@Mira - Trust Layer of AI Reliability is the thing we only talk about after it hurts us.
You can live for weeks enjoying how fast a model drafts, summarizes, explains, or rewrites—then one day it slips a single wrong detail into the middle of something important, and suddenly the whole experience feels different. Not because the tool “failed” in a dramatic way, but because it failed in the most unsettling way: it sounded calm and certain while being wrong. That’s the kind of mistake people don’t catch. That’s the kind that gets forwarded, signed, shipped, or acted on.
Mira Network starts from a blunt admission: this isn’t a bug you can fully train away. You can make models better, and you should, but there’s always going to be a residue of error—especially in edge cases, messy real-world questions, and situations where the model has to connect dots it was never explicitly taught to connect. The more fluent the model becomes, the more that residue can masquerade as confidence. So Mira treats reliability less like a feature and more like a missing layer.
The way it tries to fill that gap is oddly practical. It doesn’t ask you to trust one model more. It assumes you shouldn’t.
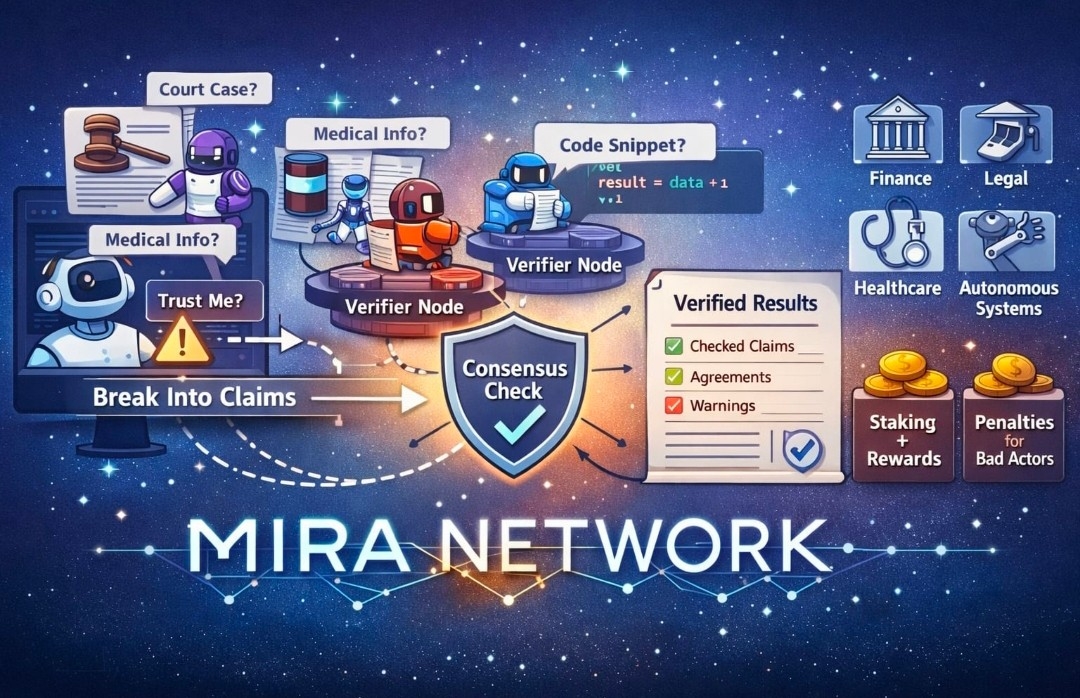
Instead of letting a single model produce an answer and calling it done, Mira’s approach is to take what the model produced and turn it into smaller pieces that can actually be checked. Not “Is this paragraph good?” but “Is this specific claim true?” and “Does this step logically follow from the previous one?” When you break an output into claims like that, the conversation stops being about vibes and starts being about verifiable statements.
That claim-splitting step sounds minor until you picture how humans read. We don’t read like auditors. We read for meaning. We glide. Our brains smooth over gaps because that’s what they’re built to do. If a model gives you five correct sentences and one subtly wrong one, the wrong one often slips right through because the surrounding correctness makes it feel safe. Mira’s design is basically saying: stop asking tired humans to be full-time error detectors, and build a system that forces the output to stand still long enough to be examined.
Once the output is turned into claims, those claims go out to independent verifiers. Not one checker with a single perspective, but multiple verifier nodes, ideally running different models with different weaknesses. Each verifier returns a judgment, and then the network aggregates those judgments into a consensus result. The goal isn’t perfection. The goal is to make it harder for a mistake to survive when it has to pass through several sets of eyes that don’t share the same blind spot.
This is also why decentralization is not just a buzzword in Mira’s story. If verification is centralized—one company, one model, one definition of “correct”—then your reliability layer inherits that single worldview and its limitations. A decentralized verifier set, at least in theory, introduces diversity: different training histories, different approaches, different failure patterns. Sometimes that means disagreement, and people tend to fear disagreement. Mira treats it as useful information. If verifiers don’t agree, that’s the system telling you where the uncertainty lives. It’s the opposite of a confident lie.
The part that makes or breaks any verification network is incentives, and Mira doesn’t dodge that. In a decentralized system, you can’t just ask participants to be honest and hope for the best. If verifiers get paid, some will try to get paid without doing the work. If they can guess answers and still earn often enough, some will guess. So Mira leans on staking and penalties to make lazy verification a bad strategy. The simplest version is: if you want rewards, you need to actually verify; if you keep behaving like you’re faking it, you lose stake and the “easy money” disappears.
That incentive layer is the difference between verification as a moral request and verification as a functioning market. It turns careful checking into paid labor, and it puts a cost on pretending. It’s not glamorous, but it’s honest about what people do when money is on the line.
What comes out the other side isn’t just “approved” or “rejected.” It’s an auditable record—something closer to a certificate than a chat response. A structured artifact that says what was checked, what the network agreed on, and where it didn’t. That matters because AI doesn’t only fail in the moment; it fails later, when somebody asks, “Why did we trust this?” and nobody can answer except with a shrug and a screenshot. A verification certificate gives you something you can point to. Something you can store. Something you can re-check when facts change.
Of course, consensus isn’t magic. A group can agree and still be wrong. If all the verifiers are too similar, you get the same blind spot repeated five times. If a claim is ambiguous, you can end up with confident disagreement or confident agreement on the wrong interpretation. If the claim-splitting step is sloppy, you might verify the wrong thing with a lot of ceremony. None of this disappears just because the system is decentralized.
But there’s a difference between a system that hides those weaknesses and one that forces them into the open. The most trustworthy verification process is the one that’s comfortable admitting, “This part is unclear,” instead of papering over uncertainty with polished language. A reliability layer earns trust by making uncertainty visible and actionable, not by pretending it doesn’t exist.
There’s also the practical tension: verification costs time and compute. People won’t want it for everything. They’ll want it for the moments when being wrong is expensive—compliance, finance, health-adjacent guidance, public-facing claims, automated agents that take actions, anything where one small mistake can cascade. Mira’s bet is that the world will split AI outputs into lanes: fast-and-cheap for low-stakes use, verified-and-defensible for the rest.
If you zoom out, the most interesting thing Mira is really pushing isn’t a specific set of APIs or token mechanics. It’s a cultural shift in how we relate to machine outputs. Right now, AI often speaks like a confident assistant, and we’re expected to act like skeptical editors. That setup doesn’t scale. What Mira is trying to build is a different contract: the model can speak, but its claims have to survive scrutiny—independent scrutiny—and the result of that scrutiny is recorded as something you can audit.
That’s a quieter kind of progress than a flashy new model release, but it’s the kind that actually changes what people dare to use AI for. When the question stops being “Can it generate this?” and becomes “Can it justify this well enough that we can rely on it?” you’re no longer just making text. You’re building systems that can be held accountable.
@Mira - Trust Layer of AI #Mira $MIRA