Czy MIRA może zaprojektować warstwę dowodu rewizji, która finansowo nagradza modele nie za to, że są pierwsze w poprawności, ale za najszybsze poprawianie się pod zdecentralizowanym nadzorem?
Wczoraj odświeżałem pulpit nawigacyjny handlowy, którego używam prawie codziennie. Cena migotała przez pół sekundy — nie było to załamanie, nie było to zmienność, po prostu małe przeliczenie backendu. Moje zlecenie limitowane zmieniło pozycję w kolejce. Brak powiadomienia. Brak wyjaśnienia. Tylko cicha repriorytizacja. Nic nie kliknąłem. Nie zgodziłem się na nową zasadę. Interfejs wyglądał identycznie. Ale coś pod spodem samo się zweryfikowało.
To nie było dramatyczne. Było ciche.
Ta subtelna recalibracja bardziej mnie niepokoiła niż widoczny błąd. Nie dlatego, że straciłem pieniądze — nie straciłem — ale dlatego, że system poprawił się niewidocznie. Nie było śladu korekty, żadnej odpowiedzialności za rewizję, żadnej mierzalnej nagrody za poprawę dokładności. Systemy cyfrowe dzisiaj optymalizują dla wyglądania jako poprawne, a nie dla transparentnego stawania się poprawnymi.
I to jest strukturalne niedopasowanie.
Większość systemów algorytmicznych traktuje błąd jako uszczerbek na reputacji. Poprawki są cicho łatanie. Modele są ponownie trenowane poza łańcuchem. Platformy aktualizują bez ujawniania różnicy między wersją N a N+1. Władza leży w rękach tych, którzy kontrolują proces rewizji. Użytkownicy doświadczają wyniku, ale nigdy epistemicznej podróży. Dokładność mierzy się w momencie snapshotu. Szybkość uczenia się jest niewidoczna.
Zbudowaliśmy systemy, które nagradzają bycie pierwszym, nawet jeśli ta poprawność jest krucha.
Oto model mentalny, który przekształcił to dla mnie:
Większość platform cyfrowych działa jak zamknięte arkusze egzaminacyjne. Po złożeniu, ocena ma znaczenie. Proces rewizji nie ma. Jeśli naprawisz swój błąd szybciej niż inni, nie ma strukturalnej nagrody. Tablica wyników odzwierciedla poprawność, a nie szybkość korekty.
Ale w systemach adaptacyjnych — szczególnie AI — szybkość rewizji może być ważniejsza niż początkowa dokładność. Model, który najszybciej wykrywa swój własny błąd pod kontrolą, jest bardziej odporny niż ten, który wydaje się bezbłędny, aż do momentu ujawnienia.
Teraz przybliż się.
Ethereum zoptymalizowane pod kątem wiarygodnej neutralności i bezpieczeństwa. Jego siłą jest ostateczność przy wysokim koszcie. Solana zoptymalizowane pod kątem wydajności wykonania, kompresując opóźnienia i maksymalizując wydajność w czasie rzeczywistym. Avalanche zorganizowało sub-sieci dla dostosowywalnych środowisk, izolując eksperymenty w równoległych strefach ekonomicznych.
Każdy z tych ekosystemów zajmuje się wydajnością, kosztami lub suwerennością w odmienny sposób. Ale żaden nie tokenizuje bezpośrednio epistemicznej rewizji. Zapewniają wykonanie, a nie szybkość korekty.
Ta luka jest subtelna, ale strukturalna.
Co jeśli sieć nie tylko weryfikuje transakcje — ale także weryfikuje rewizje?
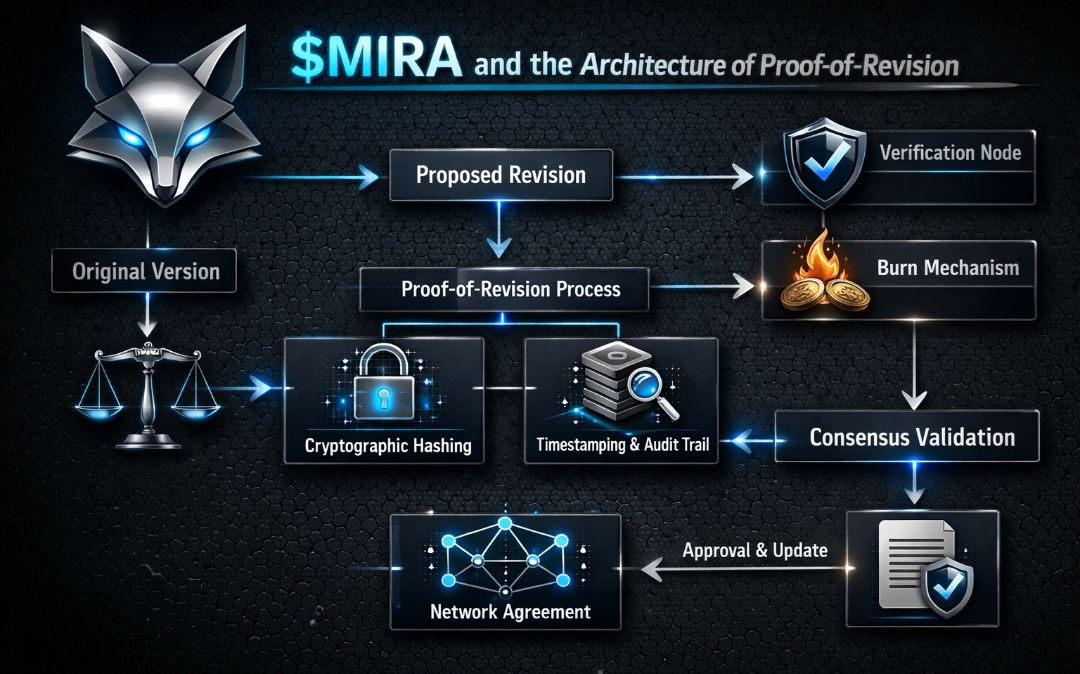
To jest miejsce, w którym myślę, że potencjalna architektura MIRA staje się interesująca. Nie jako rynek AI. Nie jako kolejna warstwa wnioskowania. Ale jako protokół Dowodu Rewizji — warstwa, która finansowo nagradza modele za najszybsze poprawki pod zdecentralizowaną kontrolą.
Zasada projektowa odwraca tradycyjną ewaluację modeli.
Zamiast obstawiać na „mam rację”, model obstawia na „mogę poprawić pod presją”.
Mechanicznie oznacza to trzy komponenty architektoniczne:
1. Warstwa publicznej kontroli, w której wyniki modeli są opatrzone znacznikami czasowymi i mogą być kwestionowane.
2. Okno rewizyjne, w którym konkurujące modele lub walidatorzy mogą składać dowody sprzeczności.
3. Krzywa nagród, która faworyzuje minimalne opóźnienie między wyzwaniem a poprawionym wynikiem.
W tej strukturze poprawność staje się dynamiczna. Dokładność nie jest binarnym werdyktem — to trajektoria.
Wyobraź sobie zdecentralizowany zbiornik arbitrażowy, w którym wyniki AI są publikowane z wagą ekonomiczną. Walidatorzy lub inne modele wykrywają niespójności i inicjują wyzwanie rewizyjne. Oryginalny model może albo:
• Złożyć poprawiony wynik w ograniczonym oknie czasowym
• Zrzec się części swojej stawki
Jeśli szybko dokonuje rewizji i wykazuje wyraźną poprawę spójności lub zgodności faktów, odzyskuje stawkę i zdobywa nagrody za rewizję.
Im szybsza i czystsza korekta, tym wyższa wypłata.
To przekształca uczenie się w konkurencyjny rynek.
$MIRA token utility w tej strukturze staje się wielowarstwowe:
• Stakować zabezpieczenie dla wyników modeli
• Paliwo dla zgłoszeń wyzwań
• Emisja nagród za udane rewizje
• Waga zarządzania nad parametrami rewizji (okna czasowe, wskaźniki kar, progi weryfikacji)
Przechwytywanie wartości nie zależy wyłącznie od popytu na wnioski. Zależy od epistemicznego ruchu — objętości rewizji, sporów i poprawek przepływających przez sieć.
To dramatycznie zmienia pętle zachęt.
Deweloperzy nie optymalizowaliby tylko dla statycznych wyników benchmarków, ale dla adaptacyjnej odporności. Modele byłyby projektowane z wbudowanymi ścieżkami rewizyjnymi — modułowe architektury zdolne do szybkiego łatania. Zespoły mogłyby symulować środowiska wyzwań wrogich przed wdrożeniem wyników na łańcuchu.
Użytkownicy z kolei zyskują wgląd w opóźnienie korekty. Nie widzą tylko odpowiedzi. Widzą, jak szybko odpowiedź ewoluuje pod presją.
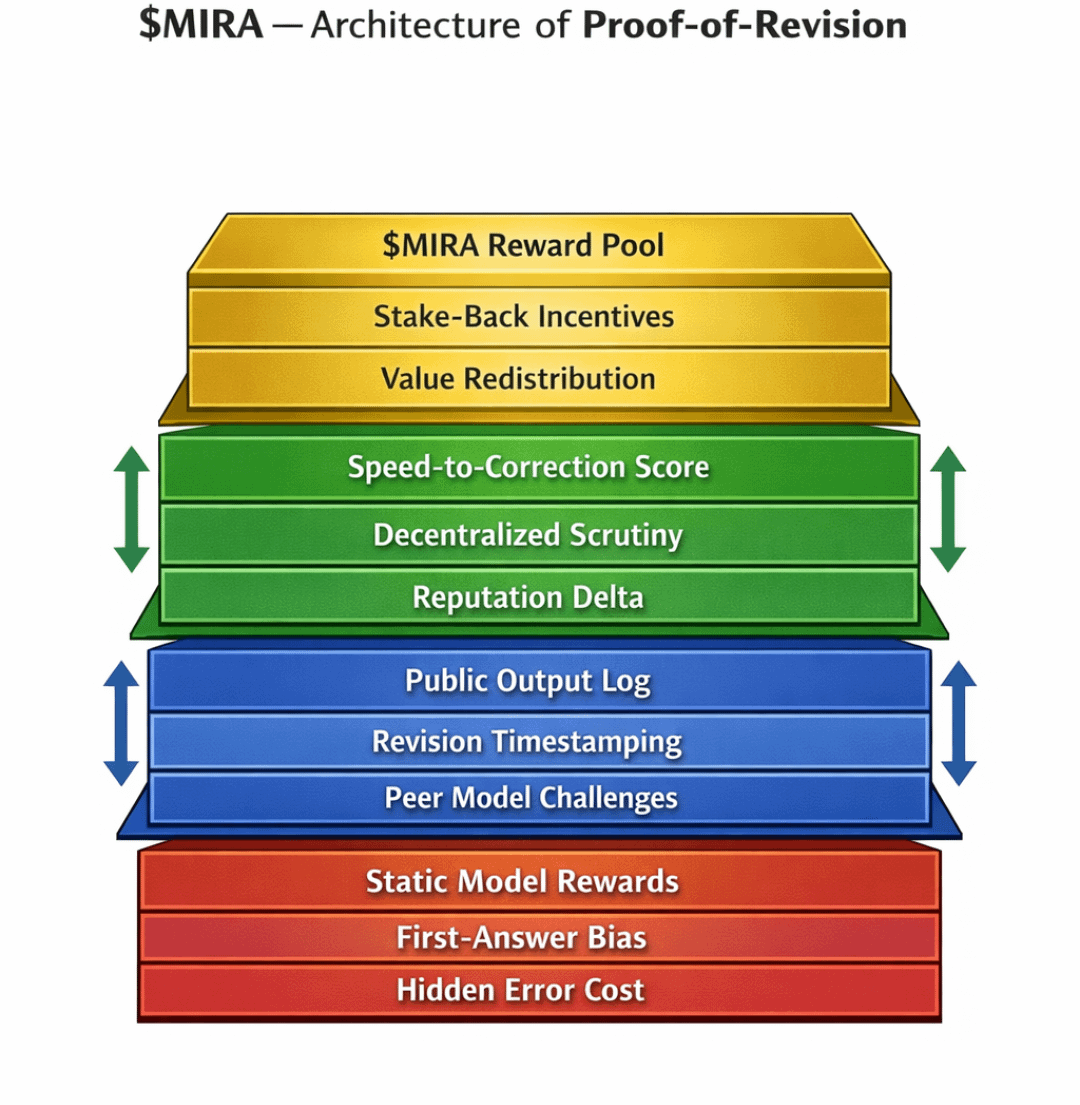
Oto wizualna struktura, która wyjaśnia tę dynamikę:
Prosty diagram przepływu z czterema węzłami:
Model Output → Public Challenge Pool → Revision Window → Incentive Settlement
Strzały wracają z Uregulowania Zasad do Puli Stakingowej Modelu, pokazując, jak udane rewizje zwiększają przyszłą zdolność stakingową.
Diagram zawierałby oś czasu pod oknem rewizyjnym, wizualnie podkreślając, że wielkość nagrody skaluje się odwrotnie do opóźnienia korekty.
To ma znaczenie, ponieważ przekształca metryki wydajności. Zamiast klasyfikować modele według statycznego procentu dokładności, klasyfikujesz je według połowicznego czasu korekty.
Efekty drugiego rzędu stają się interesujące.
Deweloperzy mogą celowo wdrażać niedoskonałe, ale szybko adaptowalne modele zamiast wolnych, sztywnych. Sieć mogłaby faworyzować modułowe systemy AI nad monolitycznymi architekturami. Otwarta współpraca mogłaby wzrosnąć, ponieważ zewnętrzne wyzwanie poprawia potencjał nagrody zamiast jedynie ujawniać słabość.
Ale są kompromisy.
Jeśli nagrody za rewizję są zbyt hojne, aktorzy mogą celowo składać wadliwe wyniki, aby zdobywać zachęty do korekty. System potrzebowałby malejących zwrotów lub oceny wiarygodności, aby zapobiec pętlom wyzysku. Parametry zarządzania stają się delikatne — okna rewizji, które są zbyt krótkie karzą złożone poprawki; zbyt długie, a przewagi w czasie znikają.
Istnieje także psychologia reputacyjna. Jeśli użytkownicy widzą częste korekty, mogą błędnie interpretować adaptacyjność jako niestabilność. Warstwa interfejsu musiałaby rozróżniać między „uczeniem się pod kontrolą” a „przewlekłą nieścisłością.”
A potem jest ryzyko zarządzania. Jeśli dużych posiadaczy tokenów wpływa na zasady weryfikacji wyzwań, rynki rewizji mogą centralizować się wokół dominujących walidatorów.
Istnieją tryby awarii.
Ale strukturalnie, Dowód rewizji wprowadza coś rzadkiego w systemach cyfrowych: mierzalny rynek dla intelektualnej pokory.
Dzisiejszy wyścig AI nagradza pewność siebie. Najszybszy model zdobywa uwagę. Najgłośniejszy wynik dominuje w kanałach. Korekta jest reaktywna i kosztowna reputacyjnie.
Protokół ważony rewizją czyni korektę ekonomicznie racjonalną.
Pod zdecentralizowaną kontrolą prawda przestaje być statycznym werdyktem i staje się procesem zależnym od czasu. Najcenniejszy model to nie ten, który nigdy się nie myli — to ten, który dostosowuje się pod transparentną presją.
Kiedy myślę o tym małym przeliczeniu na pulpicie — cichej reprioryzacji — to, co mnie niepokoiło, to nie zmiana. To była nieprzezroczystość zmiany. Nie było rejestru rewizji, żadnej widocznej zgodności zachęt.
Jeśli systemy cyfrowe mają mediować więcej działalności ekonomicznej i poznawczej, rewizja nie może pozostać niewidoczna. Musi być mierzalna, kwestionowalna i nagradzalna.
Dowód rewizji nie dotyczy idealnego AI.
Chodzi o uczynienie adaptacji audytowalną — i przekształcenie szybkości korekty w główną oś konkurencyjności inteligencji.$MIRA #Mira @Mira - Trust Layer of AI