I’ve been thinking about what we really mean when we call an AI system “correct.” On closer inspection, it becomes clear that the word carries more certainty than it actually deserves.
Most of the time, we aren’t talking about proof. We're talking about outputs that feel consistent. They match patterns. They align with what we expected to hear. That’s usually enough for us to move on.
But when I step back, that doesn’t feel like correctness in any final sense. It feels more like statistical alignment than something we can stand behind.
Large language models don’t verify claims. They generate responses based on probability distributions learned from data.
When a model answers, it isn’t proving anything. It is estimating what is most likely to be right and I don't see that as a flaw. It is simply how these systems work.
In low stakes contexts, that distinction barely matters. A slightly inaccurate summary doesn’t change much.
 But when AI begins influencing financial decisions, legal reasoning, or autonomous systems, “probably correct” starts to reveal its structural fragility. That is the point where the limitation becomes difficult to ignore.
But when AI begins influencing financial decisions, legal reasoning, or autonomous systems, “probably correct” starts to reveal its structural fragility. That is the point where the limitation becomes difficult to ignore.
Hallucination is what people point to.The more structural concern is that correctness never exists outside the model that produces it.
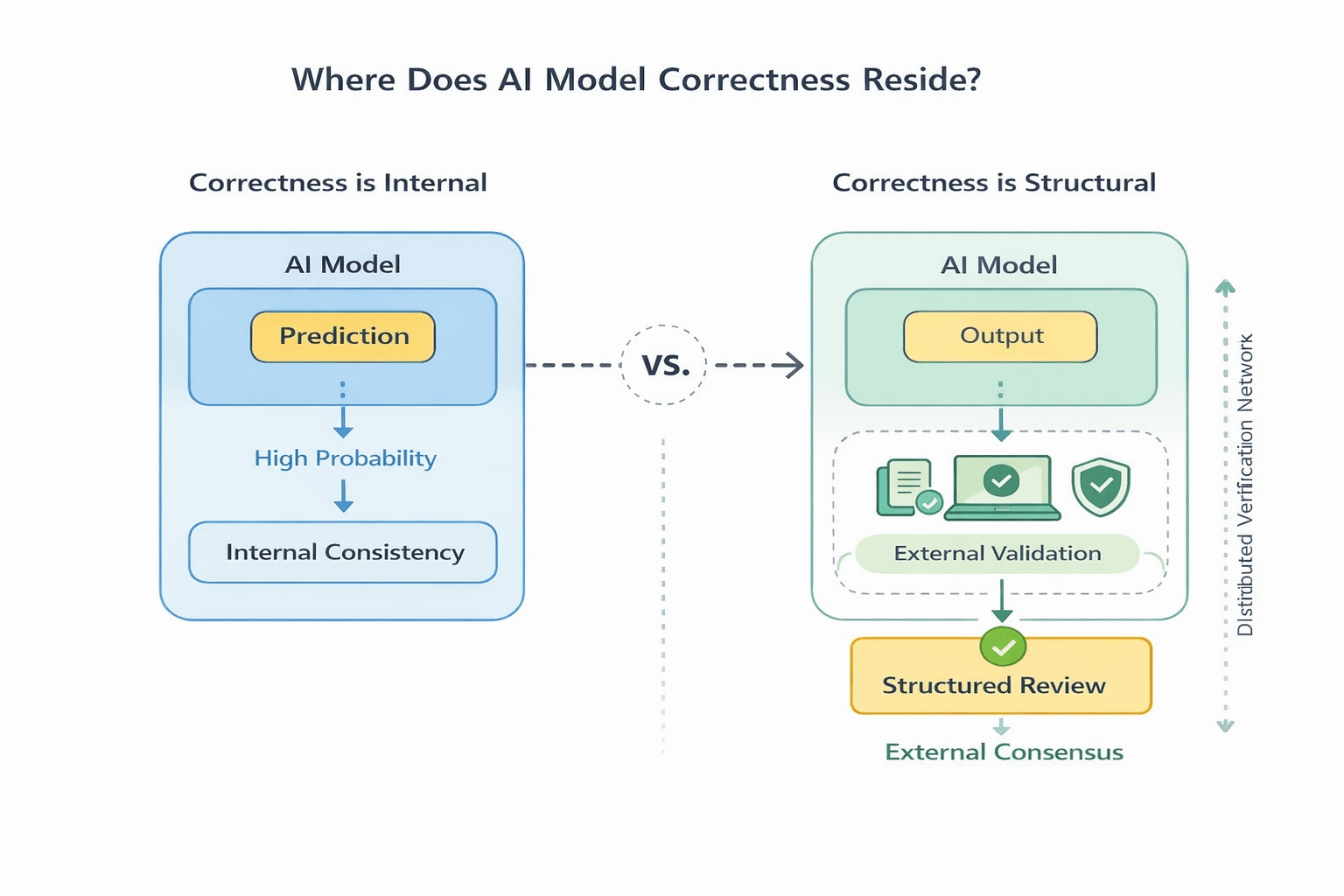
Right now, correctness is a model property. It depends on architecture, scale, training data, and fine tuning. If the model changes, the definition of correct shifts with it. That instability is what stands out.
Mira, as I see it, is built around that specific weakness. That is part of why it stands apart when compared to most adjacent projects.
Instead of accepting a model’s output as final, Mira breaks complex responses into verifiable claims and routes them through a distributed validation process. Independent participants evaluate those claims under defined rules, and agreement forms through structured review rather than model confidence alone.
 Without a system like this, correctness remains internal. Whatever the model predicts with sufficient probability becomes the working answer. With a validation layer, correctness becomes conditional on external agreement.
Without a system like this, correctness remains internal. Whatever the model predicts with sufficient probability becomes the working answer. With a validation layer, correctness becomes conditional on external agreement.
The sequence becomes clear:
The model generates
The network evaluates
Acceptance follows process
This does not make truth automatic. A distributed network can still be wrong.
But if we see properly, here, accountability changes character. Participants are not passive observers. They operate under defined exposure. When a claim passes validation, it is no longer just statistically likely. It has been collectively examined.
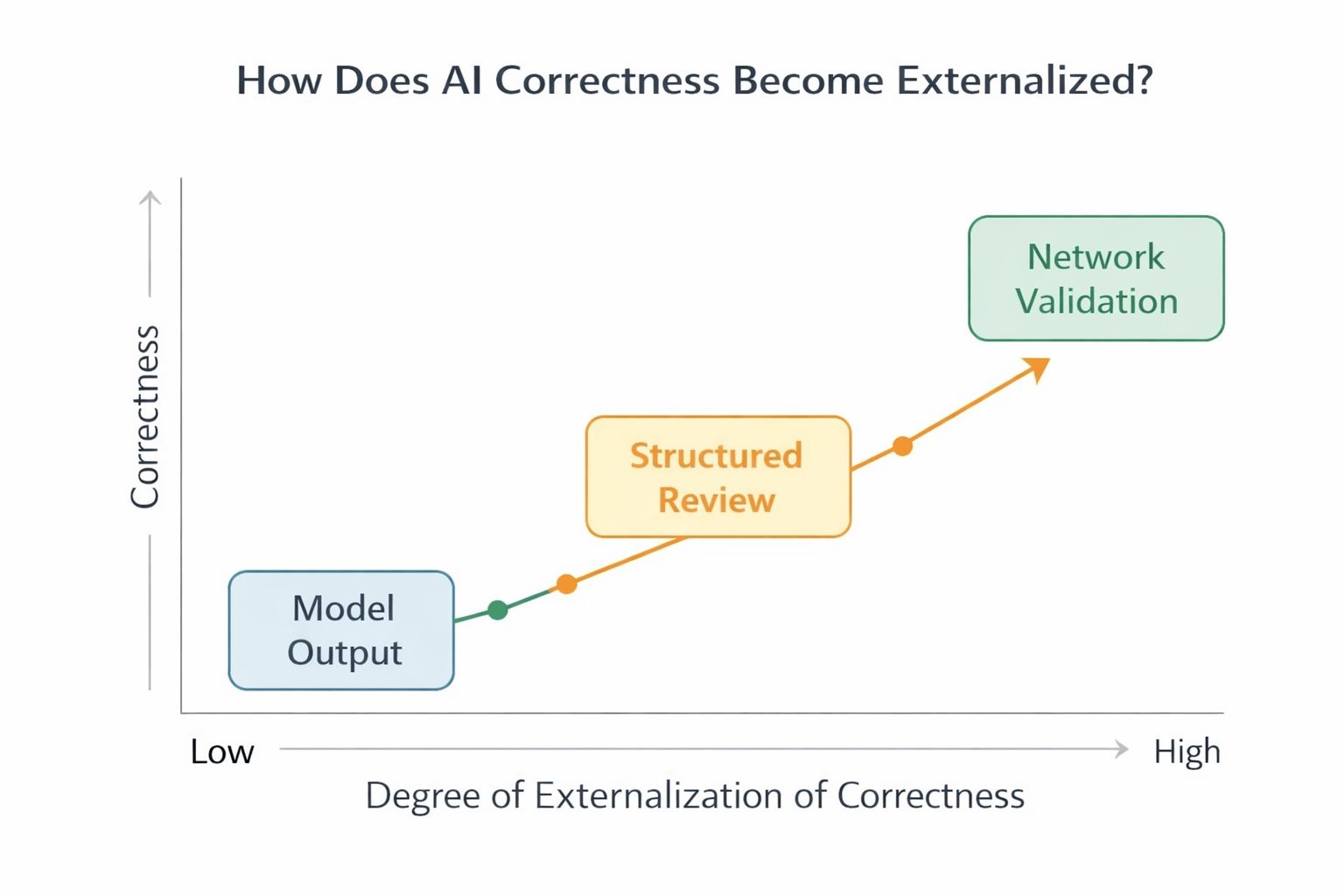
That is where the deeper structural change begins. Correctness moves from being a property of architecture to being embedded within structure. And structure is not bound to a single model release or training cycle. It persists beyond individual iterations.
Over the past few years, most progress has focused on scaling intelligence. Larger models. Better reasoning chains. Improved benchmarks.
That direction makes sense.
But Mira operates on a different axis. It focuses on what happens after the answer appears.
>> Can an output withstand scrutiny beyond its own confidence score? That question keeps resurfacing.
If AI systems are going to operate in environments where consequences are real, correctness cannot remain purely probabilistic.
It has to pass through evaluation. A layer where disagreement can surface and claims can be tested before acceptance.
That unresolved tension sits precisely at that boundary. That is where Mira positions its intervention.
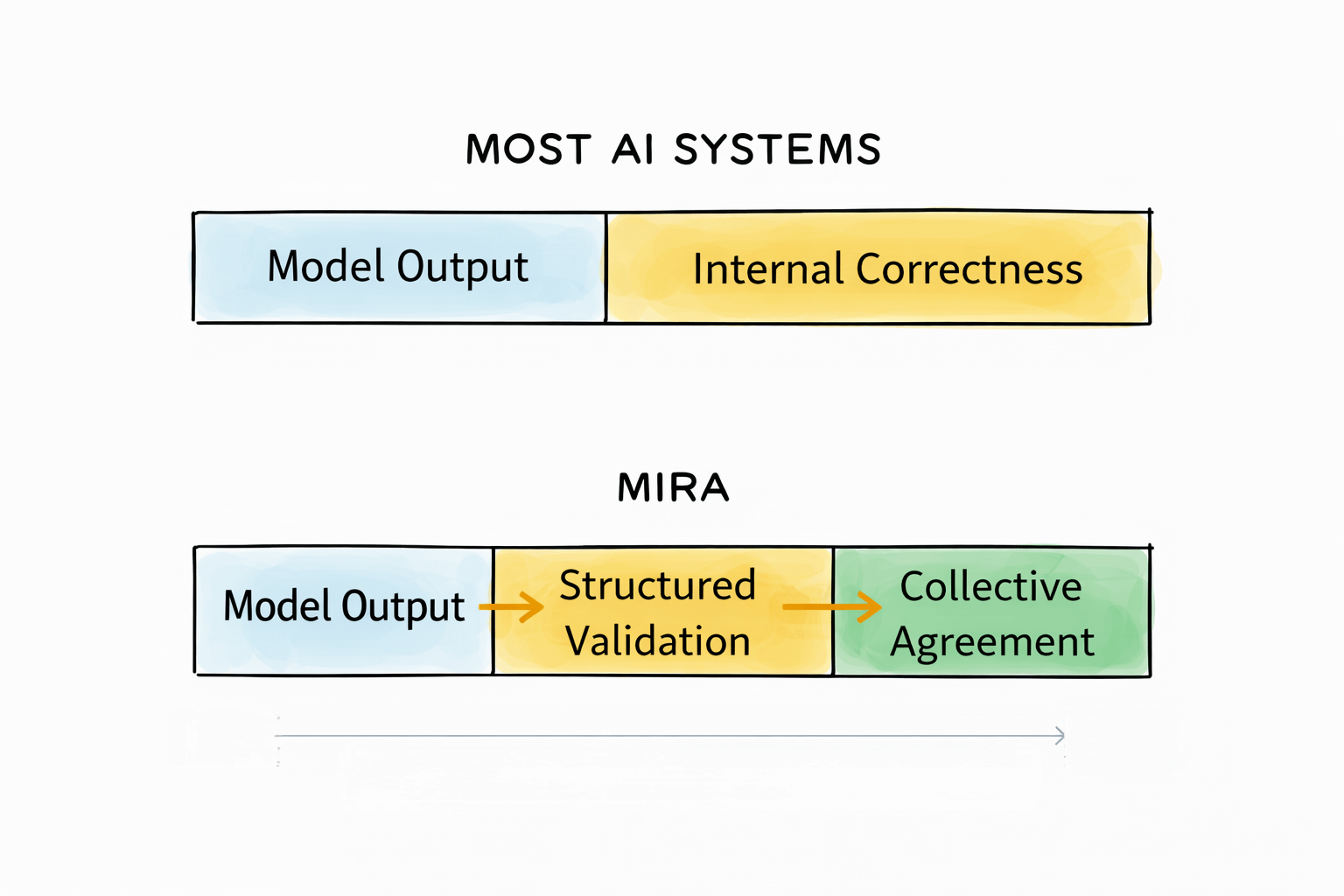 Under Mira, an answer is not the conclusion. It is the point where evaluation begins. The model speaks first. It does not get the final word.
Under Mira, an answer is not the conclusion. It is the point where evaluation begins. The model speaks first. It does not get the final word.
The debate around AI often centers on how powerful models will become. I understand that curiosity.
But a different question feels more immediate.
What defines when a machine is allowed to be considered right?
If that definition shifts, and Mira appears to be nudging it in that direction, then we are not just scaling intelligence.
We are redefining what “correct” means in the first place.
