I used to think that the hallucination problem in artificial intelligence was a permanent architectural flaw that we simply had to live with, but I was research-blind. The common standard in the industry is to rely on human-in-the-loop oversight for every critical output, which most developers defend as the only way to ensure safety. I thought this clunky, manual verification process was just an unavoidable tax on using Large Language Models for professional work. We have been stuck in a tedious cycle where we trade speed for accuracy, or privacy for performance, assuming that a single centralized model could eventually solve its own logic errors through sheer scale.
Mira proves that theory wrong by implementing what they call decentralized content transformation. Instead of a single black-box model guessing at the truth, the network breaks complex content into entity-claim pairs and shards them across a distributed node map. This ensures no single operator sees the whole picture, protecting privacy while the collective network verifies the integrity of the data. It is a clever architectural pivot that keeps sensitive information fragmented while the consensus mechanism handles the truth-seeking. By ensuring that no node operator can reconstruct the complete candidate content, Mira protects customer privacy while maintaining the absolute integrity of the verification process itself. It is the digital equivalent of a high-security vault where three different people hold three different keys; no one can rob the vault alone, and the data only moves when all keys are present.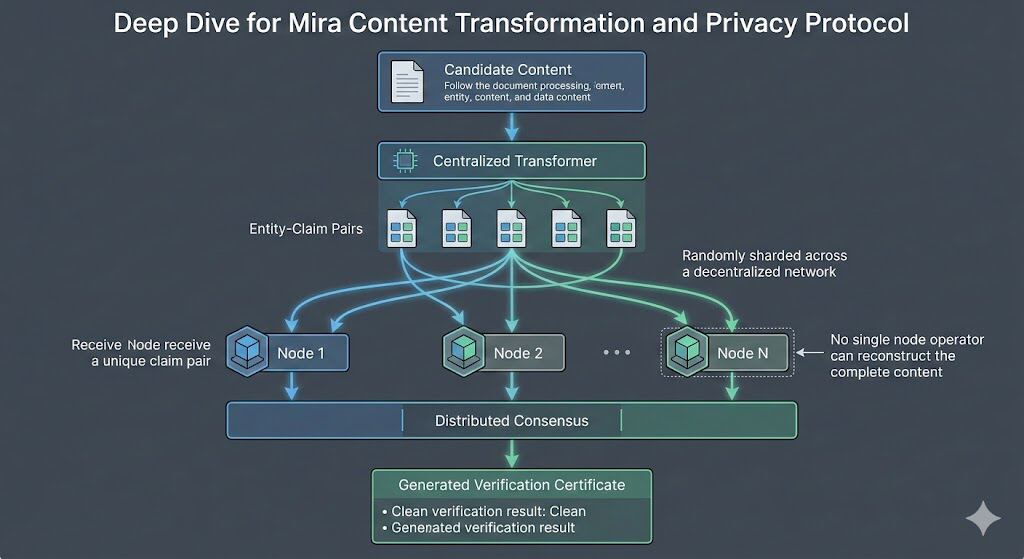
The reason why this is such a big deal is that it finally kills the trade-off between privacy and accuracy. I think it would have been easier for them to just build another centralized filter, but instead, they focused on the actual structural reality of data—that verification must be private to be secure. By keeping node responses hidden until consensus is reached, the network prevents the kind of information leakage that usually plagues collaborative data processing. When consensus is achieved, the network generates certificates containing only the necessary verification details, practicing a form of data minimization that is often ignored in modern AI development. This isn't just another blockchain wrapper; it is a fundamental rewrite of how machines talk to each other.
Mira’s decision to layer this directly onto a crypto-economic incentive structure shows that proof-of-inference is more valuable than traditional proof-of-work. Instead of solving arbitrary puzzles, nodes perform meaningful computations backed by staked value. This means the network doesn't just guess if a statement is true; it creates an economic penalty for being wrong. This establishes a new model for converting raw, unreliable data into value-backed facts. This is the bedrock of what they call economically secured facts on the blockchain, creating a verified knowledge base that can support deterministic fact-checking systems and oracle services. We have been treating AI like a reliable narrator when it is actually a probabilistic engine; Mira is the first project to treat AI with the skepticism it deserves.
I used to believe that AI would always require a "human supervisor" to catch its mistakes, but the progression of this network suggests otherwise. The roadmap moves from simple validity checks to a system where verification is intrinsic to the generation itself. Initially, the network focuses on domains where factual accuracy is critical and bias risks are minimal, such as healthcare, law, and finance. Imagine a medical AI verifying a dosage recommendation against a decentralized ledger of peer-reviewed data before it ever reaches a doctor's screen—that is the level of reliability we are discussing. Over time, it progressively expands to handle increasingly complex content types including code, structured data, and multimedia content. This isn't just about broader coverage; it is a step toward more sophisticated and reliable AI systems that can actually be trusted with high-stakes decision-making.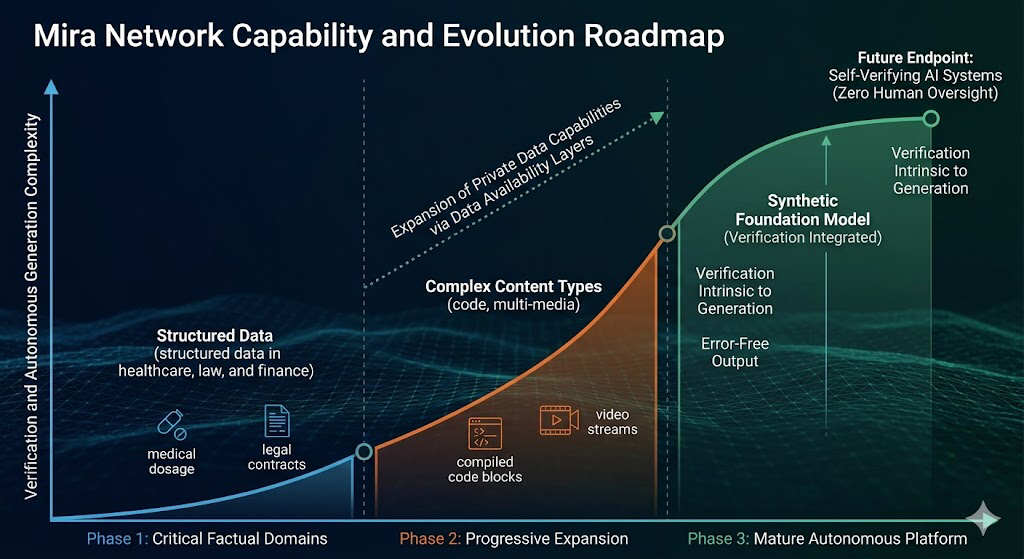
The evolution eventually culminates in a synthetic foundation model that eliminates the distinction between creating and checking. It approaches real-time performance without sacrificing the rigorous standards required by sensitive industries. This represents a fundamental breakthrough because it removes the friction of the "verification lag." By distributing verification across a decentralized network of incentivized operators, Mira creates infrastructure that is inherently resistant to centralized control. This prevents any single entity from becoming the arbiter of truth, which is a significant risk in our current centralized AI landscape.
In the future, I think this will become the default infrastructure for autonomous intelligence. We will stop worrying about whether an AI is "lying" or "hallucinating" because the underlying network will have already verified the output against a decentralized knowledge base. It represents a shift where we stop managing the errors of AI and start focusing on the outcomes of the intelligence itself. Through the continuous evolution of technical capabilities and economic incentives, the network will enable a new generation of AI applications that operate with unprecedented reliability.
This represents more than an incremental improvement; it establishes a new paradigm where error-free operation without human oversight allows AI to finally operate autonomously. While current AI systems excel at generating creative and plausible outputs, they fail at reliability. Mira addresses this by making manipulation both technically and economically impractical. By enabling AI systems to operate without human oversight, we establish the foundation for actual artificial intelligence—a crucial step toward unlocking the transformative potential of this technology across all of society. The old way is dead. We are moving toward a reality where truth is not a suggestion, but a mathematical certainty.
$MIRA @Mira - Trust Layer of AI #Mira
