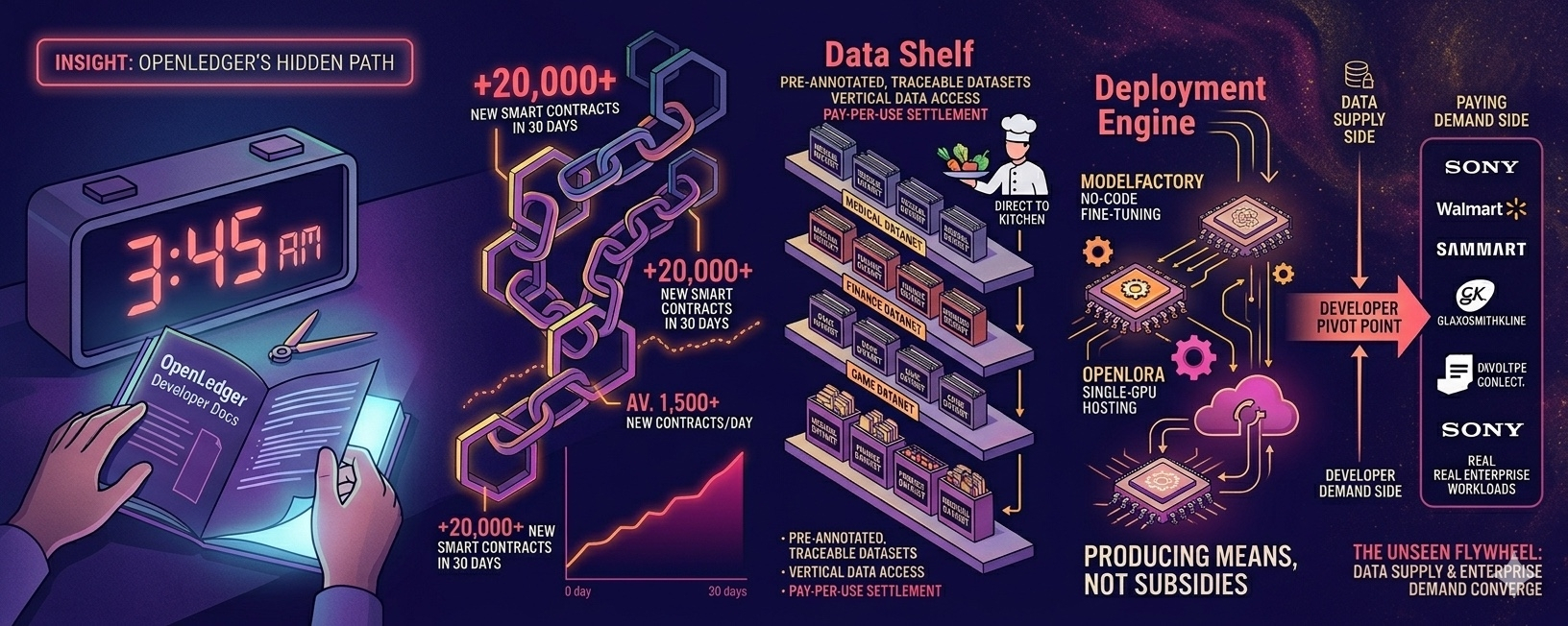
深夜翻看OpenLedger的开发者文档,突然被一个数字震住了——过去三十天,有超过两万份新的智能合约部署到了这条链上,每天平均一千五百个新合约冒出来。放在EVM兼容链的维度里比,这个增速不算爆炸,但对于一条2025年9月才上主网的AI专项链来说,多少有点意思。
这段时间圈子里聊OPEN,十个有九个在掰扯“数据确权”,剩下一个在算回购能不能跑赢解锁。但我最近盯上了另一条被集体忽略的线索:开发者为什么要来这条链上搭东西?
别急着说“有补贴有奖励”。币圈最不缺的就是烧钱拉开发者的项目——补贴一停,鸟兽散。我真正想弄清楚的是,OpenLedger到底给了开发者什么别人给不了的东西。
翻完一圈文档,我发现它给了开发者两样很实在的东西。
第一个是数据货架。开发者要训一个专业模型,最头疼的不是写代码——是找数据。高质量标注数据在传统市场里要么贵得离谱,要么根本买不到。OpenLedger搞了二十多个Datanets,医疗、金融、游戏领域的垂直数据全部分类上架、链上溯源。开发者不需要自己从头搭数据集,在Datanets上直接挑、直接调、按调用量自动结算。这像什么呢,像你开餐馆不再需要自己种菜养猪,打开App下单,食材按需送到后厨,按用量扣款。
第二个是部署引擎。ModelFactory零代码微调,OpenLoRA单张GPU托管上千个模型——这些之前聊过,不再赘述。但它们加在一起传递的信号很清楚:OpenLedger不只给开发者发补贴,它给的是生产资料。数据是生产资料,模型部署工具是生产资料,链上结算管道也是生产资料。
那问题来了——有生产资料就有人来吗?
链上数据给了一部分答案:测试网已经有一百二十三万个地址在跑,两万两千笔日交易量,这些数字还在往上走。更关键的是企业侧——Sony、Walmart、葛兰素史克不是来领空投的,是在Datanets上跑真实AI工作负载,掏了真金白银。这意味着开发者在这条链上做的东西有真实的付费方,不只是吃补贴。
说白了,@OpenLedger OpenLedger给开发者画的饼不是“来我们这儿领代币”——虽然代币激励肯定有——而是“来我们这儿搞生产,客户已经在这儿了”。
这才是开发者生态里最难复制的东西。数据货架可以搭,部署工具可以写,但付费客户群一旦形成,后来者想撬走就不是补贴能做到的。这就是OpenLedger的护城河——数据供给侧和付费需求侧同时在链上运转,开发者是连接这两端的枢纽。 枢纽一旦站稳,整个结构就稳了。
当然,任何生态建设都有冷启动难题。OpenLedger目前12组开发团队远算不上“繁荣”,但考虑到主网上线不到一年,加上企业客户已经在持续付费,这个飞轮的雏形已经能看见了。
盯着价格做决策的人,看的是回购和销毁。盯着项目做判断的人,看的是谁在用、谁在搭、谁在付钱。OpenLedger的开发者叙事,现在还没被市场充分定价——这才是值得长期盯着看的东西。#OpenLedger $OPEN