
#Neuraxon Accademia dell'Intelligenza — Volume 10
Dal Team Scientifico Qubic

Se costruiamo un sistema artificiale e vogliamo sapere se è intelligente, cosa misuriamo esattamente? Pensiamo di saperlo quando sentiamo che ChatGPT-5 annuncia di aver battuto DeepSeek e poi che Claude fa il colpo di scena su Gemini.
Ma la domanda è ancora lì, intatta. Misurare l'intelligenza artificiale non è misurare la velocità o la temperatura. Non abbiamo una unità di misura, per quanto strano possa sembrare.
In psicologia ci stiamo occupando di questo problema da oltre un secolo. L'intelligenza artificiale ci sta lavorando da un decennio. E lo fa in fretta, con molti soldi in gioco e con una costante tentazione: dichiarare vittoria.
Il Fattore g: Un Unico Numero per Riassumere l'Intelligenza Generale
All'inizio del XX secolo, Charles Spearman si rese conto che quando un bambino si esibiva bene in una materia, tendeva a esibirsi bene anche nelle altre, anche se erano materie senza apparente relazione. I punteggi correlevano tra loro, tutti positivamente. Chiamò quel modello il manifold positivo, e dedusse che doveva esserci un fattore latente comune dietro tutte quelle abilità disparate: il fattore g, o intelligenza generale (Spearman, 1904).
L'idea è seducente. Se tutti i test cognitivi caricano su un singolo fattore, basta estrarre quel fattore tramite l'analisi dei fattori per avere una misura riassuntiva della capacità generale. Nella pratica umana, quel primo fattore spiega solitamente tra il 40 e il 50% della varianza nelle prestazioni (Detterman & Daniel, 1989; Deary et al., 2009).
Ma attenzione, perché qui si trova la prima trappola. Il fattore g è popolazionale. Non misura l'individuo, ma la varianza tra gli individui (Hernández-Orallo et al., 2021). Dire che un soggetto specifico ha tanto g è, strettamente parlando, un errore. g emerge quando si confrontano molti soggetti, non quando si esamina uno. Come la personalità, sei il più estroverso del tuo gruppo di età. E lo rimani a 50 rispetto al tuo gruppo, anche se in intensità sei meno estroverso rispetto a 20.
Cosa misura realmente l'IQ? Comprendere i punteggi di intelligenza
Ma allora, cosa misura realmente l'IQ?
Misura una posizione relativa. La scala è calibrata su un campione con media 100, deviazione standard 15. Un IQ di 130 non è una quantità assoluta di intelligenza immagazzinata nella testa di qualcuno; è l'affermazione che questa persona è due deviazioni standard sopra la media del suo gruppo normativo. Il numero è attaccato all'individuo, sì, ma il suo significato è popolazionale. È una posizione in una classifica, non un contenuto.
La tua altezza è assoluta: sei alto 180 centimetri anche se sei l'ultimo essere umano sulla Terra. Il tuo IQ non è: essere sopra la media richiede una media, e una media richiede altri. Nessuno può essere più intelligente della media su un'isola deserta.
Ora si capisce perché trasferire questo nell'AI è così delicato. Quando qualcuno calcola un g per un insieme di grandi modelli di linguaggio (LLM), quel fattore è un artefatto dell'insieme che ha scelto. Stiamo misurando una posizione in una tabella, e la presentiamo come se fosse una proprietà interna del sistema.
Applicare il fattore g all'Intelligenza Artificiale: una tentazione pericolosa
La tentazione di trasferire tutto questo nell'AI era irresistibile. Gignac e Szodorai hanno proposto che, se le prestazioni dei modelli in vari compiti correlano positivamente, dovrebbe essere possibile identificare un fattore generale di capacità anche nei sistemi artificiali. E infatti, diversi lavori recenti applicano l'analisi dei fattori a batterie di test negli LLM e trovano un fattore g unidimensionale che rimane stabile attraverso modelli, batterie e metodi di estrazione (Ilić, 2023). Sembra una conferma. È saggio essere sospettosi.
L'apparizione di un fattore primo dominante non prova che esista una capacità generale analoga a quella umana. Prova che i punteggi di quei modelli covariano. E covariano per una ragione molto superficiale: condividono architettura, condividono corpus di addestramento, condividono ricette di ottimizzazione. Un modello grande e ben addestrato fa tutto meglio di uno piccolo e mal addestrato, in tutti i compiti contemporaneamente. Questo è sufficiente per fabbricare un bellissimo manifold positivo che non ci dice nulla sulla generalità cognitiva. Ci dice qualcosa sulla scala di calcolo. ATTENZIONE: il fattore che estraiamo potrebbe semplicemente essere un fattore di grandezza mascherato da intelligenza.
Il cervello, inoltre, non concentra l'intelligenza in un singolo modulo. Una moltitudine di sottosistemi specializzati elabora in parallelo e, quando un'informazione vince la competizione, diventa globalmente disponibile per il resto del sistema, che può quindi rielaborarla per nuovi scopi (Baars, 1988; Dehaene & Changeux, 2011). Ciò che chiamiamo generalità è disponibilità globale: mettere a servizio un pezzo appreso in un contesto per un problema in un altro. Non è un numero scalare memorizzato; è un modello di accesso e integrazione. Questo è il tipo di architettura funzionale che Neuraxon cerca di emulare — sottosistemi modulari con dinamiche di tempo continuo e plasticità multi-temporale, piuttosto che un trasformatore monolitico.
François Chollet e l'Approccio Moderno: Misurare ciò che ancora non sai come fare
Contro l'eredità psicometrica, François Chollet ha proposto nel 2019 un cambio concettuale. Il suo argomento, in Sulla Misura dell'Intelligenza, è che stavamo misurando la cosa sbagliata.
I benchmark AI tradizionali premiano abilità, competenze specifiche in compiti concreti. Ma un'abilità può essere acquistata con dati e calcoli: basta addestrarsi sufficientemente su un compito per dominarlo. L'intelligenza, sostiene Chollet, non è abilità, ma efficienza nell'acquisizione delle abilità: quanto impari da quanto poco, quando affronti un compito genuinamente nuovo (Chollet, 2019).
L'intelligenza è ciò che fai quando non sai cosa fare.
Questa distinzione cambia tutto. Un sistema che risolve un milione di problemi perché ha visto dieci milioni di casi simili non è intelligente. Un sistema intelligente è quello che, di fronte a un problema per il quale non poteva prepararsi, scopre la struttura e si adatta con pochi esempi. La misura smette di essere il risultato finale e diventa la pendenza dell'apprendimento.
ARC-AGI: Il Benchmark che Testa il Vero Ragionamento AI
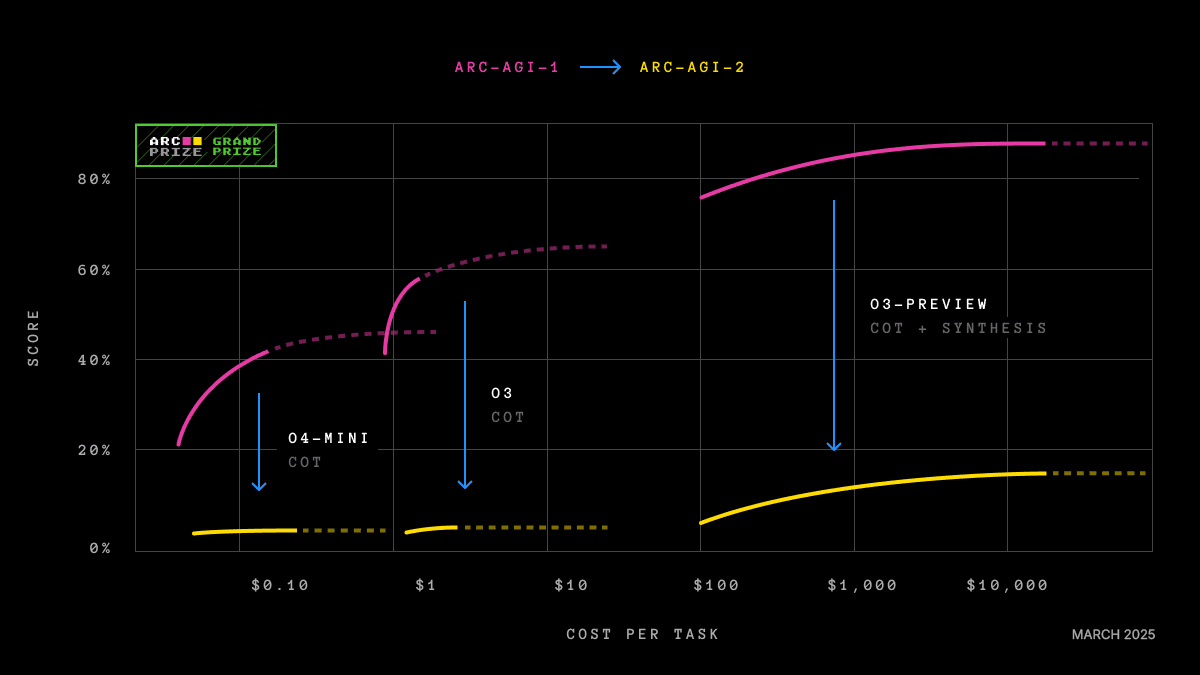
ARC-AGI è nato da quell'idea, e la sua versione più recente, ARC-AGI-3, porta avanti il concetto. Non è un test di domande e risposte. È un insieme di ambienti interattivi, come mini-videogiochi, in cui l'agente esplora un mondo sconosciuto, deduce qual è l'obiettivo senza che gli venga detto in linguaggio naturale, costruisce un modello dell'ambiente e adatta la sua strategia passo dopo passo (ARC Prize, 2025).
I principi di design sono espliciti: ambienti 100% risolvibili dagli esseri umani, senza conoscenze precaricate o istruzioni nascoste, e con abbastanza novità da prevenire la memorizzazione. Ciò che viene valutato non è ottenere il risultato giusto, ma l'efficienza nell'acquisizione delle abilità nel tempo.
È l'opposto del fattore g: invece di cercare ciò che un sistema già padroneggia e riassumerlo, cerca ciò che ancora non sa fare e misura quanto gli costa impararlo.
Contaminazione dei Dati: Perché i Punteggi dei Benchmark LLM Sono Gonfiati
La ragione ultima per cui l'approccio di Chollet è importante, e perché il fattore g applicato agli LLM è così scivoloso, ha un nome tecnico: contaminazione dei dati. Se l'esame, o qualcosa di quasi identico, era nelle note che lo studente ha studiato, il loro voto non misura ciò che possono ragionare. Misura ciò che hanno memorizzato.
I modelli di linguaggio sono addestrati su libri, forum, repository di codice, articoli, praticamente tutto il testo disponibile. I benchmark con cui li valutiamo vengono pubblicati su internet. La conclusione è che frammenti dei test finiscono all'interno dei dati di addestramento, il che viola la separazione tra addestramento e valutazione e gonfia i punteggi (Xu et al., 2024; Deng et al., 2024). Audit empirici hanno rilevato livelli di contaminazione che vanno dall'1% fino al 45% nei benchmark ampiamente utilizzati, e il problema cresce nel tempo (Li et al., 2024).
Non è un problema da poco di un paio di domande trapelate. Nei benchmark citati come MMLU o GSM8K, parte di ciò che interpretiamo come ragionamento può essere pura memorizzazione (Chen et al., 2025). Quando vengono applicate tecniche di decontaminazione che riscrivono gli elementi trapelati senza alterarne la difficoltà, l'accuratezza cala: in uno studio, 22,9% su GSM8K e 19,0% su MMLU (Zhu et al., 2024).
Elementi parafrasati, o anche quelli tradotti in un'altra lingua, evitano i rilevatori di sovrapposizione superficiale e continuano a gonfiare i risultati (Yang et al., 2023; Yao et al., 2024). Le soluzioni abituali (parafrasare, tradurre, modificare il contesto) si presume siano efficaci senza essere state validate rigorosamente. E per la maggior parte dei modelli aperti non possiamo nemmeno controllare nulla, perché i loro dati di addestramento non sono pubblicati. Stiamo valutando esami senza sapere cosa ha studiato lo studente.
Qui si capisce perché ARC-AGI abbia scelto il percorso che ha scelto. Un ambiente interattivo e innovativo, senza istruzioni in linguaggio naturale e progettato per prevenire la memorizzazione forzata è, per costruzione, resistente alla contaminazione.
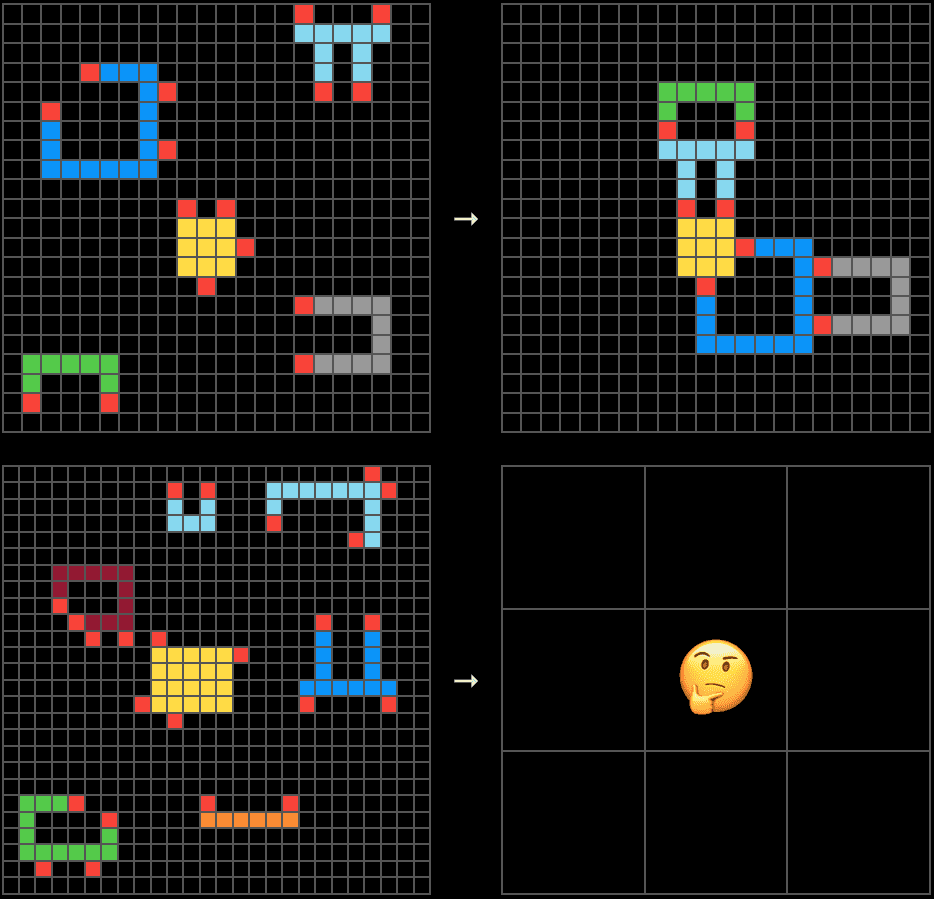
Quindi, cosa dovremmo misurare per valutare l'intelligenza delle macchine?
Il fattore g è una proprietà popolazionale che, applicata a modelli che condividono architettura e corpus, corre il rischio di misurare la scala di calcolo e non la generalità. La lezione per chi costruisce sistemi artificiali non è scegliere tra il fattore g e ARC-AGI come se fossero squadre rivali. È capire quale domanda ciascuno risponde. Un'analisi dei fattori può essere utile per descrivere la struttura interna delle prestazioni di un sistema, finché il primo fattore non viene confuso con un'essenza dell'intelligenza. E un protocollo di tipo ARC è indispensabile per ciò che conta davvero: verificare se il sistema generalizza oltre ciò che ha visto, o semplicemente recita.
Quando valutiamo un sistema solo in base alla sua risposta finale, lo stiamo misurando con gli occhi chiusi alla sua dimensione temporale: pianificazione, aggiornamento delle credenze, integrazione delle evidenze attraverso molti passaggi. È esattamente ciò che ARC-AGI-3 ha deciso di valutare, e esattamente ciò che un esame statico non può vedere.

Perché le architetture AI ispirate al cervello come Neuraxon seguono un percorso diverso
Se l'intelligenza non è un numero memorizzato ma l'integrazione efficiente di sottosistemi specializzati, come suggerito dalla teoria dell'integrazione parieto-frontal (P-FIT) e dalla disponibilità globale del workspace nel cervello…
Se quell'integrazione è prima di tutto un fenomeno temporale, con scale temporali…
Quindi, un sistema costruito su architetture modulari con sfere funzionali, plasticità su più scale temporali e dinamiche continue non ha bisogno di essere valutato chiedendogli di recitare risposte.
La domanda corretta non è quante benchmark supera, ma con quale efficienza acquisisce nuovi comportamenti, nel tempo, in ambienti per i quali non era preparato. Questa è la direzione che Neuraxon cerca di prendere. Calcolare il tempo – cioè, adattamento – non risposte memorizzate che simulano di essere un buon studente, quando in realtà sa già le domande.
Riferimenti
Chollet, F. (2019). Sulla Misura dell'Intelligenza. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). Le neuroscienze delle differenze di intelligenza umana. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Approcci sperimentali e teorici al processamento consapevole. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Correlazioni dei test mentali tra loro e con variabili cognitive. Intelligenza.
Gignac, G. E., & Szodorai, E. T. (2024). Definire e identificare un fattore generale di abilità nei sistemi AI.
Guttman, L. (1955). La determinazione delle matrici di punteggio dei fattori con implicazioni per altri cinque problemi fondamentali della teoria dei fattori comuni. British Journal of Statistical Psychology.
Hernández-Orallo, J., et al. (2021). Intelligenza generale disambiguata tramite una metrica di generalità per intelligenza naturale e artificiale. Scientific Reports.
Honey, C. J., et al. (2012). Dinamiche corticali lente e accumulo di informazioni su ampie scale temporali. Neuron, 76(2), 423–434.
Ilić, D. (2023). Svelare il Fattore di Intelligenza Generale nei Modelli di Linguaggio: Un Approccio Psicometrico. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). La Teoria dell'Integrazione Parieto-Frontal (P-FIT) dell'intelligenza. Behavioral and Brain Sciences.
Spearman, C. (1904). "L'intelligenza generale" determinata e misurata oggettivamente. American Journal of Psychology, 15, 201–293.
Roberts, M., et al. (2024). Evidenze temporali di contaminazione da date di interruzione dell'addestramento.
Schönemann, P. H. (2008). Una Risposta a Mackintosh e alcune Osservazioni sul Concetto di Intelligenza Generale. arXiv:0808.2343.
Xu, C., et al. (2024). Contaminazione dei dati di benchmark dei grandi modelli di linguaggio: un'indagine.
Yang, S., et al. (2023). Ripensare benchmark e contaminazione per modelli di linguaggio con campioni riformulati.
Zhu, Q., et al. (2024). Decontaminazione al momento dell'inferenza: riutilizzare benchmark trapelati per la valutazione degli LLM. Risultati di EMNLP 2024.
ARC Prize (2025). ARC-AGI-3: Un benchmark di ragionamento interattivo. Rapporto Tecnico.
Esplora l'intera serie dell'Academy di Intelligenza Neuraxon
Questo è il Volume 10 dell'Academy di Intelligenza Neuraxon del Qubic Scientific Team. Se ti unisci a noi ora, esplora l'intera serie per costruire una comprensione completa della scienza dietro Neuraxon, Aigarth e l'approccio di Qubic all'intelligenza artificiale decentralizzata e ispirata al cervello:
NIA Volume 1: Perché l'Intelligenza non è Calcolata in Passi, ma nel Tempo — Esplora perché l'intelligenza biologica opera in tempo continuo piuttosto che in passi computazionali discreti come i tradizionali LLM.
NIA Volume 2: Dinamiche Terziarie come Modello di Intelligenza Vivente — Spiega le dinamiche ternarie e perché la logica a tre stati (eccitatoria, neutrale, inibitoria) è importante per modellare i sistemi viventi.
NIA Volume 3: Neuromodulazione e AI Ispirata al Cervello — Copre la neuromodulazione e come la segnalazione chimica del cervello (dopamina, serotonina, acetilcolina, norepinefrina) ispira l'architettura di Neuraxon.
NIA Volume 4: Reti Neurali in AI e Neuroscienze — Un confronto approfondito tra reti neurali biologiche, reti neurali artificiali e l'approccio della terza via di Neuraxon.
NIA Volume 5: Astrociti e AI Ispirata al Cervello — Come il gating astrocitario trasforma la plasticità della rete neurale attraverso il framework AGMP in Neuraxon.
NIA Volume 6: Macchine Consapevoli vs Organismi Intelligenti: L'Intelligenza Artificiale Spiegata — Esplora la coscienza AI attraverso la lente della Teoria del Workspace Globale, della Teoria dell'Informazione Integrata e del coding predittivo.
NIA Volume 7: Il Gioco della Vita di Conway, Vita Artificiale e Ecosistemi Digitali — La scienza dietro Qubic, Aigarth e la complessità emergente di Neuraxon e la criticità auto-organizzata.
NIA Volume 8: Criticità Cerebrale e il Rapporto di Ramificazione in Reti Neurali e Artificiali — Perché un rapporto di ramificazione vicino a 1 e la criticità auto-organizzata sono principi di design ispirati alla biologia in Neuraxon.
NIA Volume 9: Le Origini del Fattore g: Dall'Istruzione e Neuroscienza all'Intelligenza Artificiale — Esplora le origini del fattore g attraverso educazione, neuroscienze e AI.
$Qubic è una rete decentralizzata e open-source per tecnologia sperimentale. Per saperne di più, visita qubic.org. Unisciti alla discussione su X, Discord e Telegram.