
Quando facevo analisi dei dati, una volta dovevo calcolare il ranking del contributo di duecentomila registrazioni clienti sui ricavi. Ho usato un metodo brutale e ci ho messo quattro ore. Il capo non ha potuto aspettare.
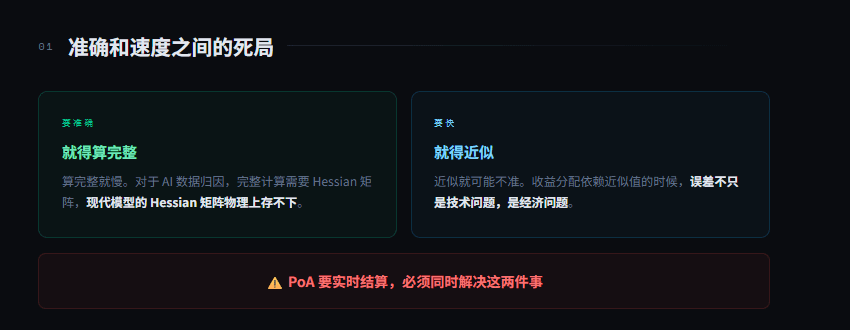
Questa situazione è molto comune. Per essere precisi devi calcolare tutto, e calcolare tutto richiede tempo. Per essere veloci devi approssimare, e l'approssimazione può essere imprecisa. C'è un muro tra precisione e velocità.
DataInf sta demolendo quel muro nel campo dell'attribuzione dei dati AI.
Perché la matrice Hessiana è un vicolo cieco
#OpenLedger La Proof of Attribution deve fare una cosa: ogni volta che il modello inferisce, calcola quanto ogni dato di training contribuisce a questo output, e poi distribuisce i profitti proporzionalmente.
La matematica sottostante è la funzione di influenza. Per calcolare completamente la funzione di influenza, è necessario il matrice Hessiana, ovvero la matrice delle seconde derivate della funzione di perdita del modello rispetto a tutti i parametri. I moderni modelli linguistici hanno decine di miliardi di parametri, la dimensione della matrice Hessiana è il quadrato del numero di parametri. Questa matrice non può essere memorizzata, per non parlare di calcoli in tempo reale. Gli algoritmi brutali qui non sono lenti, è fisicamente impossibile.
La soluzione ingegneristica di DataInf
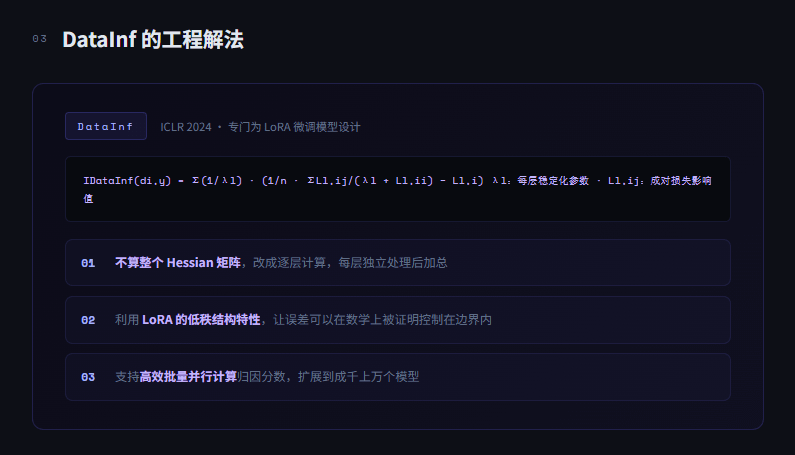
DataInf proviene dal paper omonimo di ICLR 2024, progettato specificamente per modelli di fine-tuning LoRA.
L'idea centrale è di non calcolare l'intero Hessiano, ma di passare a un calcolo per strati, trattando ogni strato in modo indipendente e poi sommando. LoRA aggiorna solo i parametri degli adattatori a bassa rango, questa caratteristica strutturale permette di controllare gli errori approssimativi all'interno dei confini matematici. L'approssimazione non è solo sufficiente, ma è garantita teoricamente.
L'effetto reale è molto diretto. Il white paper di OpenLedger afferma chiaramente di supportare calcoli efficienti dei punteggi di attribuzione in batch. Dopo ogni inferenza, i guadagni dei contributor possono essere liquidati quasi in tempo reale. Se si utilizza il calcolo completo dell'Hessiano, un singolo calcolo di attribuzione potrebbe richiedere ore, rendendo l'intero meccanismo PoA solo teoria.

Impatto reale per gli utenti di Binance
Se contribuisci con dati su @OpenLedger , o possiedi token OPEN, la qualità operativa di DataInf influenza direttamente i tuoi guadagni.
Dopo il lancio della mainnet, ci sono due cose da tenere d'occhio.
La prima è la velocità di liquidazione. Se DataInf sta davvero funzionando in tempo reale, i guadagni dei contributor dovrebbero essere aggiornati nei minuti successivi all'inferenza, non in batch giornalieri. La seconda è il bias sistematico nella distribuzione. Gli errori casuali possono compensarsi nel lungo termine, ma se un certo tipo di dati è costantemente sottovalutato, l'offerta si distorcerà, influenzando infine la qualità del modello e il valore del token.
Le parti non chiarite nel white paper
Il limite di errore è un valore teorico, la distribuzione reale dipende dai dati reali e dalla struttura del modello.
L'affidabilità dell'errore di DataInf si basa sulla struttura di fine-tuning LoRA. I modelli attuali di OpenLedger sono tutti fine-tuned con LoRA, ma se in futuro si integreranno modelli di fine-tuning completo, o si adotteranno nuove architetture come DoRA, l'errore sarà ancora controllabile? Il white paper non risponde a questa domanda.
Un altro problema è il meccanismo di reclamo. Se i contributor notano di guadagnare meno del previsto, hanno la motivazione per tracciare, mettere in discussione e richiedere audit. La prova teorica di DataInf non è equivalente agli standard di prova in caso di controversie on-chain. È necessario progettare chiaramente a livello di governance.
Criteri di valutazione
Il problema della mia violenza di traversamento di qualche anno fa, alla fine ho cambiato algoritmo di campionamento, perdendo il 3% di precisione ma velocizzando di venti volte. Il capo ha detto che va bene così.
La logica di DataInf è la stessa. Precisione sufficiente più velocità disponibile in tempo reale è ciò che consente a PoA di concretizzarsi. Sufficiente non significa scendere a compromessi, ma è un giudizio pragmatico ingegneristico.
Dopo il lancio della mainnet, se la velocità di liquidazione è soddisfacente e la comunità non ha lamentele sistemiche, DataInf può considerarsi concluso.$OPEN