The partnership framing is clean: Story Protocol handles IP rights, OpenLedger handles execution. One registers ownership, the other pays for usage. Together they form something like a complete stack for legal and economic AI accountability.
I've spent time looking at where the two systems actually touch, and the joint is more complicated than the announcement framing suggests.
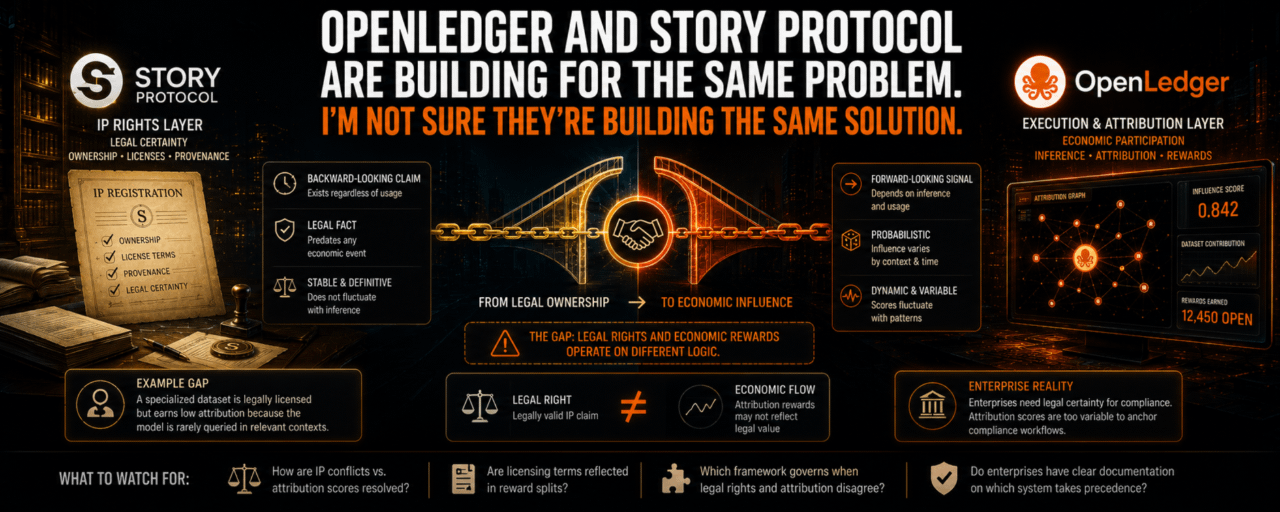
IP rights and attribution rewards operate on fundamentally different logic, and that difference matters more than it appears at first glance.
An IP right is a backward-looking claim. You create something, register its ownership, and the right exists regardless of whether anyone uses it. The right doesn't activate, fluctuate, or decay based on inference patterns. It exists as a legal fact that predates any economic event connected to it.
Attribution rewards on OpenLedger work differently. They're forward-looking and inference-dependent. A DataNet earns rewards when its data influences a specific model output at a specific moment. If that model is never queried for tasks where the DataNet's contribution is meaningful, the attribution weight stays low regardless of how valuable or legally sound the underlying data actually is. Influence scores are continuous, probabilistic, and variable over time.
Combining these two systems assumes their outputs are compatible. That assumption deserves more scrutiny than it's received.
Consider the gap that opens between them in practice. A content creator registers a specialized dataset through Story Protocol with clear licensing terms and verified provenance. That dataset gets contributed to a DataNet on OpenLedger. The model trained on it gets used primarily for inference tasks in adjacent domains where this particular dataset's influence scores are low. The creator holds a legally valid IP claim. They're earning attribution rewards that don't reflect the legal value of what they contributed. That gap between the legal right and the economic flow isn't a technical failure. It's a structural feature of how these two systems were built independently and then joined.
Music licensing maps onto this closely. A songwriter can have perfect copyright registration, detailed ASCAP paperwork, and a clean chain of ownership documentation. None of that guarantees meaningful streaming revenue if the platform's recommendation logic doesn't surface the work and listening patterns don't generate plays. The legal right and the economic right exist on separate rails. Holding one doesn't move the other.
OpenLedger and Story Protocol are those two rails, built by different teams with different objectives, being presented as a unified solution.
Here's what I find harder to dismiss. Enterprise clients who need AI compliance infrastructure care deeply about legal certainty. They want to know that the data in a model is licensed correctly, that usage creates trackable obligations, and that disputes have resolution pathways. Story Protocol addresses that need directly. Attribution rewards address a different need, economic participation for contributors, through a mechanism that's probabilistic and inference-pattern-dependent, which is not what legal teams mean when they ask for certainty.
The partnership probably works well for contributors who want both legal protection and economic participation simultaneously. It might create friction for enterprises that want legal certainty but find attribution scoring too variable to build compliance workflows around. Those are different buyer profiles with different requirements, and the same infrastructure architecture doesn't serve both equally.
What I watch for is specific: whether there's a defined protocol for cases where IP ownership claims conflict with attribution weight calculations, whether Story Protocol licensing terms are reflected directly in DataNet reward splits or treated as a separate legal layer that sits above the attribution system, and whether enterprise deployments using both systems have clear documentation about which framework governs when the two produce different answers.
That last question hasn't come up publicly yet. It probably will. And when it does, the answer will say more about what these two systems actually built together than the partnership announcement did.