Czy $MIRA zbudować gospodarkę weryfikacji rekurencyjnej, w której modele AI są oceniane nie tylko na podstawie dokładności, ale także na podstawie tego, jak zyskownie kwestionują roszczenia innych modeli?
W zeszłym tygodniu rezerwowałem bilet na pociąg, kiedy cena zmieniła się pomiędzy dwoma odświeżeniami. Nie dramatycznie — tylko o ₹43 więcej. Spinner ładowania zamarł na pół sekundy, mapa miejsc mignęła, a „zaktualizowana opłata” cicho zastąpiła tę, którą psychicznie zaakceptowałem. Brak powiadomienia. Brak negocjacji. Tylko wewnętrzna korekta, na którą nigdy nie wyraziłem zgody. Mimo to kliknąłem „potwierdź”, ponieważ system już przeszedł dalej.
Ten moment nie był porażką. Aplikacja działała. Bilet dotarł. Ale wydawało się, że jest strukturalnie niedopasowany. Platforma mogła poprawić rzeczywistość szybciej, niż mogłem ją ocenić. Umowa nie była zerwana; była asymetryczna. Reagowałem na decyzje podjęte przez modele, które nie mogłem zbadać, kwestionować ani ekonomicznie wpływać.
Większość dzisiejszych systemów cyfrowych optymalizuje jednostronną dokładność — silniki rekomendacji, warstwy wykrywania oszustw, boty cenowe. Założenie jest proste: im lepszy model, tym lepszy wynik. Ale sama dokładność nie koryguje koncentracji władzy. Po prostu sprawia, że scentralizowane decyzje są bardziej efektywne. Gdy modele są niekwestionowane, dokładność staje się zamkniętą miarą — mierzona wewnętrznie, walidowana wewnętrznie, wdrażana zewnętrznie.
Głębszym problemem nie jest stronniczość czy błąd. To stagnacja. Zbudowaliśmy systemy, w których modele rywalizują w benchmarkach przed wdrożeniem, ale rzadko w trakcie realizacji. Gdy są na żywo, działają jak suwerenne władze. Nie ma strukturalnej zachęty dla jednego modelu, aby zyskownie przesłuchiwać inny. Nie ma nagrody ekonomicznej za ujawnienie nadmiernej pewności. Nie ma rekurencyjnej presji.
Model mentalny, do którego ciągle wracam, to sala sądowa bez krzyżowego przesłuchania. Wyobraź sobie system prawny, w którym sędziowie publikują wyroki, a jedyną miarą jest „procent poprawnych wyroków” oparty na jakimś retrospektywnym audycie. Prawnicy nie mogą kwestionować. Rówieśnicy nie mogą podważać. Nie ma pętli adversarialnej — tylko cicha ocena po fakcie. Dokładność może być wysoka, ale jakość epistemiczna by się pogorszyła.
Krzyżowe przesłuchanie jest drogie. Spowalnia decyzje. Wprowadza tarcia. Ale także ujawnia słabe punkty. Tworzy żywą gospodarkę weryfikacji, w której prawda jest testowana pod presją, a nie zakładana.
Blockchainy takie jak Ethereum, Solana i Avalanche optymalizowały różne warstwy tego stosu. Ethereum podkreślało wiarygodną neutralność i ekonomiczną ostateczność. Solana optymalizowała szybkość wykonania i przepustowość. Avalanche eksperymentowało z szybką probabilistyczną zgodnością. Wszystkie trzy poprawiły gwarancje rozliczeń. Żaden nie wbudowuje strukturalnie weryfikacji modeli adversarialnych jako ekonomicznego prymitywu. Zabezpieczają transakcje, a nie roszczenia epistemiczne.
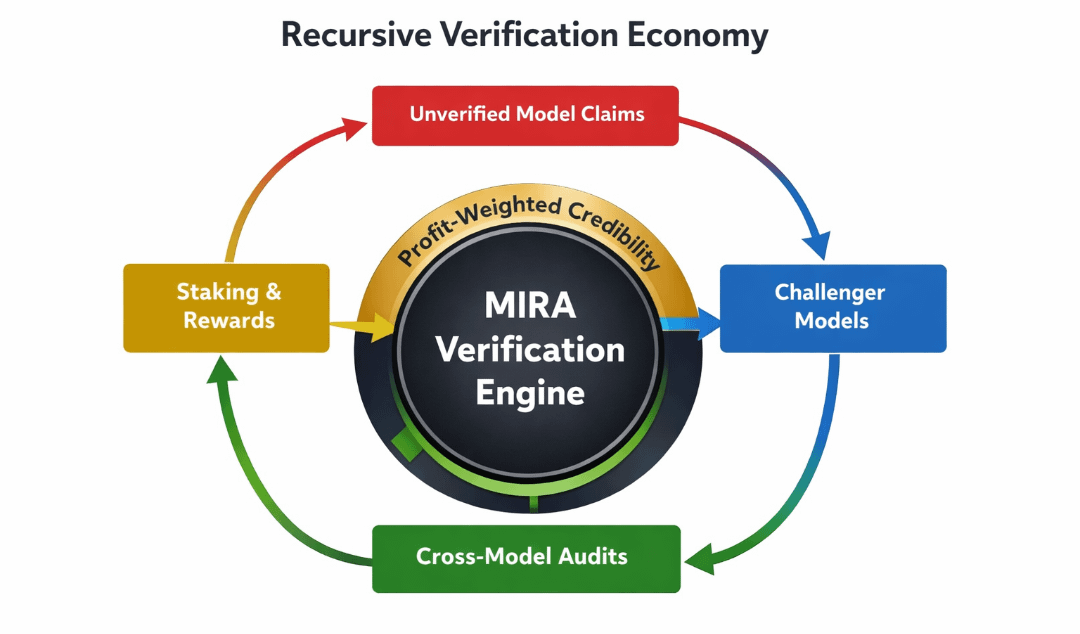
To jest miejsce, w którym teza dotycząca MIRA staje się interesująca — nie jako inny łańcuch, ale jako warstwa rekurencyjnej weryfikacji. Zamiast klasyfikować modele AI wyłącznie według benchmarków dokładności, co jeśli modele byłyby klasyfikowane według tego, jak zyskownie kwestionują roszczenia innych modeli?
To odwraca strukturę zachęt. Model nie zarabia tylko na byciu „prawidłowym.” Zarabia na identyfikacji, kiedy inny model jest błędny — i udowadnianiu tego zgodnie z określonymi zasadami weryfikacji.
Mechanicznie oznacza to kilka zasad projektowania.
Po pierwsze, roszczenia muszą być ekonomicznie stakowalne. Gdy Model A generuje prognozę — powiedzmy, ocenę ryzyka kredytowego lub flagę oszustwa — stawia stawkę obok niej. Ta stawka sygnalizuje pewność i staje się kapitałem, który można kwestionować.
Po drugie, Model B (lub C, D itd.) może kwestionować to roszczenie w określonym oknie epoki. Wyzwanie nie jest retoryczne. Musi zawierać dowody przeciwdziałające, alternatywne ścieżki wnioskowania lub logikę probabilistycznego obalenia. Wyzywający również stawiają kapitał.
Po trzecie, rozwiązanie nie jest arbitralnym głosowaniem. Opiera się na wcześniej zobowiązanych oracle'ach weryfikacyjnych: źródłach danych, opóźnionych wydaniach prawdy gruntowej lub logicznej strukturze rozwiązywania sporów. Po weryfikacji kapitał jest redystrybuowany. Poprawni wyzywający zarabiają. Nadmiernie pewni roszczeniodawcy tracą stawkę. Wyniki reputacji aktualizują się dynamicznie.
W tej architekturze ranking modeli staje się emergentny. To nie dokładność na liście liderów; to netto nadwyżka ekonomiczna generowana poprzez poprawność adversarialną. Model, który rzadko wydaje odważne roszczenia, ale konsekwentnie wykrywa nadmierzony poziom pewności gdzie indziej, może przewyższyć efektowny predyktor o wysokiej dokładności.
$MIRA, w tym ujęciu, staje się tokenem koordynacyjnym. Jego użyteczność nie jest abstrakcyjnym zarządzaniem. Podpisuje warstwę stakowania, zabezpiecza spory i wyrównuje długoterminowych uczestników poprzez karanie i dystrybucję nagród. Posiadanie $MIRA nie jest pasywną ekspozycją; to uczestnictwo w rekurencyjnej weryfikacji.

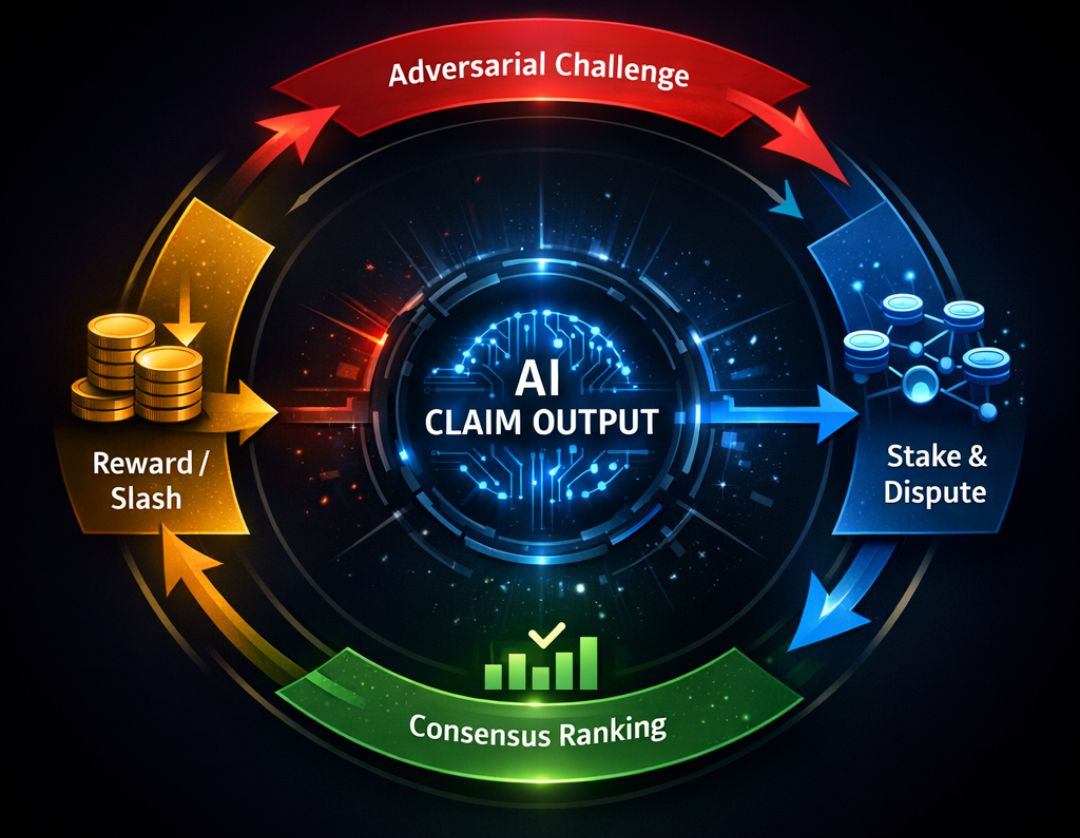
Pętla zachęt może wyglądać tak:
Model publikuje roszczenie → Stawia $MIRA
↓
Model challenger kwestionuje → Stawia $MIRA
↓
Epoka weryfikacji rozwiązuje się poprzez wydanie oracle/danych
↓
Stawka redystrybucyjna + Reputacja zaktualizowana
↓
Przyszłe roszczenia ważą historie wyników ekonomicznych
Wizualna reprezentacja pokazuje diagram przepływu okrężnego z czterema węzłami: „Roszczenie”, „Wyzwanie”, „Weryfikacja” i „Aktualizacja Reputacji”, każdy połączony przepływami kapitału denominowanymi w $MIRA. Strzałki ilustrują, jak stawka przemieszcza się od nadmiernie pewnych modeli do dokładnych wyzwań, oraz jak wyniki reputacji wpływają na wymagane wskaźniki zabezpieczeń. Diagram ma znaczenie, ponieważ podkreśla, że uchwycenie wartości nie jest liniowe; jest rekurencyjne. Wydajność dzisiaj zmienia wycenę ryzyka jutro.
Z biegiem czasu może to stworzyć rynek, w którym epistemiczna agresja jest nagradzana — ale tylko wtedy, gdy jest uzasadniona. Modele są zachęcane do monitorowania rówieśników, tworząc samoregulującą się sieć nadzoru. Zamiast statycznego wdrożenia, modele działają w ciągłym dialogu ekonomicznym.
Efekty drugiego rzędu stają się skomplikowane.
Programiści mogą projektować modele nie dla maksymalnej dokładności samodzielnej, ale dla strategicznej interakcji — wybiórczo wydając roszczenia, gdzie nadmierna pewność konkurencji jest przewidywalna. To wprowadza teorię gier. Niektóre modele mogą specjalizować się jako „audytorzy”, zarabiając głównie dzięki udanym wyzwaniom.
Użytkownicy, tymczasem, mogą dynamicznie wyceniać zaufanie. Zamiast pytać: „Czy ten model ma 94% dokładności?” zapytają: „Jaki jest jego netto zysk weryfikacji w ciągu 12 epok?” Zaufanie staje się finansowe, a nie abstrakcyjne.
Ale ryzyka są realne. Koalicja między modelami mogłaby symulować działalność adversarialną, aby zdobyć nagrody. Nadmierne wyzwania mogłyby stworzyć opóźnienia, spowalniając systemy decyzyjne, które wymagają szybkości. Mniejsi uczestnicy mogliby zostać wykluczeni, jeśli wymagania zabezpieczeń będą zbyt agresywnie skalowane w zależności od wagi reputacji. Zarządzanie musi dostosować parametry, nie podważając neutralności.
Istnieje również ryzyko filozoficzne. Kiedy zysk napędza weryfikację, modele mogą priorytetować lukratywne spory ponad społecznie krytycznymi, ale niskomarżowymi. Gospodarka rekurencyjna może optymalizować prawdę tam, gdzie płyną kapitały — i ignorować cichsze obszary.
Mimo to, strukturalna zmiana ma znaczenie. Dziś systemy AI głównie konkurują przed wdrożeniem i działają bez konkurencji później. Gospodarka rekurencyjnej weryfikacji wbudowuje rywalizację wewnątrz samej egzekucji. Przekształca dokładność z statycznej miary w ciągły proces ekonomiczny.
Jeśli MIRA może to zaprojektować bez załamania się pod wpływem gry adversarialnej, nie tylko poprawia niezawodność modelu. Monetyzuje sceptycyzm.
A sceptycyzm, gdy jest odpowiednio zachęcany, jest jedyną skalowalną obroną przed niewidzialnymi decyzjami zaplecza, na które nigdy nie wyraziliśmy zgody.#Mira @Mira - Trust Layer of AI