Author: 0xjacobzhao | https://linktr.ee/0xjacobzhao
This independent research report is supported by IOSG Ventures. The research and writing process was inspired by Sam Lehman (Pantera Capital) ’s work on reinforcement learning. Thanks to Ben Fielding (Gensyn.ai), Gao Yuan(Gradient), Samuel Dare & Erfan Miahi (Covenant AI), Shashank Yadav (Fraction AI), Chao Wang for their valuable suggestions on this article. This article strives for objectivity and accuracy, but some viewpoints involve subjective judgment and may contain biases. We appreciate the readers' understanding.
Artificial intelligence is shifting from pattern-based statistical learning toward structured reasoning systems, with post-training—especially reinforcement learning—becoming central to capability scaling. DeepSeek-R1 signals a paradigm shift: reinforcement learning now demonstrably improves reasoning depth and complex decision-making, evolving from a mere alignment tool into a continuous intelligence-enhancement pathway.
In parallel, Web3 is reshaping AI production via decentralized compute and crypto incentives, whose verifiability and coordination align naturally with reinforcement learning’s needs. This report examines AI training paradigms and reinforcement learning fundamentals, highlights the structural advantages of “Reinforcement Learning × Web3,” and analyzes Prime Intellect, Gensyn, Nous Research, Gradient, Grail and Fraction AI.
I. Three Stages of AI Training
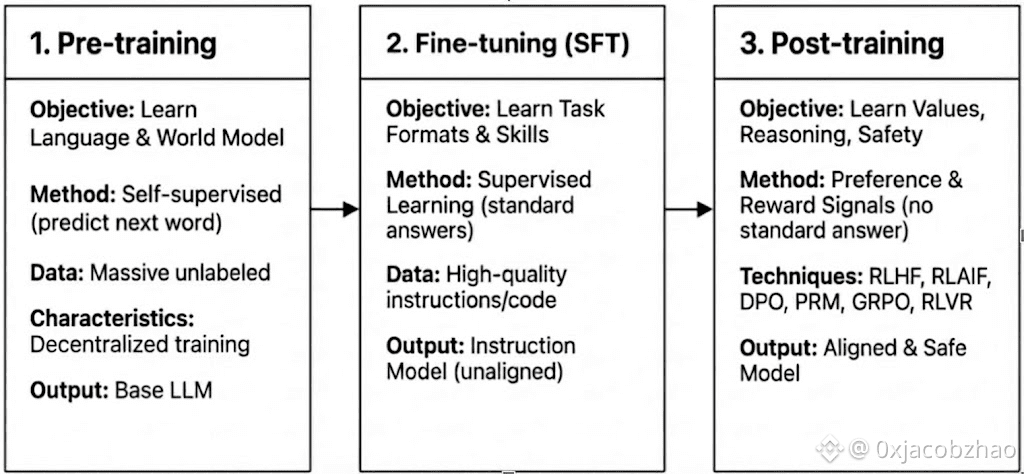
Modern LLM training spans three stages—pre-training, supervised fine-tuning (SFT), and post-training/reinforcement learning—corresponding to building a world model, injecting task capabilities, and shaping reasoning and values. Their computational and verification characteristics determine how compatible they are with decentralization.
Pre-training: establishes the core statistical and multimodal foundations via massive self-supervised learning, consuming 80–95% of total cost and requiring tightly synchronized, homogeneous GPU clusters and high-bandwidth data access, making it inherently centralized.
Supervised Fine-tuning (SFT): adds task and instruction capabilities with smaller datasets and lower cost (5–15%), often using PEFT methods such as LoRA or Q-LoRA, but still depends on gradient synchronization, limiting decentralization.
Post-training: Post-training consists of multiple iterative stages that shape a model’s reasoning ability, values, and safety boundaries. It includes both RL-based approaches (e.g. RLHF, RLAIF, GRPO), non-RL preference optimization (e.g. DPO), and process reward models (PRM). With lower data and cost requirements (around 5–10%), computation focuses on rollouts and policy updates. Its native support for asynchronous, distributed execution—often without requiring full model weights—makes post-training the phase best suited for Web3-based decentralized training networks when combined with verifiable computation and on-chain incentives.
II. Reinforcement Learning Technology Landscape
2.1 System Architecture of Reinforcement Learning
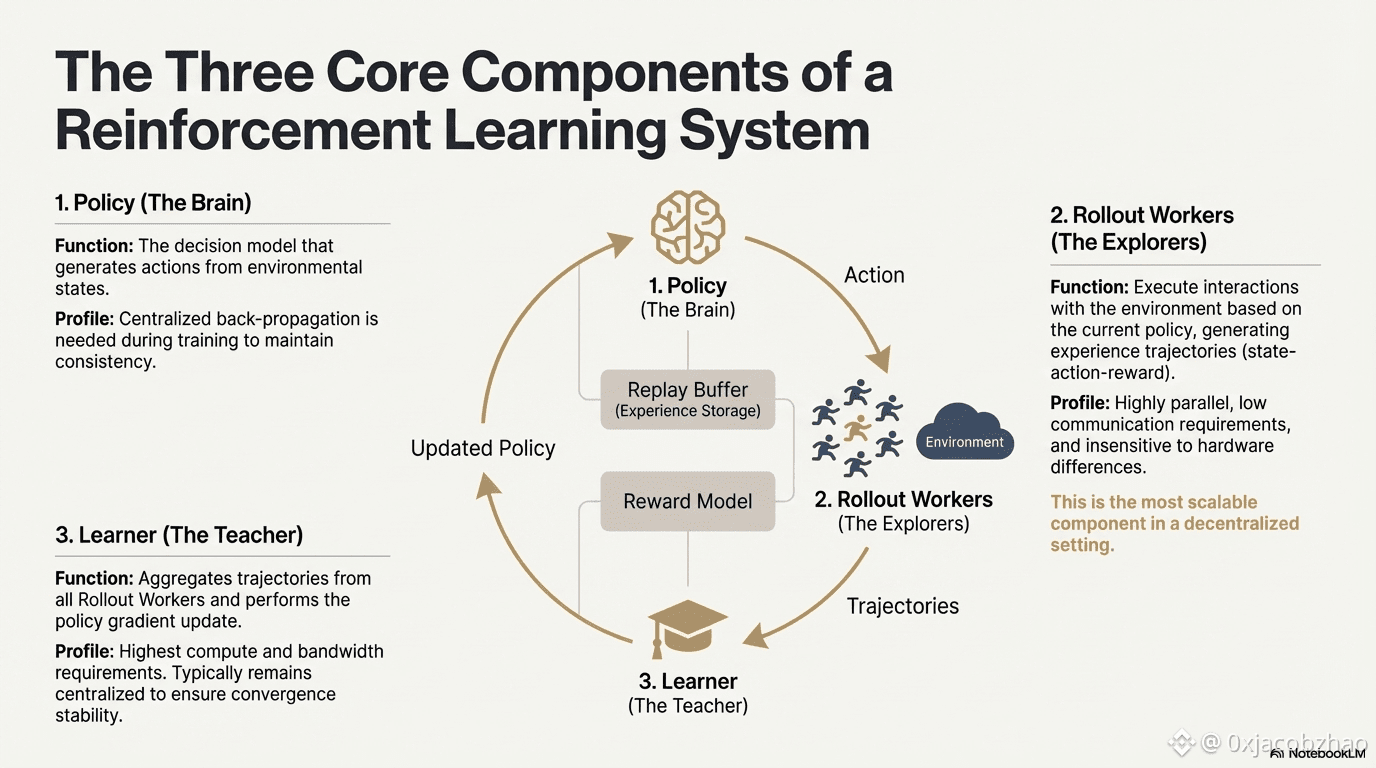
Reinforcement learning enables models to improve decision-making through a feedback loop of environment interaction, reward signals, and policy updates. Structurally, an RL system consists of three core components: the policy network, rollout for experience sampling, and the learner for policy optimization. The policy generates trajectories through interaction with the environment, while the learner updates the policy based on rewards, forming a continuous iterative learning process.
Policy Network (Policy): Generates actions from environmental states and is the decision-making core of the system. It requires centralized backpropagation to maintain consistency during training; during inference, it can be distributed to different nodes for parallel operation.
Experience Sampling (Rollout): Nodes execute environment interactions based on the policy, generating state-action-reward trajectories. This process is highly parallel, has extremely low communication, is insensitive to hardware differences, and is the most suitable component for expansion in decentralization.
Learner: Aggregates all Rollout trajectories and executes policy gradient updates. It is the only module with the highest requirements for computing power and bandwidth, so it is usually kept centralized or lightly centralized to ensure convergence stability.
2.2 Reinforcement Learning Stage Framework
Reinforcement learning can usually be divided into five stages, and the overall process as follows:
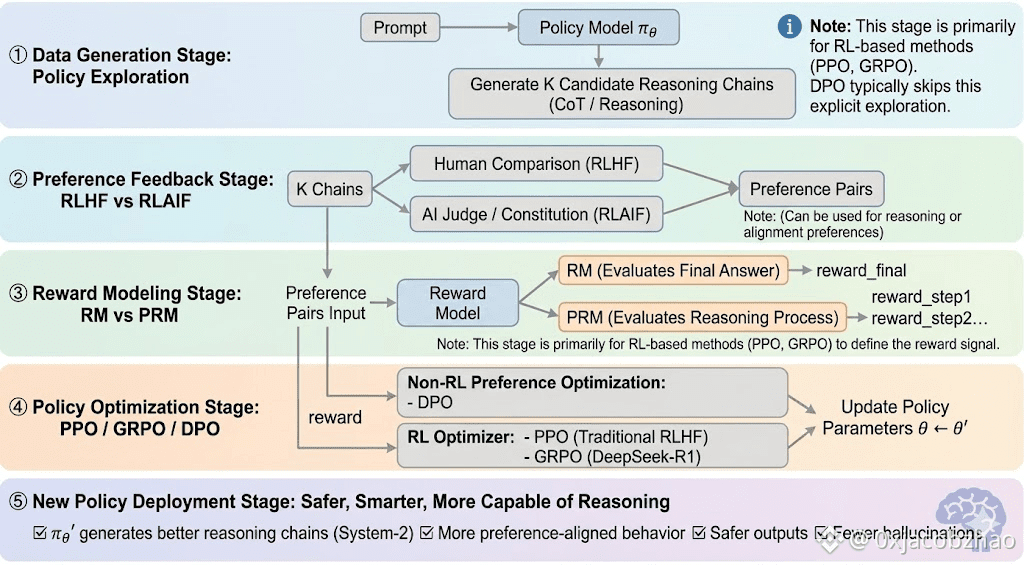
Data Generation Stage (Policy Exploration): Given a prompt, the policy samples multiple reasoning chains or trajectories, supplying the candidates for preference evaluation and reward modeling and defining the scope of policy exploration.
Preference Feedback Stage (RLHF / RLAIF):
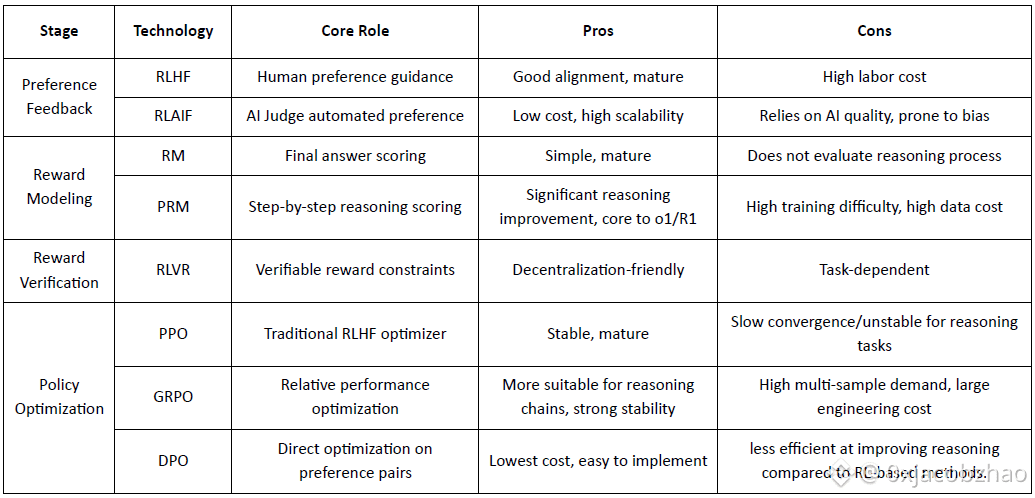
RLHF (Reinforcement Learning from Human Feedback): trains a reward model from human preferences and then uses RL (typically PPO) to optimize the policy based on that reward signal.
RLAIF (Reinforcement Learning from AI Feedback): replaces humans with AI judges or constitutional rules, cutting costs and scaling alignment—now the dominant approach for Anthropic, OpenAI, and DeepSeek.
Reward Modeling Stage (Reward Modeling): Learns to map outputs to rewards based on preference pairs. RM teaches the model "what is the correct answer," while PRM teaches the model "how to reason correctly."
RM (Reward Model): Used to evaluate the quality of the final answer, scoring only the output.
Process Reward Model (PRM): scores step-by-step reasoning, effectively training the model’s reasoning process (e.g., in o1 and DeepSeek-R1).
Reward Verification (RLVR / Reward Verifiability): A reward-verification layer constrains reward signals to be derived from reproducible rules, ground-truth facts, or consensus mechanisms. This reduces reward hacking and systemic bias, and improves auditability and robustness in open and distributed training environments.
Policy Optimization Stage (Policy Optimization): Updates policy parameters $\theta$ under the guidance of signals given by the reward model to obtain a policy $\pi_{\theta'}$ with stronger reasoning capabilities, higher safety, and more stable behavioral patterns. Mainstream optimization methods include:
PPO (Proximal Policy Optimization): the standard RLHF optimizer, valued for stability but limited by slow convergence in complex reasoning.
GRPO (Group Relative Policy Optimization): introduced by DeepSeek-R1, optimizes policies using group-level advantage estimates rather than simple ranking, preserving value magnitude and enabling more stable reasoning-chain optimization.
DPO (Direct Preference Optimization): bypasses RL by optimizing directly on preference pairs—cheap and stable for alignment, but ineffective at improving reasoning.
New Policy Deployment Stage (New Policy Deployment): the updated model shows stronger System-2 reasoning, better preference alignment, fewer hallucinations, and higher safety, and continues to improve through iterative feedback loops.
2.3 Industrial Applications of Reinforcement Learning
Reinforcement Learning (RL) has evolved from early game intelligence to a core framework for cross-industry autonomous decision-making. Its application scenarios, based on technological maturity and industrial implementation, can be summarized into five major categories:
Game & Strategy: The earliest direction where RL was verified. In environments with "perfect information + clear rewards" like AlphaGo, AlphaZero, AlphaStar, and OpenAI Five, RL demonstrated decision intelligence comparable to or surpassing human experts, laying the foundation for modern RL algorithms.
Robotics & Embodied AI: Through continuous control, dynamics modeling, and environmental interaction, RL enables robots to learn manipulation, motion control, and cross-modal tasks (e.g., RT-2, RT-X). It is rapidly moving towards industrialization and is a key technical route for real-world robot deployment.
Digital Reasoning / LLM System-2: RL + PRM drives large models from "language imitation" to "structured reasoning." Representative achievements include DeepSeek-R1, OpenAI o1/o3, Anthropic Claude, and AlphaGeometry. Essentially, it performs reward optimization at the reasoning chain level rather than just evaluating the final answer.
Scientific Discovery & Math Optimization: RL finds optimal structures or strategies in label-free, complex reward, and huge search spaces. It has achieved foundational breakthroughs in AlphaTensor, AlphaDev, and Fusion RL, showing exploration capabilities beyond human intuition.
Economic Decision-making & Trading: RL is used for strategy optimization, high-dimensional risk control, and adaptive trading system generation. Compared to traditional quantitative models, it can learn continuously in uncertain environments and is an important component of intelligent finance.
III. Natural Match Between Reinforcement Learning and Web3
Reinforcement learning and Web3 are naturally aligned as incentive-driven systems: RL optimizes behavior through rewards, while blockchains coordinate participants through economic incentives. RL’s core needs—large-scale heterogeneous rollouts, reward distribution, and verifiable execution—map directly onto Web3’s structural strengths.
Decoupling of Reasoning and Training: Reinforcement learning separates into rollout and update phases: rollouts are compute-heavy but communication-light and can run in parallel on distributed consumer GPUs, while updates require centralized, high-bandwidth resources. This decoupling lets open networks handle rollouts with token incentives, while centralized updates maintain training stability.
Verifiability: ZK (Zero-Knowledge) and Proof-of-Learning provide means to verify whether nodes truly executed reasoning, solving the honesty problem in open networks. In deterministic tasks like code and mathematical reasoning, verifiers only need to check the answer to confirm the workload, significantly improving the credibility of decentralized RL systems.
Incentive Layer, Token Economy-Based Feedback Production Mechanism: Web3 token incentives can directly reward RLHF/RLAIF feedback contributors, enabling transparent, permissionless preference generation, with staking and slashing enforcing quality more efficiently than traditional crowdsourcing.
Potential for Multi-Agent Reinforcement Learning (MARL): Blockchains form open, incentive-driven multi-agent environments with public state, verifiable execution, and programmable incentives, making them a natural testbed for large-scale MARL despite the field still being early.
IV. Analysis of Web3 + Reinforcement Learning Projects
Based on the above theoretical framework, we will briefly analyze the most representative projects in the current ecosystem:
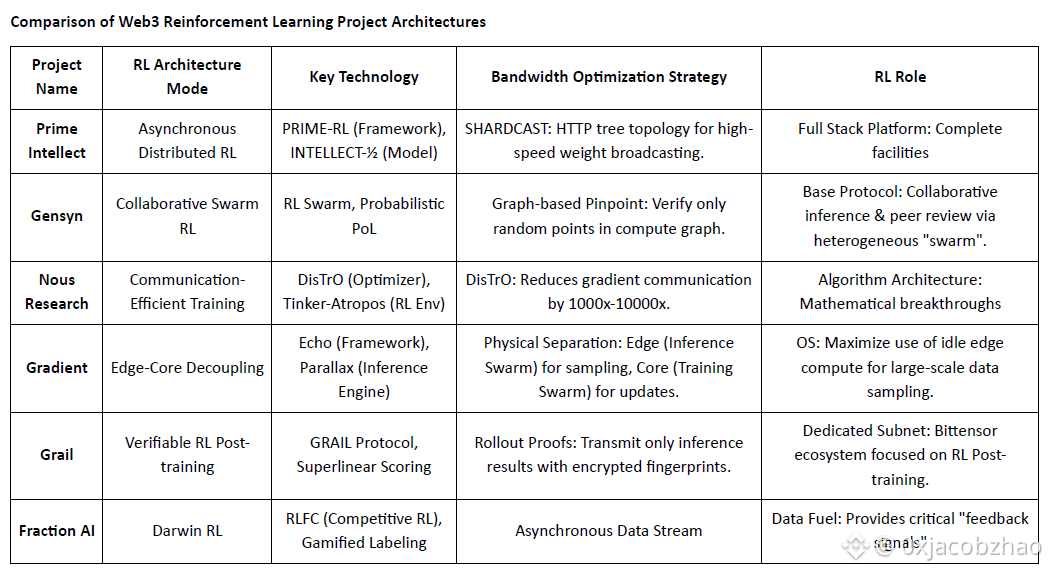
Prime Intellect: Asynchronous Reinforcement Learning prime-rl
Prime Intellect aims to build an open global compute market and open-source superintelligence stack, spanning Prime Compute, the INTELLECT model family, open RL environments, and large-scale synthetic data engines. Its core prime-rl framework is purpose-built for asynchronous distributed RL, complemented by OpenDiLoCo for bandwidth-efficient training and TopLoc for verification.
Prime Intellect Core Infrastructure Components Overview
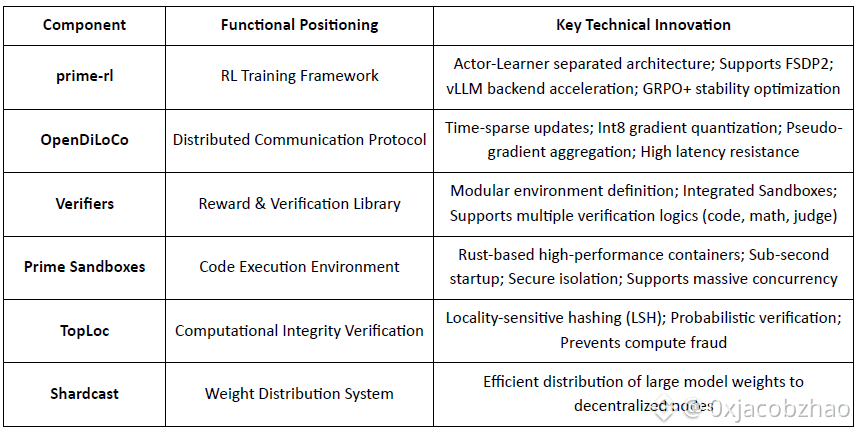
Technical Cornerstone: prime-rl Asynchronous Reinforcement Learning Framework
prime-rl is Prime Intellect's core training engine, designed for large-scale asynchronous decentralized environments. It achieves high-throughput inference and stable updates through complete Actor–Learner decoupling. Executors (Rollout Workers) and Learners (Trainers) do not block synchronously. Nodes can join or leave at any time, only needing to continuously pull the latest policy and upload generated data:
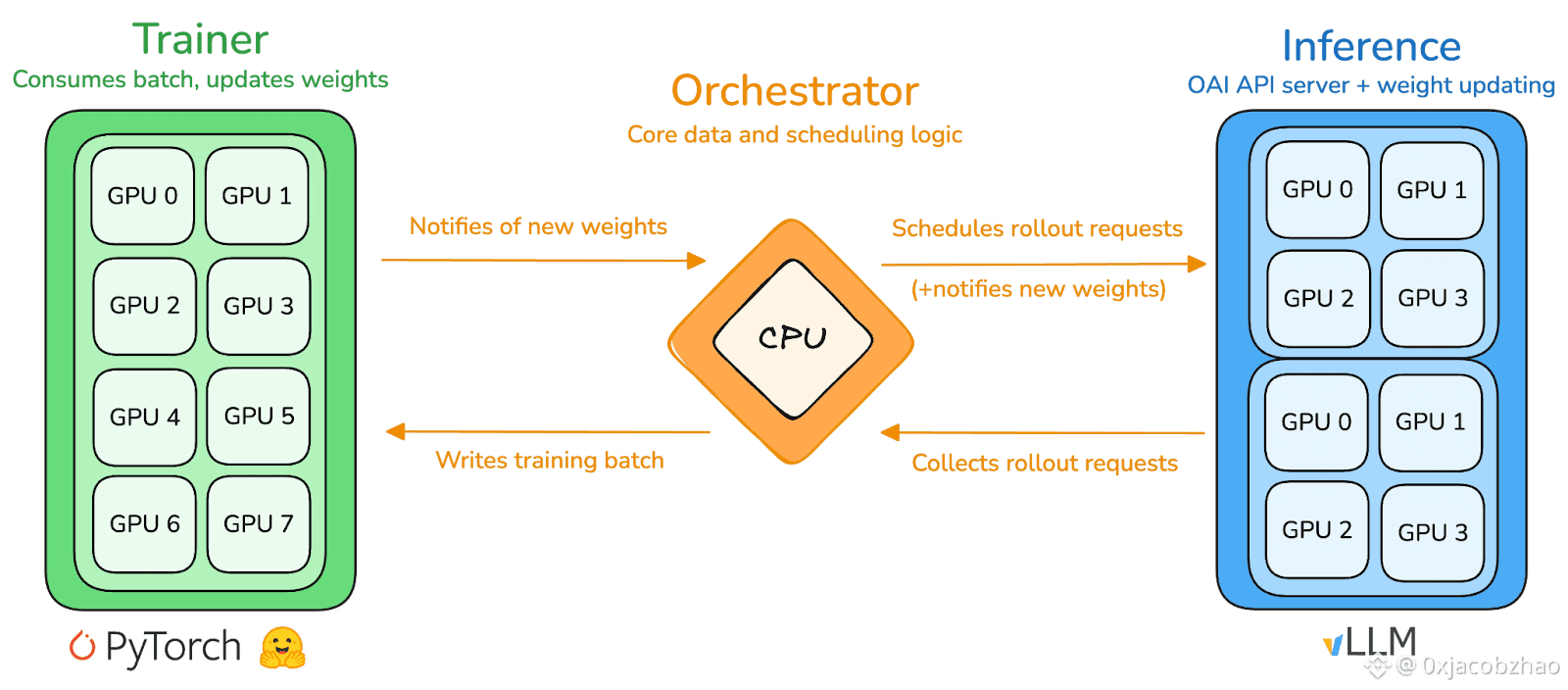
Actor (Rollout Workers): Responsible for model inference and data generation. Prime Intellect innovatively integrated the vLLM inference engine at the Actor end. vLLM's PagedAttention technology and Continuous Batching capability allow Actors to generate inference trajectories with extremely high throughput.
Learner (Trainer): Responsible for policy optimization. The Learner asynchronously pulls data from the shared Experience Buffer for gradient updates without waiting for all Actors to complete the current batch.
Orchestrator: Responsible for scheduling model weights and data flow.
Key Innovations of prime-rl:
True Asynchrony: prime-rl abandons the traditional synchronous paradigm of PPO, does not wait for slow nodes, and does not require batch alignment, enabling any number and performance of GPUs to access at any time, establishing the feasibility of decentralized RL.
Deep Integration of FSDP2 and MoE: Through FSDP2 parameter sharding and MoE sparse activation, prime-rl allows tens of billions of parameters models to be efficiently trained in distributed environments. Actors only run active experts, significantly reducing VRAM and inference costs.
GRPO+ (Group Relative Policy Optimization): GRPO eliminates the Critic network, significantly reducing computation and VRAM overhead, naturally adapting to asynchronous environments. prime-rl's GRPO+ ensures reliable convergence under high latency conditions through stabilization mechanisms.
INTELLECT Model Family: A Symbol of Decentralized RL Technology Maturity
INTELLECT-1 (10B, Oct 2024): Proved for the first time that OpenDiLoCo can train efficiently in a heterogeneous network across three continents (communication share < 2%, compute utilization 98%), breaking physical perceptions of cross-region training.
INTELLECT-2 (32B, Apr 2025): As the first Permissionless RL model, it validates the stable convergence capability of prime-rl and GRPO+ in multi-step latency and asynchronous environments, realizing decentralized RL with global open computing participation.
INTELLECT-3 (106B MoE, Nov 2025): Adopts a sparse architecture activating only 12B parameters, trained on 512×H200 and achieving flagship inference performance (AIME 90.8%, GPQA 74.4%, MMLU-Pro 81.9%, etc.). Overall performance approaches or surpasses centralized closed-source models far larger than itself.
Prime Intellect has built a full decentralized RL stack: OpenDiLoCo cuts cross-region training traffic by orders of magnitude while sustaining ~98% utilization across continents; TopLoc and Verifiers ensure trustworthy inference and reward data via activation fingerprints and sandboxed verification; and the SYNTHETIC data engine generates high-quality reasoning chains while enabling large models to run efficiently on consumer GPUs through pipeline parallelism. Together, these components underpin scalable data generation, verification, and inference in decentralized RL, with the INTELLECT series demonstrating that such systems can deliver world-class models in practice.
Gensyn: RL Core Stack RL Swarm and SAPO
Gensyn seeks to unify global idle compute into a trustless, scalable AI training network, combining standardized execution, P2P coordination, and on-chain task verification. Through mechanisms like RL Swarm, SAPO, and SkipPipe, it decouples generation, evaluation, and updates across heterogeneous GPUs, delivering not just compute, but verifiable intelligence.
RL Applications in the Gensyn Stack
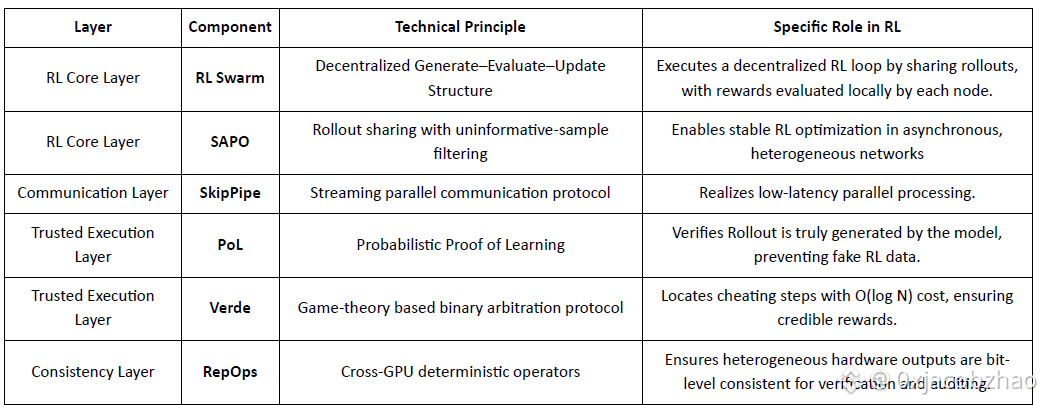
RL Swarm: Decentralized Collaborative Reinforcement Learning Engine
RL Swarm demonstrates a brand new collaboration mode. It is no longer simple task distribution, but an infinite loop of a decentralized generate–evaluate–update loop inspired by collaborative learning simulating human social learning:
Solvers (Executors): Responsible for local model inference and Rollout generation, unimpeded by node heterogeneity. Gensyn integrates high-throughput inference engines (like CodeZero) locally to output complete trajectories rather than just answers.
Proposers: Dynamically generate tasks (math problems, code questions, etc.), enabling task diversity and curriculum-like adaptation to adapt training difficulty to model capabilities.
Evaluators: Use frozen "Judge Models" or rules to check output quality, forming local reward signals evaluated independently by each node. The evaluation process can be audited, reducing room for malice.
The three form a P2P RL organizational structure that can complete large-scale collaborative learning without centralized scheduling.
SAPO: Policy Optimization Algorithm Reconstructed for Decentralization
SAPO (Swarm Sampling Policy Optimization) centers on sharing rollouts while filtering those without gradient signal, rather than sharing gradients. By enabling large-scale decentralized rollout sampling and treating received rollouts as locally generated, SAPO maintains stable convergence in environments without central coordination and with significant node latency heterogeneity. Compared to PPO (which relies on a critic network that dominates computational cost) or GRPO (which relies on group-level advantage estimation rather than simple ranking), SAPO allows consumer-grade GPUs to participate effectively in large-scale RL optimization with extremely low bandwidth requirements.
Through RL Swarm and SAPO, Gensyn demonstrates that reinforcement learning—particularly post-training RLVR—naturally fits decentralized architectures, as it depends more on diverse exploration via rollouts than on high-frequency parameter synchronization. Combined with PoL and Verde verification systems, Gensyn offers an alternative path toward training trillion-parameter models: a self-evolving superintelligence network composed of millions of heterogeneous GPUs worldwide.
Nous Research: Reinforcement Learning Environment Atropos
Nous Research is building a decentralized, self-evolving cognitive stack, where components like Hermes, Atropos, DisTrO, Psyche, and World Sim form a closed-loop intelligence system. Using RL methods such as DPO, GRPO, and rejection sampling, it replaces linear training pipelines with continuous feedback across data generation, learning, and inference.
Nous Research Components Overview
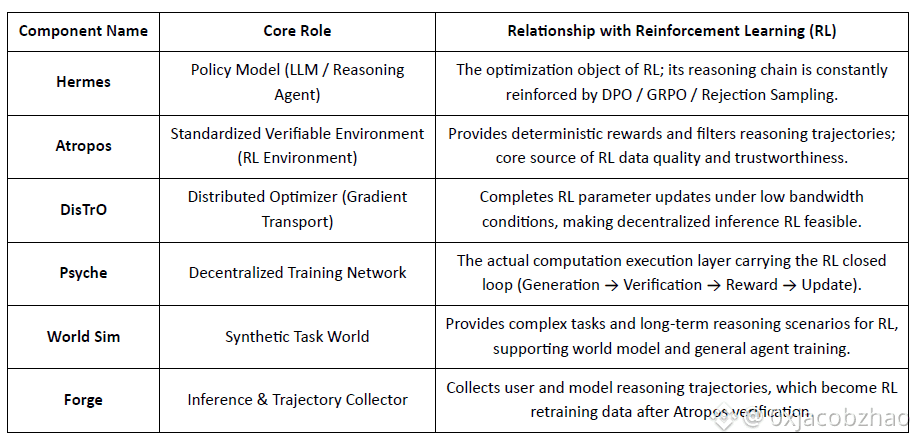
Model Layer: Hermes and the Evolution of Reasoning Capabilities
The Hermes series is the main model interface of Nous Research facing users. Its evolution clearly demonstrates the industry path migrating from traditional SFT/DPO alignment to Reasoning RL:
Hermes 1–3: Instruction Alignment & Early Agent Capabilities: Hermes 1–3 relied on low-cost DPO for robust instruction alignment and leveraged synthetic data and the first introduction of Atropos verification mechanisms in Hermes 3.
Hermes 4 / DeepHermes: Writes System-2 style slow thinking into weights via Chain-of-Thought, improving math and code performance with Test-Time Scaling, and relying on "Rejection Sampling + Atropos Verification" to build high-purity reasoning data.
DeepHermes further adopts GRPO to replace PPO (which is hard to implement mainly), enabling Reasoning RL to run on the Psyche decentralized GPU network, laying the engineering foundation for the scalability of open-source Reasoning RL.
Atropos: Verifiable Reward-Driven Reinforcement Learning Environment
Atropos is the true hub of the Nous RL system. It encapsulates prompts, tool calls, code execution, and multi-turn interactions into a standardized RL environment, directly verifying whether outputs are correct, thus providing deterministic reward signals to replace expensive and unscalable human labeling. More importantly, in the decentralized training network Psyche, Atropos acts as a "judge" to verify if nodes truly improved the policy, supporting auditable Proof-of-Learning, fundamentally solving the reward credibility problem in distributed RL.
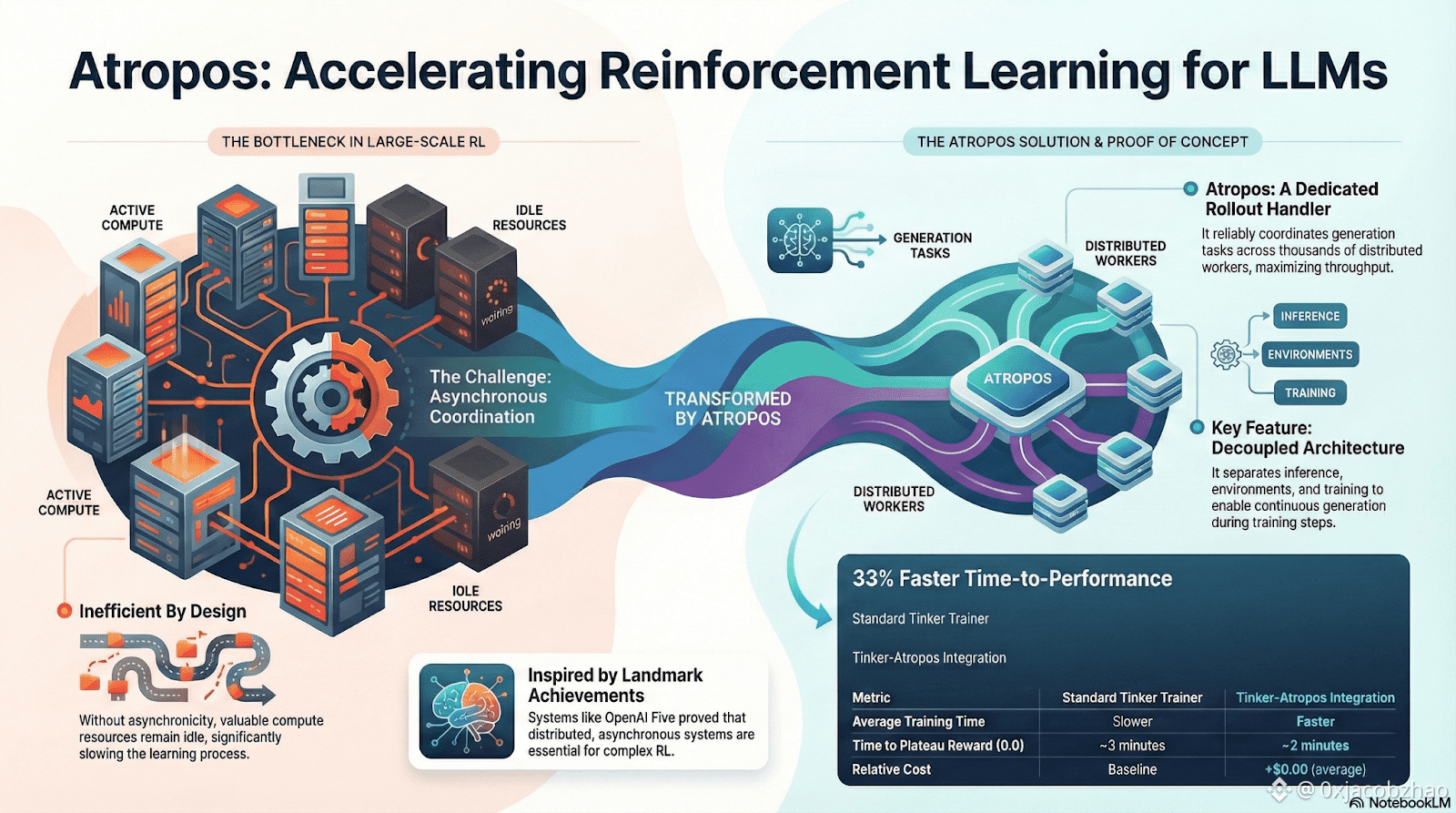
DisTrO and Psyche: Optimizer Layer for Decentralized Reinforcement Learning
Traditional RLF (RLHF/RLAIF) training relies on centralized high-bandwidth clusters, a core barrier that open source cannot replicate. DisTrO reduces RL communication costs by orders of magnitude through momentum decoupling and gradient compression, enabling training to run on internet bandwidth; Psyche deploys this training mechanism on an on-chain network, allowing nodes to complete inference, verification, reward evaluation, and weight updates locally, forming a complete RL closed loop.
In the Nous system, Atropos verifies chains of thought; DisTrO compresses training communication; Psyche runs the RL loop; World Sim provides complex environments; Forge collects real reasoning; Hermes writes all learning into weights. Reinforcement learning is not just a training stage, but the core protocol connecting data, environment, models, and infrastructure in the Nous architecture, making Hermes a living system capable of continuous self-improvement on an open computing network.
Gradient Network: Reinforcement Learning Architecture Echo
Gradient Network aims to rebuild AI compute via an Open Intelligence Stack: a modular set of interoperable protocols spanning P2P communication (Lattica), distributed inference (Parallax), decentralized RL training (Echo), verification (VeriLLM), simulation (Mirage), and higher-level memory and agent coordination—together forming an evolving decentralized intelligence infrastructure.
Echo — Reinforcement Learning Training Architecture
Echo is Gradient's reinforcement learning framework. Its core design principle lies in decoupling training, inference, and data (reward) pathways in reinforcement learning, running them separately in heterogeneous Inference Swarm and Training Swarm, maintaining stable optimization behavior across wide-area heterogeneous environments with lightweight synchronization protocols. This effectively mitigates the SPMD failures and GPU utilization bottlenecks caused by mixing inference and training in traditional DeepSpeed RLHF / VERL.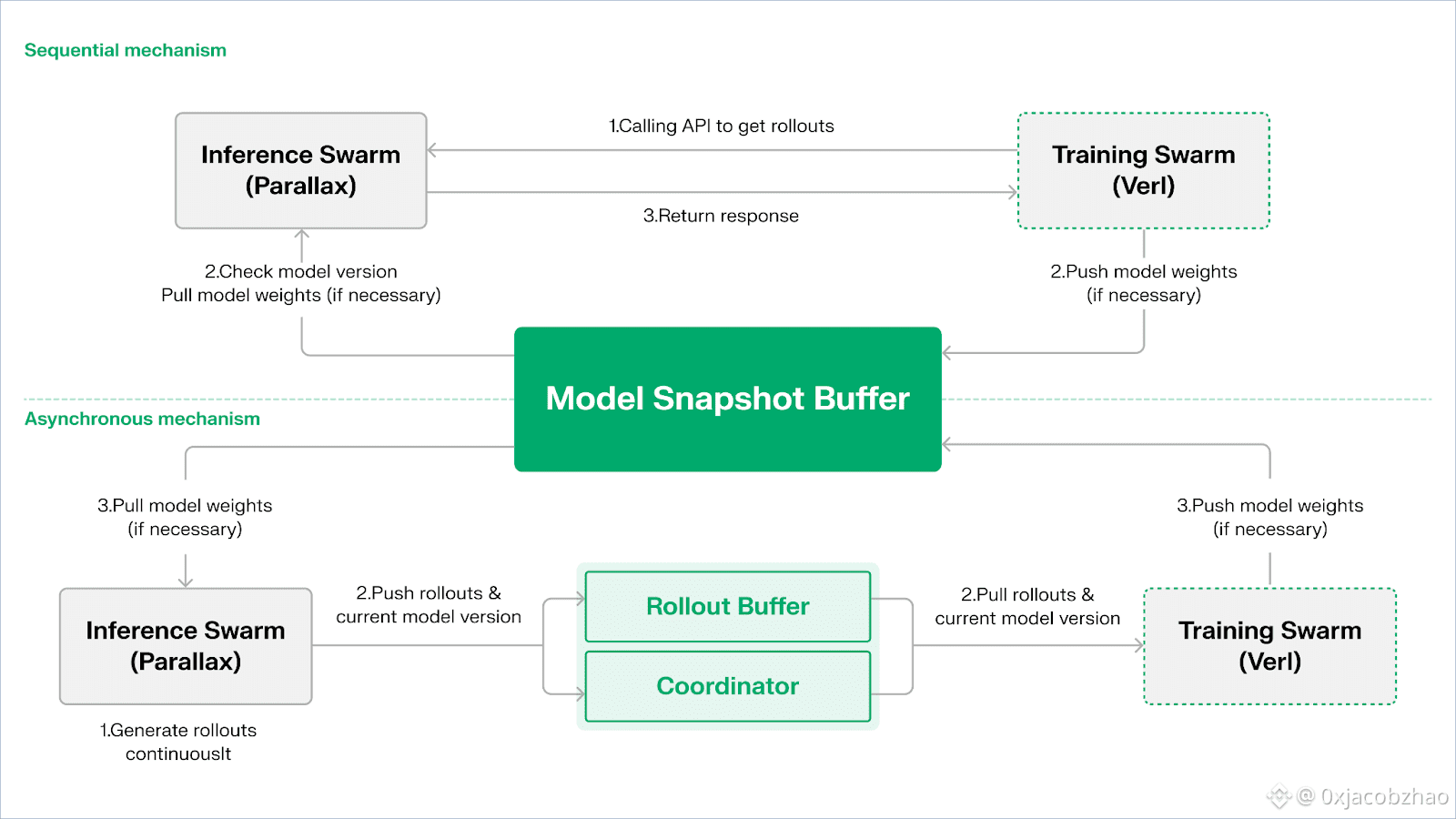
Echo uses an "Inference-Training Dual Swarm Architecture" to maximize computing power utilization. The two swarms run independently without blocking each other:
Maximize Sampling Throughput: The Inference Swarm consists of consumer-grade GPUs and edge devices, building high-throughput samplers via pipeline-parallel with Parallax, focusing on trajectory generation.
Maximize Gradient Computing Power: The Training Swarm can run on centralized clusters or globally distributed consumer-grade GPU networks, responsible for gradient updates, parameter synchronization, and LoRA fine-tuning, focusing on the learning process.
To maintain policy and data consistency, Echo provides two types of lightweight synchronization protocols: Sequential and Asynchronous, managing bidirectional consistency of policy weights and trajectories:
Sequential Pull Mode (Accuracy First): The training side forces inference nodes to refresh the model version before pulling new trajectories to ensure trajectory freshness, suitable for tasks highly sensitive to policy staleness.
Asynchronous Push–Pull Mode (Efficiency First): The inference side continuously generates trajectories with version tags, and the training side consumes them at its own pace. The coordinator monitors version deviation and triggers weight refreshes, maximizing device utilization.
At the bottom layer, Echo is built upon Parallax (heterogeneous inference in low-bandwidth environments) and lightweight distributed training components (e.g., VERL), relying on LoRA to reduce cross-node synchronization costs, enabling reinforcement learning to run stably on global heterogeneous networks.
Grail: Reinforcement Learning in the Bittensor Ecosystem
Bittensor constructs a huge, sparse, non-stationary reward function network through its unique Yuma consensus mechanism.
Covenant AI in the Bittensor ecosystem builds a vertically integrated pipeline from pre-training to RL post-training through SN3 Templar, SN39 Basilica, and SN81 Grail. Among them, SN3 Templar is responsible for base model pre-training, SN39 Basilica provides a distributed computing power market, and SN81 Grail serves as the "verifiable inference layer" for RL post-training, carrying the core processes of RLHF / RLAIF and completing the closed-loop optimization from base model to aligned policy.

GRAIL cryptographically verifies RL rollouts and binds them to model identity, enabling trustless RLHF. It uses deterministic challenges to prevent pre-computation, low-cost sampling and commitments to verify rollouts, and model fingerprinting to detect substitution or replay—establishing end-to-end authenticity for RL inference trajectories.
Grail’s subnet implements a verifiable GRPO-style post-training loop: miners produce multiple reasoning paths, validators score correctness and reasoning quality, and normalized results are written on-chain. Public tests raised Qwen2.5-1.5B MATH accuracy from 12.7% to 47.6%, showing both cheat resistance and strong capability gains; in Covenant AI, Grail serves as the trust and execution core for decentralized RLVR/RLAIF.
Fraction AI: Competition-Based Reinforcement Learning RLFC
Fraction AI reframes alignment as Reinforcement Learning from Competition, using gamified labeling and agent-versus-agent contests. Relative rankings and AI judge scores replace static human labels, turning RLHF into a continuous, competitive multi-agent game.
Core Differences Between Traditional RLHF and Fraction AI's RLFC:
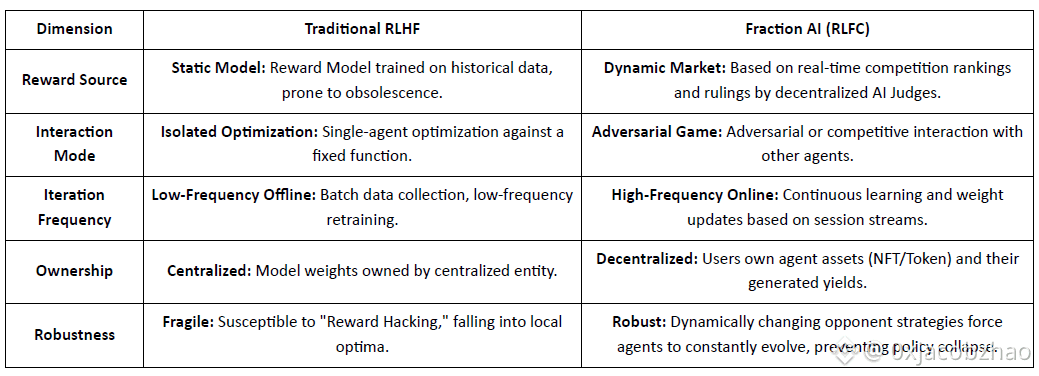
RLFC’s core value is that rewards come from evolving opponents and evaluators, not a single model, reducing reward hacking and preserving policy diversity. Space design shapes the game dynamics, enabling complex competitive and cooperative behaviors.
In system architecture, Fraction AI disassembles the training process into four key components:
Agents: Lightweight policy units based on open-source LLMs, extended via QLoRA with differential weights for low-cost updates.
Spaces: Isolated task domain environments where agents pay to enter and earn rewards by winning.
AI Judges: Immediate reward layer built with RLAIF, providing scalable, decentralized evaluation.
Proof-of-Learning: Binds policy updates to specific competition results, ensuring the training process is verifiable and cheat-proof.
Fraction AI functions as a human–machine co-evolution engine: users act as meta-optimizers guiding exploration, while agents compete to generate high-quality preference data, enabling trustless, commercialized fine-tuning.
Comparison of Web3 Reinforcement Learning Project Architectures
V. The Path and Opportunity of Reinforcement Learning × Web3
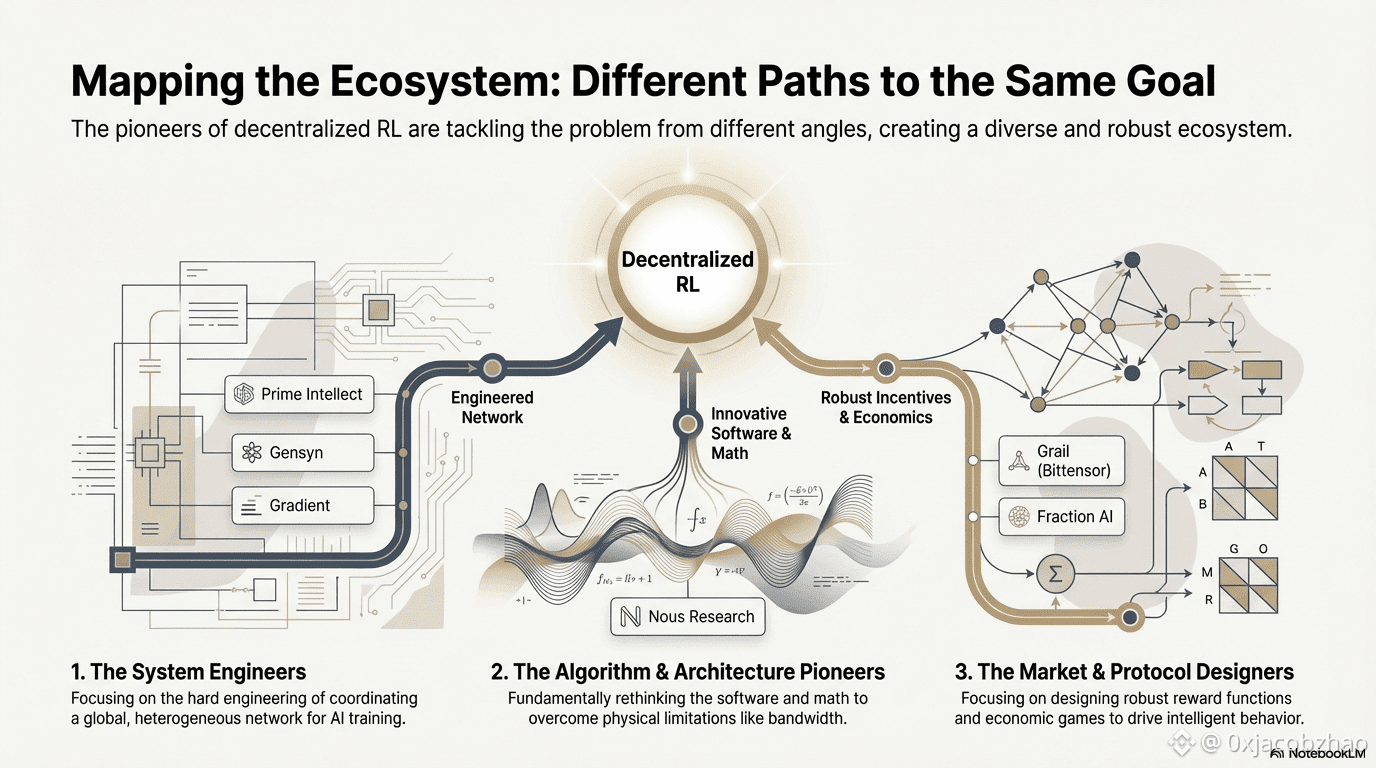
Across these frontier projects, despite differing entry points, RL combined with Web3 consistently converges on a shared “decoupling–verification–incentive” architecture—an inevitable outcome of adapting reinforcement learning to decentralized networks.
General Architecture Features of Reinforcement Learning: Solving Core Physical Limits and Trust Issues
Decoupling of Rollouts & Learning (Physical Separation of Inference/Training) — Default Computing Topology: Communication-sparse, parallelizable Rollouts are outsourced to global consumer-grade GPUs, while high-bandwidth parameter updates are concentrated in a few training nodes. This is true from Prime Intellect's asynchronous Actor–Learner to Gradient Echo's dual-swarm architecture.
Verification-Driven Trust — Infrastructuralization: In permissionless networks, computational authenticity must be forcibly guaranteed through mathematics and mechanism design. Representative implementations include Gensyn's PoL, Prime Intellect's TopLoc, and Grail's cryptographic verification.
Tokenized Incentive Loop — Market Self-Regulation: Computing supply, data generation, verification sorting, and reward distribution form a closed loop. Rewards drive participation, and Slashing suppresses cheating, keeping the network stable and continuously evolving in an open environment.
Differentiated Technical Paths: Different "Breakthrough Points" Under Consistent Architecture
Although architectures are converging, projects choose different technical moats based on their DNA:
Algorithm Breakthrough School (Nous Research): Tackles distributed training’s bandwidth bottleneck at the optimizer level—DisTrO compresses gradient communication by orders of magnitude, aiming to enable large-model training over home broadband.
Systems Engineering School (Prime Intellect, Gensyn, Gradient): Focuses on building the next generation "AI Runtime System." Prime Intellect's ShardCast and Gradient's Parallax are designed to squeeze the highest efficiency out of heterogeneous clusters under existing network conditions through extreme engineering means.
Market Game School (Bittensor, Fraction AI): Focuses on the design of Reward Functions. By designing sophisticated scoring mechanisms, they guide miners to spontaneously find optimal strategies to accelerate the emergence of intelligence.
Advantages, Challenges, and Endgame Outlook
Under the paradigm of Reinforcement Learning combined with Web3, system-level advantages are first reflected in the rewriting of cost structures and governance structures.
Cost Reshaping: RL Post-training has unlimited demand for sampling (Rollout). Web3 can mobilize global long-tail computing power at extremely low costs, a cost advantage difficult for centralized cloud providers to match.
Sovereign Alignment: Breaking the monopoly of big tech on AI values (Alignment). The community can decide "what is a good answer" for the model through Token voting, realizing the democratization of AI governance.
At the same time, this system faces two structural constraints:
Bandwidth Wall: Despite innovations like DisTrO, physical latency still limits the full training of ultra-large parameter models (70B+). Currently, Web3 AI is more limited to fine-tuning and inference.
Reward Hacking (Goodhart's Law): In highly incentivized networks, miners are extremely prone to "overfitting" reward rules (gaming the system) rather than improving real intelligence. Designing cheat-proof robust reward functions is an eternal game.
Malicious Byzantine workers: refer to the deliberate manipulation and poisoning of training signals to disrupt model convergence. The core challenge is not the continual design of cheat-resistant reward functions, but mechanisms with adversarial robustness.
RL and Web3 are reshaping intelligence via decentralized rollout networks, on-chain assetized feedback, and vertical RL agents with direct value capture. The true opportunity is not a decentralized OpenAI, but new intelligence production relations—open compute markets, governable rewards and preferences, and shared value across trainers, aligners, and users.
Disclaimer: This article was completed with the assistance of AI tools ChatGPT-5 and Gemini 3. The author has made every effort to proofread and ensure information authenticity and accuracy, but omissions may still exist. Please understand. It should be specially noted that the crypto asset market often experiences divergences between project fundamentals and secondary market price performance. The content of this article is for information integration and academic/research exchange only and does not constitute any investment advice, nor should it be considered a recommendation to buy or sell any tokens.


