晚上好,兄弟们,我是阿祖,很多人写 APRO 写着写着就会陷进一个误区:把它当成“又一个价格预言机”,然后去比谁更快、谁覆盖更多对。问题是,你如果只用“喂价”去理解 APRO,就会解释不清它为什么要把 AI、非结构化数据、冲突裁决、API/WebSocket 这些东西全塞进同一套体系里。更贴切的说法是:APRO 更像一个“Oracle + AI 中间件”的混合体,它不仅交付一口价格,还试图把“链下信息处理 → 可信验证 → 链上可执行”这一整段流程做成标准化服务,让开发者少造一堆轮子。Binance Research 对它的定义就很明确:这是一个集成 AI 能力的去中心化预言机网络,能用大模型处理新闻、社媒、复杂文档等非结构化数据,把它们转成结构化、可验证的链上数据。
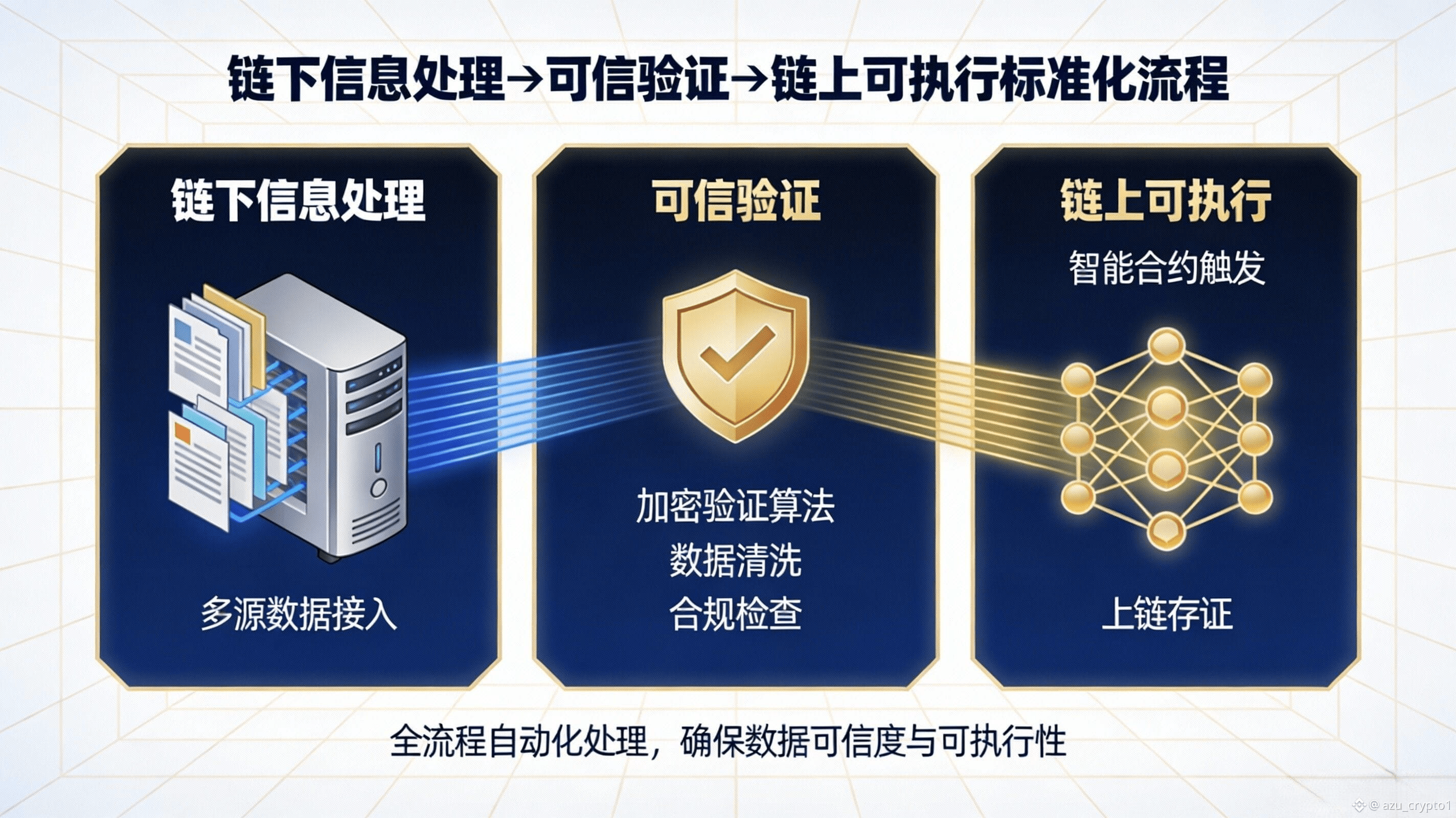
你把 APRO 当成“AI 中间件”的核心证据,其实是它把链下处理和链上验证拆开,又把两者用一条可落地的调用路径重新缝起来。Binance Square 的介绍里写得很直白:链下会从可信提供方收集数据,再经过 AI 驱动的验证层做一致性检查、异常过滤、操纵检测,然后再进入链上验证与交付。 这句话翻成工程语言就是:它不只交付结果,还交付“结果是怎么被筛出来的”这一段过程能力——这段能力在传统 oracle 时代往往散落在项目方自建的数据抓取脚本、风控规则、手工白名单、甚至运营同学的临时判断里,而 APRO 试图把它产品化。
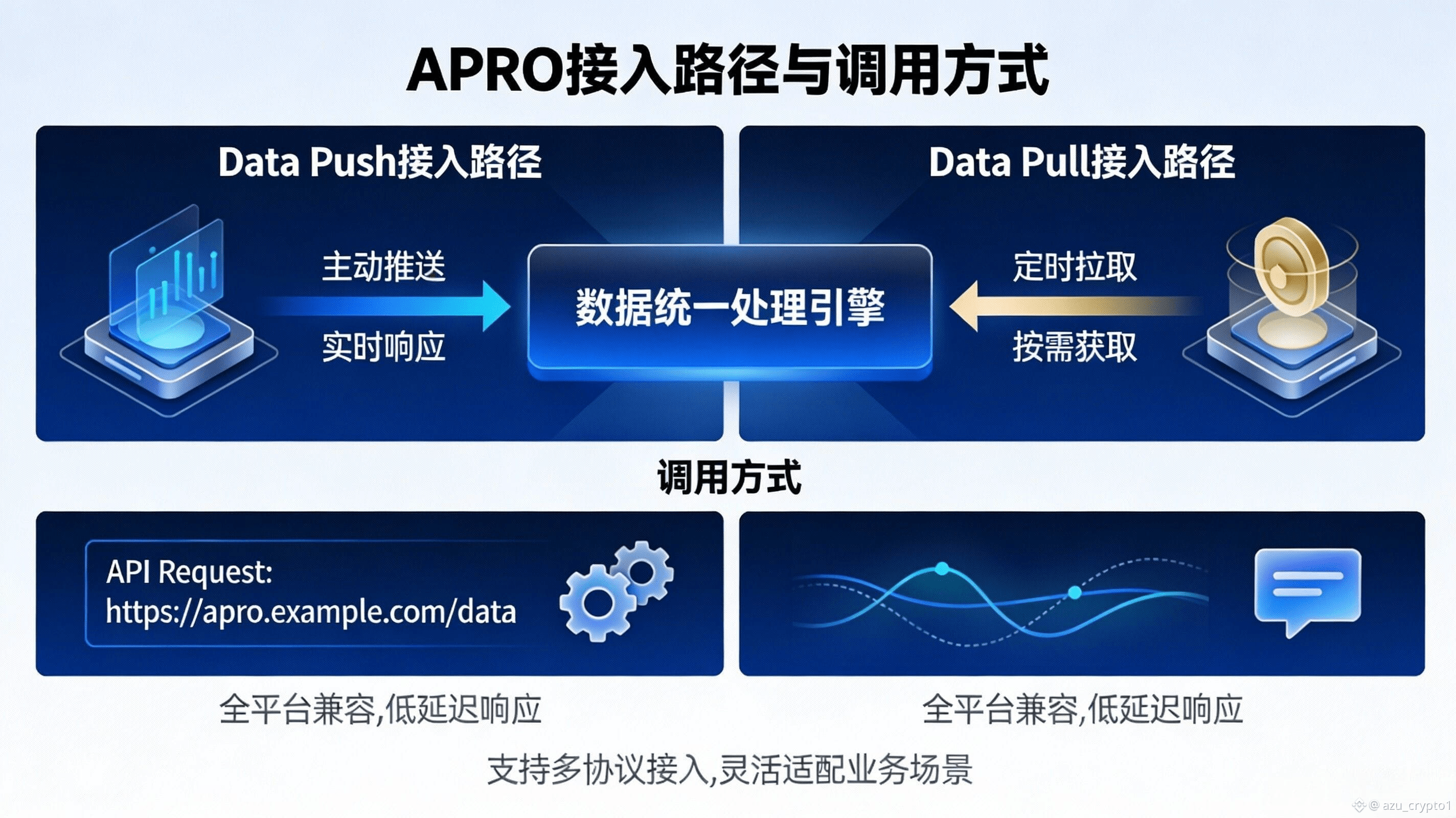
更关键的是,它给开发者的不是单一路径,而是“API/合约接口的组合拳”,这就是中间件味道最重的地方。你如果做传统 DeFi,只想稳稳读一个价格,Data Push 的合约表已经把交易对、偏离阈值、心跳与合约地址列得很清楚,属于典型“直接读合约”的标准化入口,开发者拿来就能用。 可如果你做的是交易、永续、聚合器这类对时间尺度更敏感的业务,Data Pull 的逻辑更像“按需拉取数据并在需要的那一刻把它带上链”:官方 Getting Started 里就明确说,合约可以在需要时按需获取实时价格数据,数据来自许多独立节点聚合,适合“用的时候再取”的模式。 与此同时,它还给了 API & WebSocket 的说明,告诉你如何从接口拿到 report、如何处理缺失 feed 等返回情形——这就很像云服务:你既可以走“纯链上读数”,也可以走“链下取报告 + 链上验真 + 触发逻辑”的更灵活路径。
这套“链下处理 + 链上验证”的组合为什么重要?因为它直接改变了开发者的调用方式,也就是你要我写清楚的规则变化:调用路径更灵活了。以前很多项目做复杂数据需求(尤其是带语义的、带证据的)只能自己搭一条数据管道:抓源、清洗、去重、对齐时间、做异常检测、再写一个上链提交器,还要担心被注入垃圾信息或被带节奏。APRO 的架构叙事正相反——它把“处理复杂输入”放在链下做,把“结果是否可信、是否可执行”放到链上用验证机制兜底,然后再通过合约和 API 两类接口把能力交付给你。ZetaChain 的文档也用非常一句话式的方式概括过:APRO 通过链下处理与链上验证来提供可靠的数据服务,并通过两种服务模型覆盖不同需求。
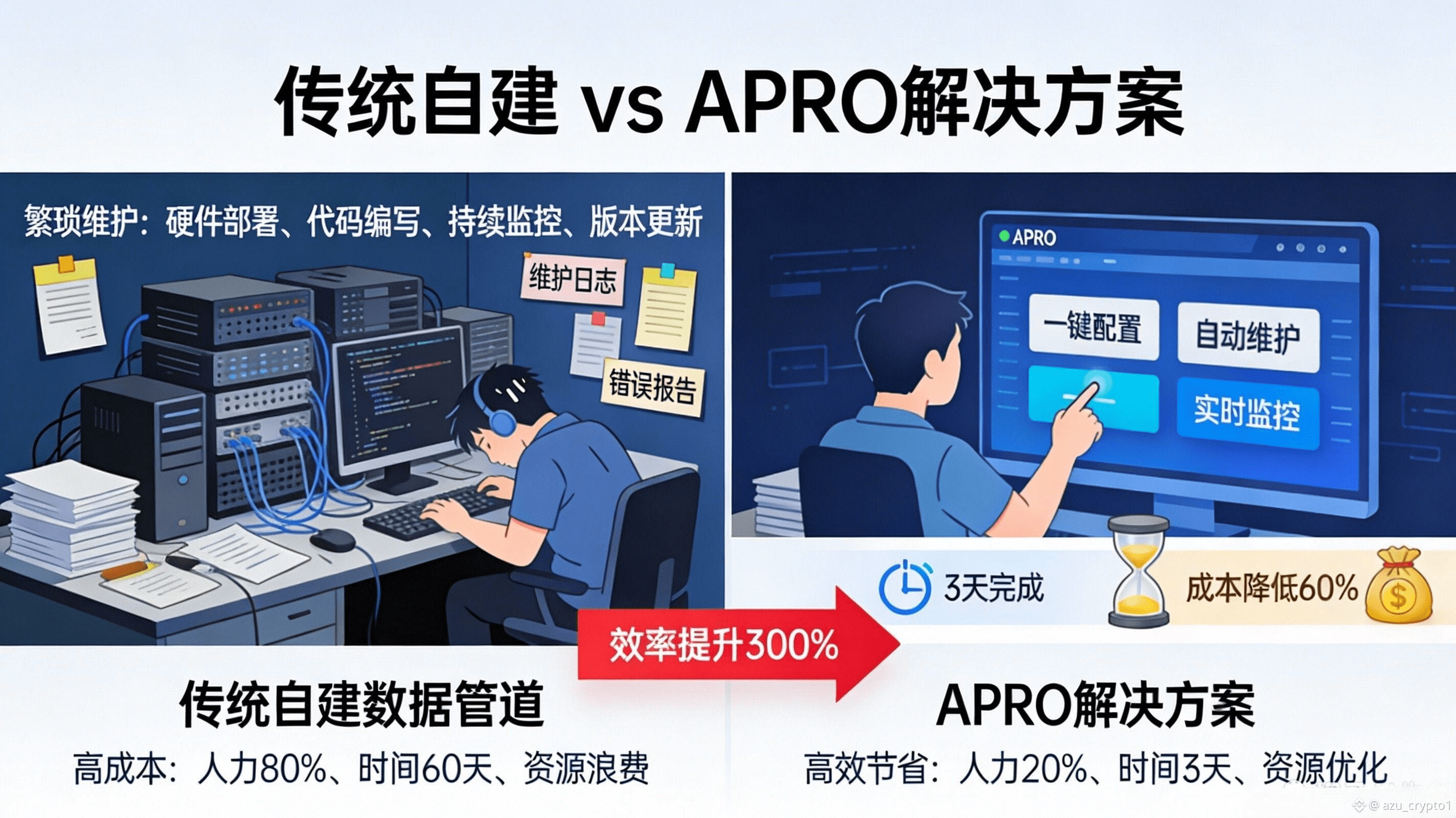
对用户(尤其是开发者和项目方)的影响其实很现实:你省下的不是一行两行代码,而是减少了自建数据管道的长期维护成本。数据管道最贵的地方从来不是“第一天搭起来”,而是“第 90 天你还得维护它”:数据源一变、接口一抖、极端行情一来、恶意样本一进,你就会发现自己在维护一套半吊子中间件。APRO 如果能把“非结构化输入的语义处理、冲突裁决、以及可验证交付”固化成网络能力,那么项目方就可以把精力更多放在业务逻辑、风控策略与产品体验上,而不是天天救火式地修数据。Binance Research 把它的使命说得也很像“中间件愿景”:让 Web3/AI agents 能桥接现实数据,并把它们结构化后上链。
最后用你要的行动指引收尾,我建议你把它写成一个很具体的互动:让读者对照自己的项目技术栈,画一张“接入路径图”。你不用画得像架构图那么专业,就按真实流程画:你现在的数据从哪来,是直接读链上、还是靠 CEX API、还是爬公告与 PDF;你现在在哪里做清洗与异常处理,是后端服务、还是脚本、还是人肉;你现在怎么把结果喂给合约,是定时推送、还是交易时读取、还是把签名报告塞进交易里验证。然后你再把 APRO 的两种入口套进去:标准场景能不能直接用 Data Push 合约读数,交易/高频场景能不能用 Data Pull 的 report 在“同一笔交易”里完成取数与验证,语义/证据链场景能不能让链下先处理、链上只做最终验证与执行。 你把这张图画出来,读者会立刻明白我今天这句话:APRO 不是在跟你抢业务,它是在替你把“数据这半边中间件”产品化。

