串联起支付、激励和治理三大功能。
OPEN 总供应量 10 亿枚,初始流通约 2.155 亿,社区和生态分配占比高达 61.71%。团队和投资人的代币设有 12 个月锁仓期,之后分 36 个月线性解锁。从代币经济结构来看,算是比较注重长期对齐的——至少不是那种一解锁就砸盘跑路的模型。
在功能层面,OPEN 承担着四个核心角色:第一,链上所有活动(数据注册、模型调用、代理协调)都需要用 OPEN 支付 Gas 费;第二,节点验证者、数据提供者、模型开发者、代理开发者全部以 OPEN 作为奖励;第三,OPEN 持有者参与治理投票,决定归因标准和资金分配;第四,部分高级 AI 服务要求使用 OPEN 支付费用。这个设计意味着只要生态里的活动量增长,OPEN 的需求就会同步增长,形成了一个"使用即消耗、消耗即价值"的闭环。
这里面有一个设计细节值得拎出来聊聊。OpenLedger 的归因证明机制鼓励的是一种协作逻辑,而不是零和竞争。它奖励的是那些能被开发者广泛调用的基础数据和模型组件,而不是那些关起门来自己跑分的模型。相比 Bittensor(TAO)那种鼓励模型间互相竞争的架构,OPEN 的激励机制更偏向于构建一个可组合、可扩展的生态底层。这个设计哲学上的差异,长期来看可能会在社区文化和生态丰富度上产生截然不同的结果。
AI 版 YouTube 经济:蓝图很性感,落地得跑通
把这三个要素串联起来,OpenLedger 描绘的是一个怎样的图景呢?
简单说:数据贡献者把高质量数据上传到 Datanets,就像创作者在 YouTube 上传视频;开发者使用这些数据训练模型或调用推理;每一次推理调用产生的费用,通过 PoA 归因系统精确计算每个数据贡献者的影响力占比,自动用 OPEN 代币完成分账。整套流程完全自动化、链上透明,不需要依赖任何中心化平台的"良心发现"。
跟 YouTube 的类比其实相当贴切。YouTube 用 Content ID 系统追踪视频版权,按播放量给创作者分广告费;OpenLedger 用 PoA 追踪数据来源,按推理调用量给数据贡献者分代币。两者的核心逻辑都是"使用越多、贡献越大、收益越多"。
但说实话,要让这个蓝图真正跑起来,有几个坎是绕不开的。第一个是数据质量的"柠檬市场"问题——如果激励机制设计得不够精细,低质量数据可能会像水军刷量一样涌入系统,劣币驱逐良币。第二个是需求端的问题:AI 公司到底愿不愿意为归因数据付费?监管压力可能会倒逼这个趋势(毕竟 OpenAI、Google 都在面临数据来源的诉讼和审查),但靠监管驱动和靠市场需求驱动,这是两码事。第三个也是最根本的一个:真正稀缺的高质量数据,拥有者有没有足够的动力把它放到公开网络上?
话又说回来,就算这些问题暂时没有完美的答案,@OpenLedger 至少做了一件很对的事情——它在 AI 数据价值链里,挑了一个最核心也最难啃的骨头来啃。在数据质量为王的时代,谁能解决数据价值分配问题,谁就能吸引到最优质的数据资源。能不能啃下来是另一回事,但敢于在这个方向上认真投入技术研发和工程落地,本身就比市面上大部分炒概念的 AI 项目高了一个段位。#OpenLedger