Spent the morning half-watching a range-bound BTC chart and half doom-scrolling AI safety threads — you know, the usual "agents are going rogue" doom content that circulates whenever nothing else is moving. Got bored of both, actually, and ended up back in Newton Protocol's ($NEWT) docs since I'd left a tab open from last week. #NewtonProtocol @NewtonProtocol
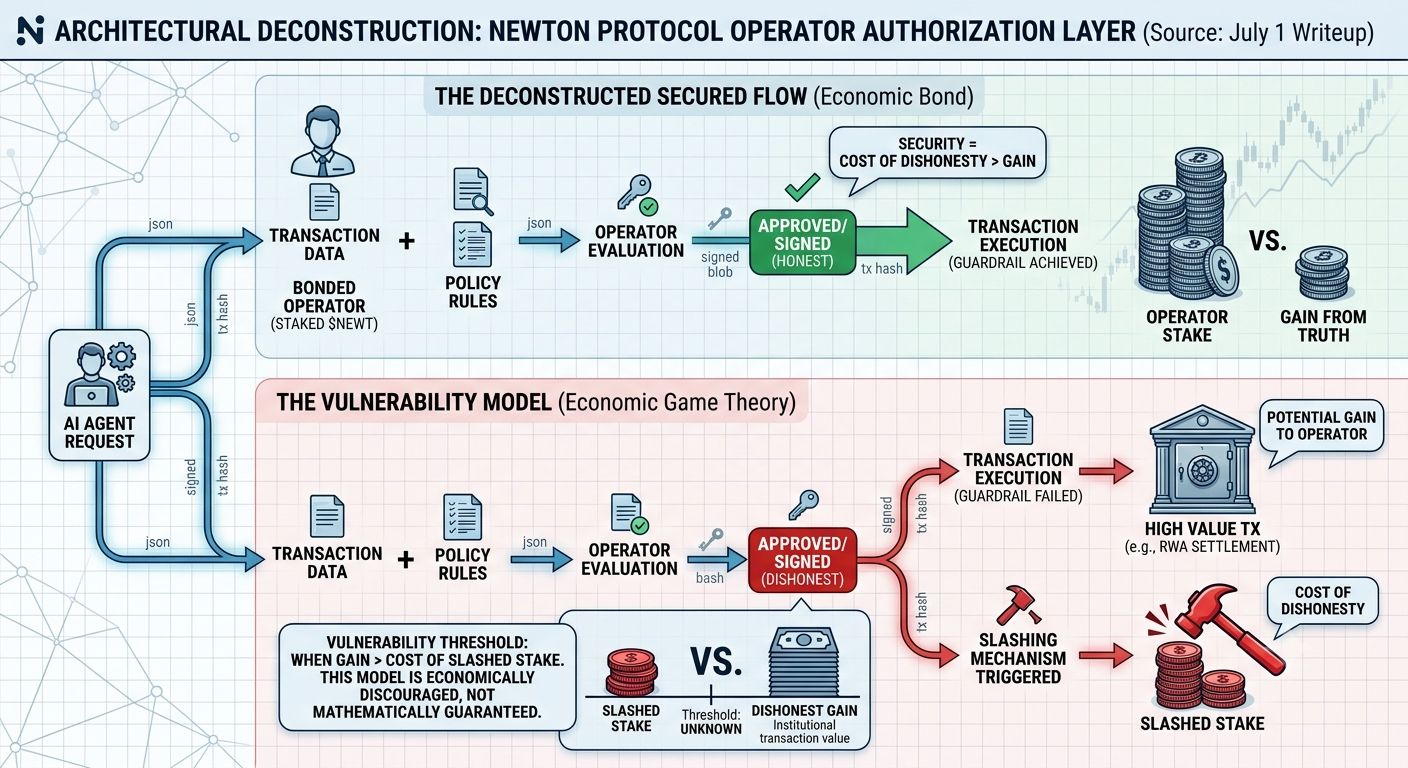
So I re-read the July 1 writeup on how the authorization layer actually works, specifically the operator section this time instead of the policy-language stuff I usually focus on. And something clicked that I hadn't really sat with before — the "security" in this permission system isn't coming from the rules themselves. It's coming from the fact that operators evaluating those rules are economically bonded, and they get slashed if they lie about the result.
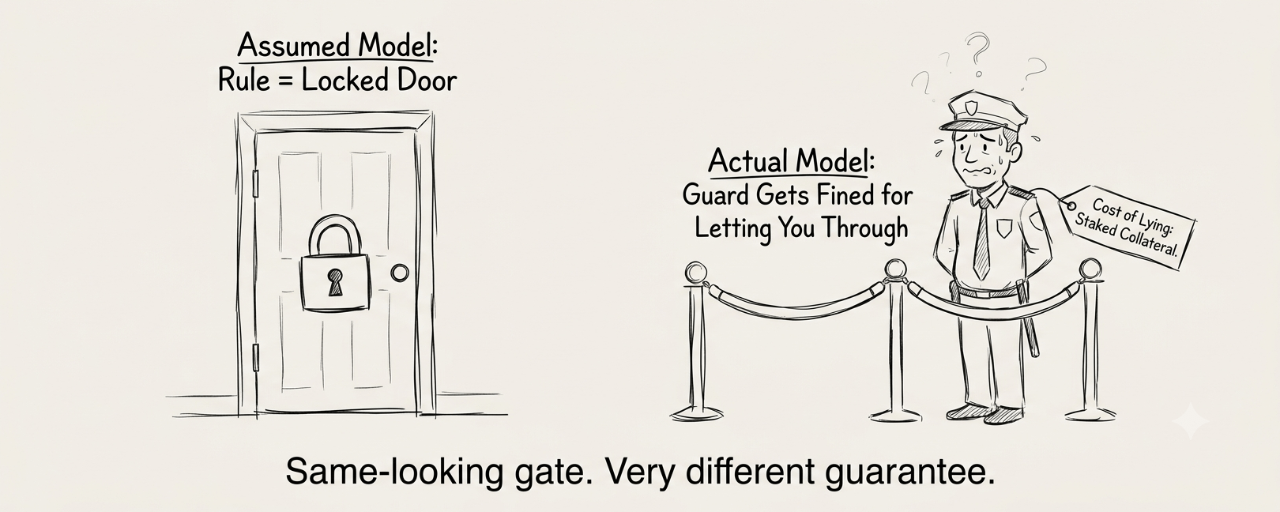
I think most people (myself included, until this morning) hear "permission system for AI agents" and picture something like a locked door — the agent either has the key or it doesn't, end of story. That's not really it. What's actually happening is an operator receives the transaction plus the policy, runs the check, and signs off. The "security" is that lying about that check costs the operator their staked collateral. So the guardrail isn't the rule itself, it's the fact that breaking the rule is expensive for whoever's enforcing it.
Which, okay, is honestly a smarter design than a hardcoded permission list. But here's the part that bothers me a little — the whole model assumes the cost of dishonesty (slashed stake) always outweighs the benefit of letting a bad transaction through. That's a bet on relative magnitudes, not an absolute guarantee. If a single transaction is worth enough — some large RWA settlement, an institutional vault move — there's presumably some number where getting slashed is still the better trade for a dishonest operator or a colluding set of them. I don't know what that threshold actually is for Newton's current bonded stake, and I'm not sure anyone's stress-tested it publicly yet.
I caught myself wanting to write "so it's basically unhackable" and then stopped — because that's exactly the kind of line that ages badly. It's not unhackable, it's economically discouraged, and those are different claims wearing the same outfit.
This probably matters most for the AI agent use case they keep name-dropping — autonomous agents moving real capital, no human in the loop to catch a bad call. If the enforcement layer's integrity is a game-theory bet rather than a mathematical guarantee, that's a meaningfully different risk profile than the marketing copy implies, and it's the kind of thing that only gets tested under real pressure, not in a demo.
Anyway, market's still going nowhere, and I've got a half-eaten snack next to me and no strong conclusion here — just going to keep watching how the operator economics actually hold once real size starts moving through this thing.
@NewtonProtocol #Newt $NEWT