Dane to krwiobieg fizycznego AI. Bez nich autonomiczny samochód, dron czy bojowy robot nie zrobią ani kroku. Ale zbieranie tych danych w rzeczywistym świecie to zajęcie kosztowne, czasochłonne i fizycznie niebezpieczne. Startup DiffuseDrive proponuje inny sposób: generować realistyczne syntetyczne dane przy użyciu modeli dyfuzyjnych — i robić to na przemysłową skalę.
Cena rzeczywistego doświadczenia
Firma Waymo, zanim uruchomiła pełnoprawną usługę bezzałogowego taksówki w San Francisco w 2024 roku, zbierała dane na drogach Kalifornii przez 15 lat — od 2010 roku, kiedy jej macierzysta struktura Google po raz pierwszy wyjechała na test. W tym czasie zgromadziło się około 20 mln mil rzeczywistych przejazdów. Koszt takiego projektu zbliża się do miliarda dolarów. To właśnie ten bariera sprawia, że rynek autonomicznego prowadzenia jest praktycznie zamknięty dla nowicjuszy.
Analogiczny problem stoi przed twórcami fizycznego AI w budownictwie, rolnictwie, przemyśle wydobywczym, na kolei, w marynarce i lotnictwie. Wszędzie potrzebne są dane: różnorodne, obejmujące rzadkie i krytyczne scenariusze — te same „długie ogony” rozkładu, w których systemy najczęściej się mylą.
Syntetyka kontra rzeczywistość
Kalifornijski startup DiffuseDrive (DD) został założony w 2023 roku przez byłych pracowników Boscha — dyrektora generalnego Bálinta Pásztora i dyrektora technicznego Rolanda Pintéra. W latach 2024–2025 firma pozyskała 5 mln dolarów: 4 mln w ramach rundy seed od Outlander, Presto Tech Horizons i NeuronVC, a także wcześniejsze inwestycje od E2VC. W zespole znajduje się 12 osób, z czego cztery pracują w USA, a osiem — w Europie.
Firma skupia się na rynku syntetycznych danych wizualnych, który obecnie szacuje się na około 425 mln dolarów, a do 2030 roku, według prognoz analityków, wzrośnie do 2 miliardów dolarów.
Sedno podejścia DD polega na wzięciu rzeczywistych danych klienta (wideo i obrazy z kamer, już oznaczone), przeprowadzeniu ich analizy statystycznej i na tej podstawie wygenerowaniu tysięcy i milionów syntetycznych scen, które nigdy nie wystąpiły w rzeczywistym świecie, ale są statystycznie wiarygodne.
Jak to działa
Proces zaczyna się od analizy danych klienta pod wieloma kątami:
Analiza rozmiarów ograniczających ramek — określa, jak dobrze w danych reprezentowane są bliskie i dalekie obiekty.
Analiza rozkładu centralnych punktów — wykrywa, czy obiekty na krawędziach kadru są wystarczająco reprezentowane.
Klasteryzacja i pokrycie przestrzeni cech — pokazuje, gdzie danych jest nadmiar, a gdzie — białe plamy.
Macierz współwystępowania — mierzy, jak często różne klasy obiektów pojawiają się w jednym kadrze, co pomaga wykryć rzadkie i krytycznie istotne kombinacje.
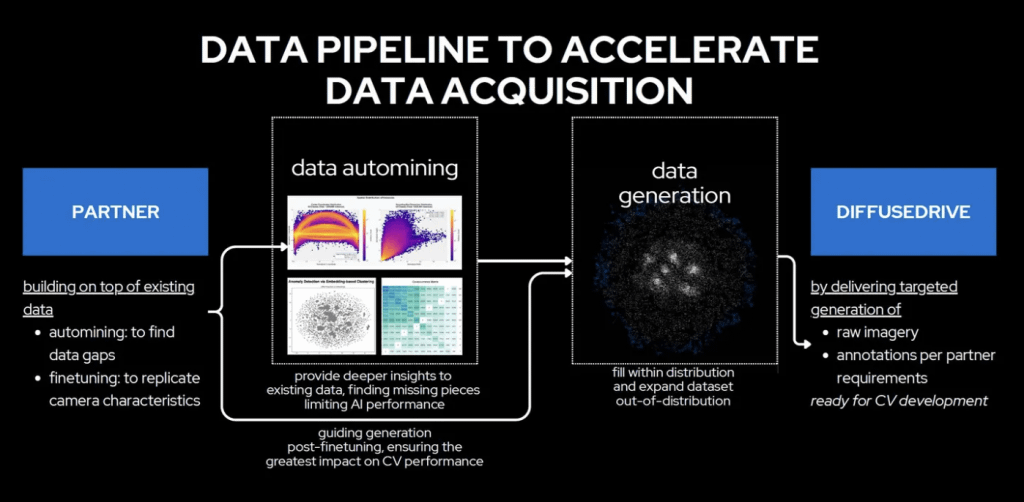
Po zidentyfikowaniu luk w grę wchodzą modele dyfuzyjne. Ta technologia, leżąca u podstaw nowoczesnych systemów generatywnych, działa w ten sposób: do początkowych obrazów stopniowo wprowadza się losowy szum, a następnie jest on systematycznie usuwany — a na wyjściu otrzymuje się nowy, wysokiej jakości syntetyczny obraz. Duże modele językowe (LLM) pełnią rolę „reżyserów”: przekształcają prośby użytkowników w strukturalne opisy tekstowe, które kierują modelem dyfuzyjnym do odpowiedniego wyniku.
Klient może określić zakresy parametrów środowiska — ukształtowanie terenu, pogodę, oświetlenie, porę dnia — wskazać typy obiektów i ich interakcje, a także zażądać rzadkich konfiguracji: na przykład tygrysa na autostradzie lub ulewy, przy której kamery ledwie działają. Wszystkie wygenerowane dane są automatycznie oznaczane — na podstawie parametrów określonych podczas opisu scenariusza.
Testy na rzeczywistych danych
Aby udowodnić wartość swojego podejścia, DD przeprowadziła eksperyment na podzbiorze otwartego zbioru danych DOTA, szeroko stosowanego w komputerowym widzeniu. Z niego wyodrębniono 2 961 rzeczywistych zdjęć z powietrznymi statkami: 93% — samoloty, 7% — helikoptery.
Podczas szkolenia sieci neuronowej tylko na rzeczywistych danych z takim nierównowagą klas, rozpoznawanie helikopterów okazało się niezadowalające. Dodanie syntetycznych obrazów od DD w celu zbalansowania klas znacznie poprawiło wyniki rozpoznawania helikopterów. Przy połączeniu wszystkich rzeczywistych i syntetycznych danych jakość rozpoznawania znacznie wzrosła w obu klasach.
Kto już współpracuje z DD
Wśród klientów startupu znajduje się duży światowy dostawca części samochodowych oraz amerykański kontrahent obronny, chociaż ich nazwy na razie nie są ujawniane.
Producent samochodów wykorzystuje syntetyczne dane DD do nauki systemów ADAS (systemów wspomagania kierowcy) i autonomicznego prowadzenia. Osobny bonus: syntetyczne dane domyślnie spełniają europejskie przepisy GDPR dotyczące ochrony danych osobowych — w przeciwieństwie do rzeczywistych nagrań, które wymagają ręcznego usuwania tablic rejestracyjnych i informacji geolokalizacyjnych.
Kontrahent obronny, z którym DD zaczęła współpracę w czwartym kwartale 2025 roku, zajmuje się przetwarzaniem danych sensorycznych i GPS z platform wojskowych — lądowych, powietrznych i morskich. Zadanie polega na budowaniu map percepcyjnych, rozpoznawaniu zagrożeń i koordynowaniu autonomicznego ruchu aktywów w warunkach zakłóceń radiowych i przeciwdziałania ze strony wroga. W tym celu DD analizuje zdjęcia satelitarne obszarów konfliktów i generuje na ich podstawie syntetyczne scenariusze szkoleniowe z hierarchicznym oznaczeniem obiektów: samoloty, helikoptery, czołgi, statki — z dokładną klasyfikacją w każdej grupie.
Fizyczny AI opiera się na danych — i to wąskie gardło spowalnia całą branżę. DiffuseDrive oferuje sposób na jego rozluźnienie: generowanie syntetycznych danych z automatycznym oznaczaniem, skalowalnie i bez ogromnych kosztów testów terenowych. Firma działa jednocześnie w kilku sektorach — od automatyki cywilnej po zastosowania wojskowe, co daje jej możliwość gromadzenia międzysektorowej ekspertyzy i zmniejszenia zależności od sukcesu w jakiejkolwiek jednej niszy.
Opinia AI
Z perspektywy analizy danych przez maszyny, historia technologicznych przejść pokazuje ciekawą tendencję: za każdym razem, gdy koszt produkcji kluczowego zasobu drastycznie spada, rynek nie tylko rośnie — zmienia się strukturalnie. Syntetyczne dane znajdują się teraz mniej więcej w miejscu, w którym obliczenia w chmurze były w latach 2008–2010: niszowe narzędzie dla wybranych szybko staje się podstawową infrastrukturą. Ale jest pewien niuans, którego artykuł nie porusza: problem 'distribution shift' — rozbieżności między syntetycznym rozkładem danych a rzeczywistym światem. Sieć neuronowa, wytrenowana na idealnie zrównoważonej syntetyce, może się pogorszyć w obliczu chaosu rzeczywistości tam, gdzie nikt jej nie testował.
#AI #AImodel #BinanceSquare #Write2Earn

