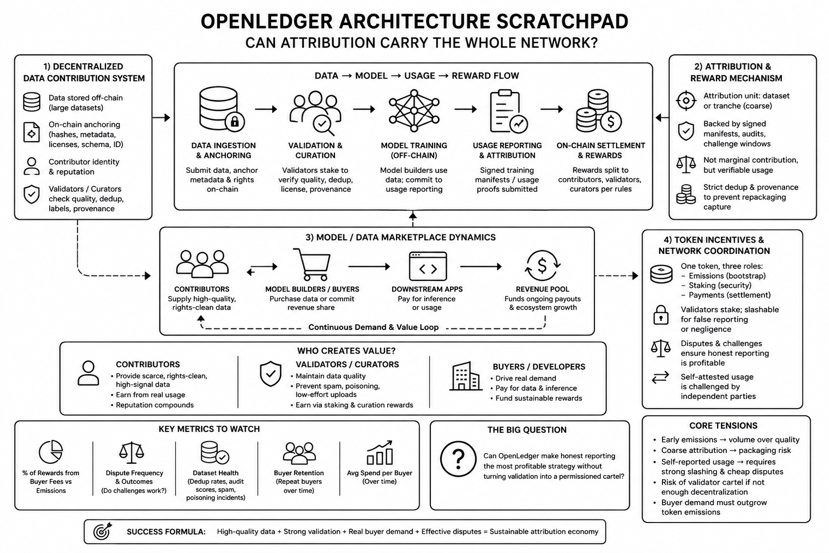
Been going through openledger’s architecture notes and honestly i’m less interested in the “decentralized data storage” pitch than in the way they’re trying to formalize attribution. what caught my attention is that openledger seems to treat attribution as the core primitive: data comes in, models consume it, usage gets recorded, and then payouts can be coordinated on-chain without a single platform acting as the accountant. that’s the thesis, anyway. i’m still trying to figure out how many assumptions are hiding under that flow.
most people think openledger is just another ai + crypto token where contributors upload datasets and farm rewards. that narrative is probably oversimplified, but it’s not completely unfair either—if the protocol can’t create buyer-side demand and enforceable usage reporting, it’ll look exactly like that from the outside.
the pieces that feel most “structural” to me:
1) decentralized data contribution system
the likely shape is familiar: large data sits off-chain; on-chain you anchor hashes, metadata, licenses, maybe a schema id, and some contributor identity/reputation signal. the real issue is ingestion quality. a network can’t be permissionless and also assume the data is clean. so you end up needing validators/curators doing dedup, sampling, label checks, and license/provenance sanity. openledger can decentralize that work with staking + rewards, but then you’re building a parallel ecosystem of “data QA operators,” and the best-funded ones tend to dominate.
2) attribution + reward mechanism
and this is the part i keep thinking about, because “pay people when their data trains a model” sounds clean until you ask what’s provable. training is off-chain, datasets get mixed, filtered, and transformed, and model builders may not want to reveal their full recipe. so attribution probably ends up being coarse: dataset-level or tranche-level usage claims, maybe backed by signed training manifests, audits, or challenge windows. that can still be useful, but it’s not the same as measuring marginal contribution. also, if the accounting unit is “dataset,” whoever packages and re-packages datasets can capture outsized rewards unless dedup/provenance is very strict.
3) model/data marketplace dynamics
openledger seems to want a loop: contributors supply data, model builders buy it (or commit to revenue share), and downstream apps pay for inference, which funds ongoing payouts. a realistic example: a small legal-tech team wants a retrieval + summarization model tuned on jurisdiction-specific contracts. they need annotated clauses and permissions, not random web text. today they’d either pay a centralized vendor and trust the paperwork, or scrape and take risk. openledger’s pitch is: traceable provenance + programmable payout splits. that’s meaningful if buyers trust it enough to run production workloads through it.
4) token incentives + network coordination / verification
the token looks like it’s doing three jobs at once: bootstrap supply (emissions), secure validation (staking/slashing), and settle marketplace payments. i’m slightly skeptical of “one asset, many jobs,” mostly because it makes the network harder to reason about when demand is low. the verification layer matters here: if usage reporting is basically self-attested, then slashing needs to be real and disputes need to be cheap enough that someone actually bothers to challenge false claims. otherwise, attribution becomes a social norm rather than an enforceable mechanism.
zooming out: who actually creates value? contributors only matter if they provide scarce, rights-clean, high-signal data. validators matter if they can keep spam and poisoning from turning the data layer into a liability. and buyers matter because they’re the only path to non-emission rewards. openledger’s long-term design implicitly assumes (a) sustained demand for specialized data and (b) enough participants willing to accept on-chain settlement overhead (or at least periodic settlement). i’m not fully convinced that second part is obvious—many teams will choose “just pay a vendor” unless the protocol is noticeably cheaper or safer.
the biggest tension is incentive misalignment early on. if most payouts are emissions, you incentivize volume: duplicated corpora, low-effort labels, or even coordinated wash activity to fake “usage.” and if attribution relies on a small set of trusted auditors, you’ve basically rebuilt a centralized clearinghouse, just with more steps.
no perfect conclusion yet. i can see openledger becoming a sustainable coordination layer, but only if it graduates quickly from “token-funded growth” to “buyer-funded utility,” and if attribution doesn’t collapse under adversarial behavior.
watching:
- % of contributor rewards coming from buyer fees vs emissions
- dispute frequency + outcomes (do challenges work, or do big validators always win?)
- dataset health metrics: dedup rates, label audit scores, poisoning/spam incidents
- repeat buyer retention and average spend per buyer over time
the question i’m left with: can openledger make honest reporting the most profitable strategy without turning validation into a permissioned cartel?