
La parte su cui continuo a bloccarmi
Qualche notte fa ho provato a schizzare cosa effettivamente entra in un singolo output di intelligenza artificiale moderna. Solo per vedere se riuscivo a mappare tutto in modo chiaro.
Non ci sono riuscito.
Dataset della community che alimentano il modello di base, fine-tuning specifici per dominio da sviluppatori diversi, strati di recupero che iniettano contesto esterno in tempo reale, feedback degli utenti che rimodellano il comportamento nel tempo, framework di orchestrazione che coordinano l'esecuzione sotto tutto questo. Tutto sovrapposto, tutto che influenza il risultato finale in modi che sono davvero difficili da separare.
E poi un output appare in superficie e in qualche modo stiamo ancora parlando di attribuzione come se fosse un problema risolto.
Quella è la parte su cui continuo a bloccarmi. Perché una volta che i sistemi AI vanno oltre la generazione di contenuti e iniziano a toccare flussi di lavoro, contratti, esecuzioni finanziarie, agenti autonomi che fanno cose per conto tuo — le domande economiche diventano molto più difficili. Chi ha creato il valore, chi merita una compensazione, e se qualcosa si rompe, chi porta effettivamente la responsabilità? Non penso che l'infrastruttura AI attuale abbia una risposta pulita a tutto ciò.
Perché la Maggior Parte della Conversazione sull'Infrastruttura AI Mi Sembra Incompleta
La maggior parte delle discussioni serie intorno all'infrastruttura AI ruota ancora attorno alla capacità — modelli più intelligenti, inferenze più economiche, output più rapidi, finestre di contesto più ampie — e ovviamente tutto ciò conta. Una migliore intelligenza si accumula rapidamente e non lo sto sminuendo.
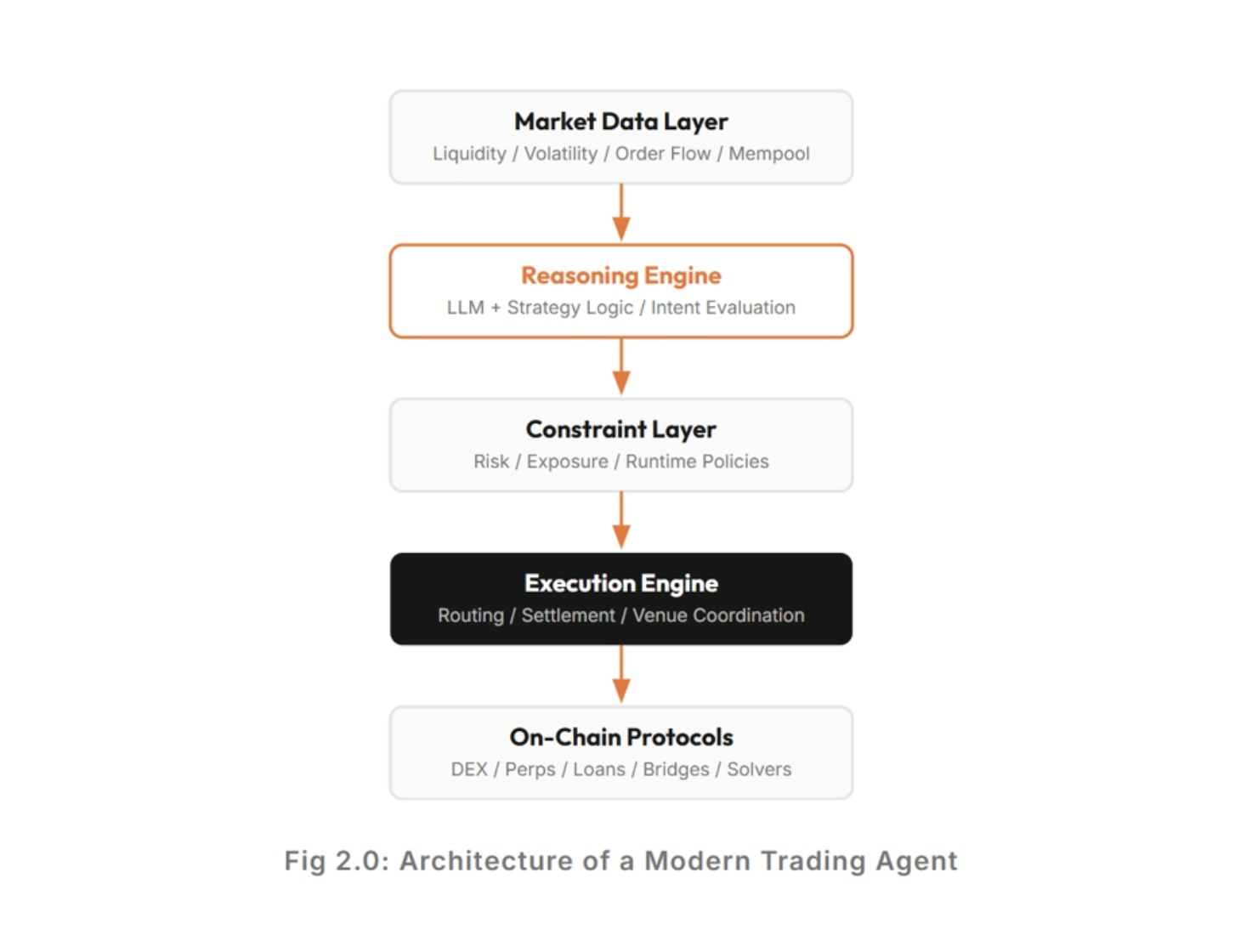
Ma più tempo passo a guardare dove stanno realmente andando i sistemi AI, meno sono convinto che l'intelligenza sia il problema più difficile rimanente. Penso che la coordinazione potrebbe esserlo. Non la coordinazione nel semplice senso tecnico. Più come la coordinazione intorno alla proprietà, all'attribuzione, alla responsabilità e ai diritti economici una volta che i sistemi AI iniziano a partecipare a vere attività economiche su larga scala.
Quel cambiamento sembra più grande di quanto la maggior parte delle narrazioni attuali riconosca.
Perché OpenLedger Ha Iniziato a Distinguersi per Me in Modo Differente
Sarò onesto — la mia lettura iniziale su @OpenLedger era piuttosto scettica. L'ho catalogata mentalmente sotto "narrazione interessante, grandi promesse, molto linguaggio sul futuro delle economie AI." Ho visto abbastanza versioni di quella proposta da diventare abbastanza bravo a ignorarla automaticamente.
Ciò che ha cambiato la mia lettura è stato passare più tempo sull'architettura e sulla roadmap effettive piuttosto che sulla cornice superficiale.
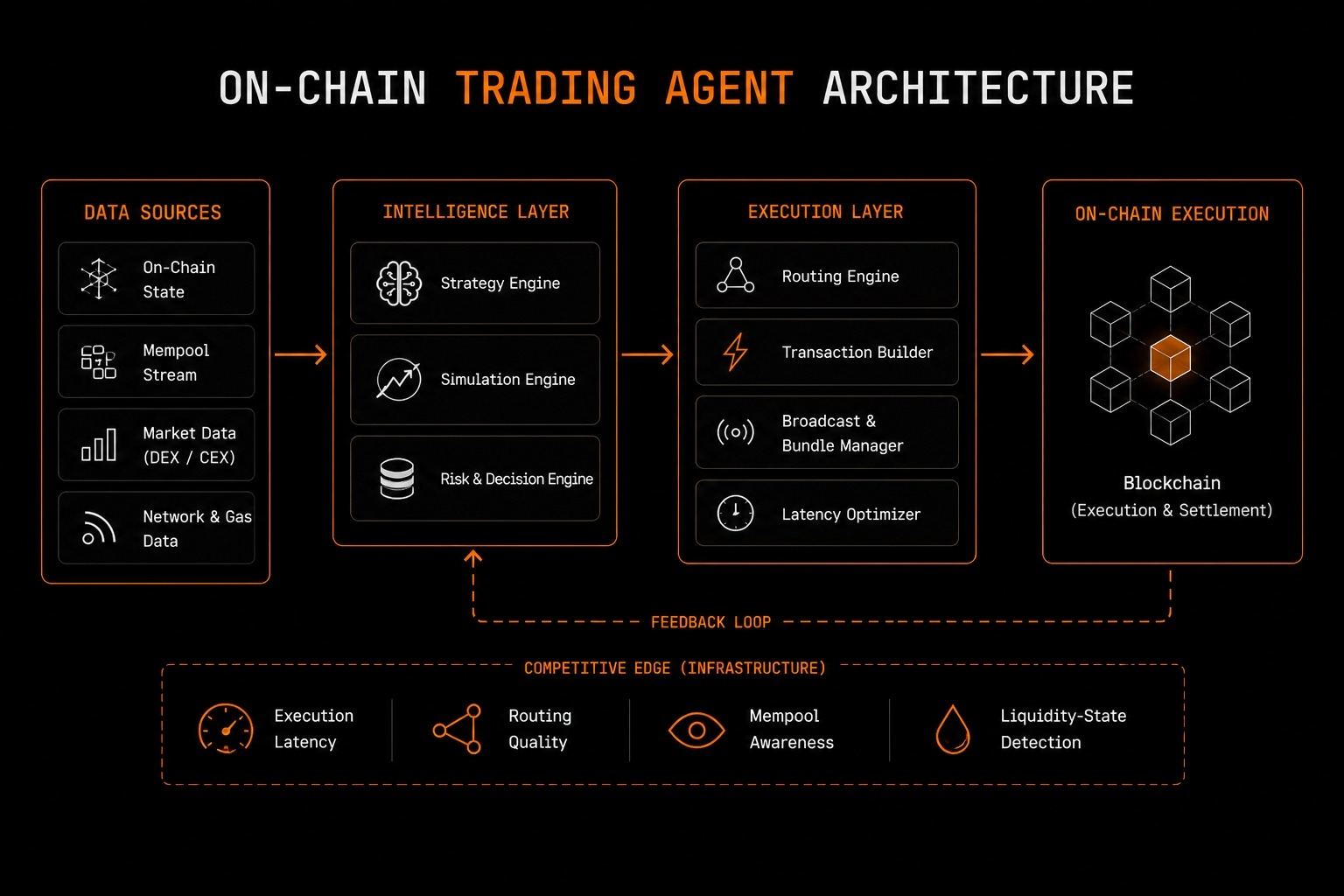
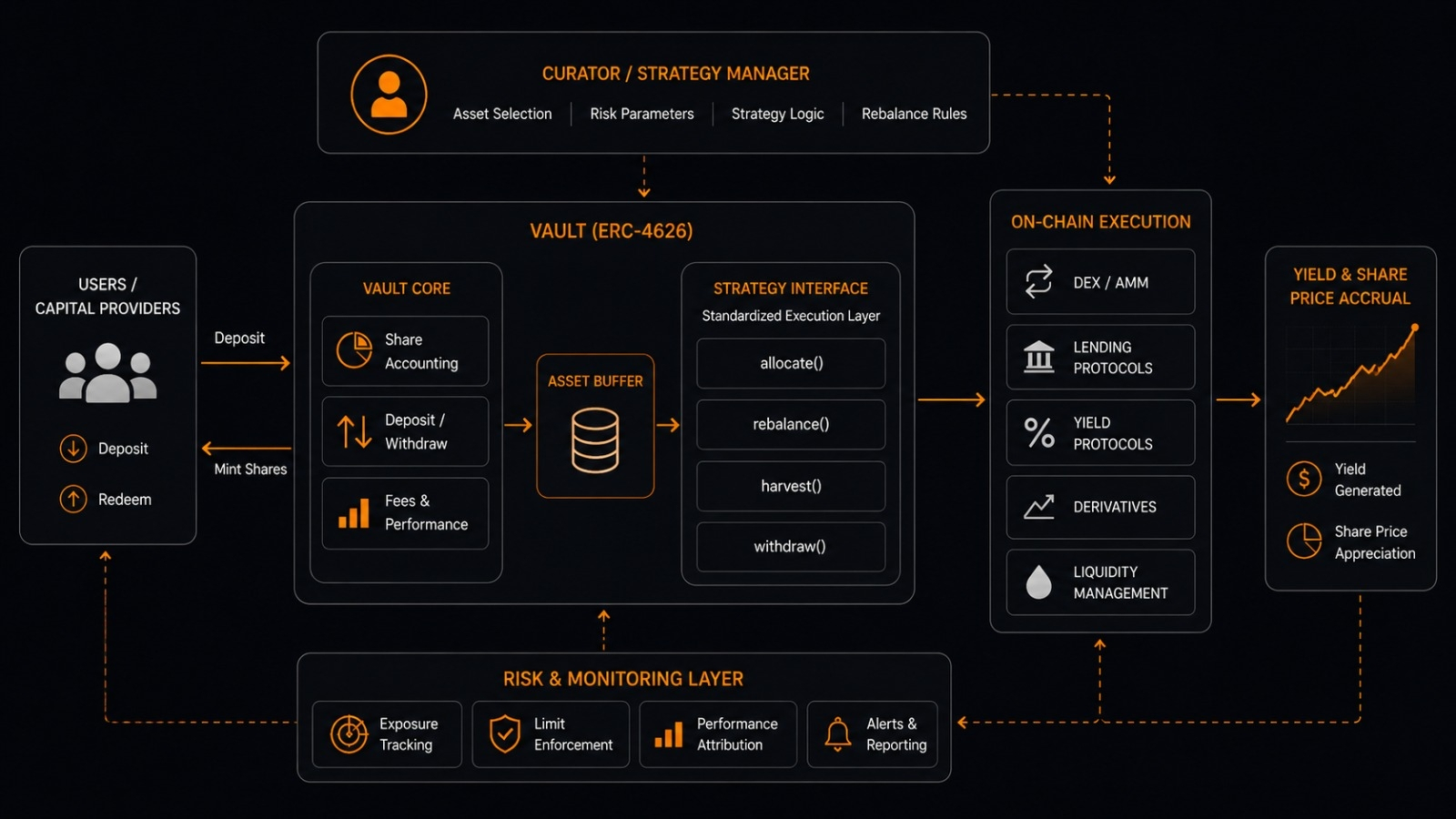
La direzione verso cui sembra dirigersi OpenLedger è meno focalizzata sul rendere l'AI più potente e più sul rendere il comportamento dell'AI economicamente rintracciabile. La loro roadmap del 2026 delinea un'infrastruttura costruita attorno all'attribuzione, alle economie degli agenti, all'identità on-chain, alla provenienza verificabile dei dati e ai pagamenti autonomi. L'idea è che i sistemi AI non dovrebbero solo generare output — dovrebbero preservare la responsabilità economica su come quegli output sono stati creati e chi ha contribuito a essi.
Questo è un problema significativamente diverso da quello che la maggior parte dei progetti AI sta cercando di risolvere.
Il Concetto di "AI Pagabile" È Più Interessante di Quanto Sembra
Una cosa che OpenLedger continua a promuovere è ciò che chiamano "AI Pagabile" — e devo ammettere che inizialmente suonava come un branding standard crypto per me.
Ma sotto c'è un'idea genuinamente interessante. Sistemi AI in cui dataset, modelli, contributori e agenti possono essere tutti rintracciati e compensati automaticamente attraverso un'infrastruttura di attribuzione on-chain. Il loro OPEN Mainnet è già stato lanciato con qualcosa chiamato Proof of Attribution, progettato per monitorare come i dataset e i modelli influenzano effettivamente gli output e indirizzare le ricompense ai contributori di conseguenza.
Più ci penso, più penso che l'attribuzione alla fine diventi inevitabile una volta che i sistemi AI iniziano a coordinare comportamenti economici reali. I mercati richiedono responsabilità. Soprattutto una volta che gli agenti autonomi iniziano a gestire flussi di lavoro che coinvolgono denaro, contratti o diritti di esecuzione su qualsiasi scala significativa.
La Partnership con Story Protocol Ha Attirato la Mia Attenzione Più di Quanto Mi Aspettassi
Un aggiornamento che penso sia stato trascurato è la partnership di OpenLedger con Story Protocol all'inizio di quest'anno.
L'obiettivo era creare uno standard per l'addestramento AI con diritti autorizzati e pagamenti automatici per i creatori — consentendo la licenza della proprietà intellettuale nei sistemi AI preservando l'attribuzione, permessi applicabili e distribuzione automatizzata delle royalty.
Sembra di nicchia quando lo leggi per la prima volta. Ma penso che punti verso qualcosa di più grande: l'infrastruttura AI che si sta lentamente muovendo verso livelli di proprietà programmabili invece di operare indefinitamente all'interno di zone grigie legali. In questo momento, la maggior parte dei sistemi AI funziona come scatole nere economiche. I dati entrano, gli output emergono, la provenienza del contributo diventa immediatamente torbida. Probabilmente funziona bene durante i cicli di crescita iniziali. Sono meno convinto che regga una volta che i sistemi AI diventano profondamente integrati in settori regolamentati o iniziano a coordinare attività economiche serie in modo autonomo.
La Parte Scettica
Dovrei dirlo anche questo, perché altrimenti sembra che questa cosa sia più pulita di quanto non mi senta in realtà.
Monitorare il contributo attraverso i sistemi AI stratificati sembra genuinamente, straordinariamente difficile in pratica. I modelli influenzano altri modelli in modi che è difficile disfare, i dati sintetici contaminano la provenienza, i loop di feedback rimodellano gli output nel tempo in modi che nessuno ha pianificato completamente. E una volta che il denaro reale entra in gioco, le persone troveranno modi per manipolare qualsiasi meccanismo di attribuzione esista — gli esseri umani hanno trasformato l'esploitazione dei sistemi di incentivi in uno sport competitivo a livello di civiltà secoli fa, il crypto ha solo aggiunto classifiche e immagini del profilo anime a tutto ciò 😭
Quindi non sono qui a pensare che questo sia risolto. Molte narrazioni sull'infrastruttura AI sembrano ancora incredibilmente lontane dall'adozione reale.
Ma penso che il problema sottostante sia reale. E i livelli di infrastruttura che gestiscono fiducia, coordinazione e responsabilità tendono a diventare più importanti nel tempo piuttosto che meno rilevanti.
Dove Continuo a Atterrare
Più penso alle economie AI, meno sono convinto che l'intelligenza dei modelli da sola catturi il vero valore a lungo termine. La coordinazione potrebbe farlo. Non solo coordinare i sistemi tecnicamente, ma anche coordinare proprietà, permessi, responsabilità e diritti economici attraverso reti sempre più autonome che non sono state progettate con tutto ciò in mente.
Forse OpenLedger diventa parte di quell'infrastruttura, forse no — sembra comunque genuinamente presto e sarei scettico nei confronti di chiunque parli con reale certezza qui.
Ma non posso davvero ignorare la direzione ormai. Più guardo in profondità nei sistemi AI, meno il problema difficile sembra essere rendere l'intelligenza più intelligente. Sembra più una questione di capire come l'intelligenza partecipa all'interno dei sistemi economici senza rendere la responsabilità completamente invisibile nel processo.
