

I stopped trusting completion metrics six months into a coordination integration. Not because they were wrong. Because they were measuring the wrong moment.
The confirmation window kept growing. Quietly. Nothing dramatic. Just downstream systems learning not to commit until something else confirmed the confirmation.
Not whether agents can act. Whether done remains stable under disagreement.
Completion is only real when it survives challenge.
In robotics and agent coordination completion isn't symbolic. A completed task triggers billing. An approval triggers dispatch. A confirmation triggers settlement. If the system later revises that outcome without a structured path the gap doesn't close itself.
Someone closes it manually.
In most stacks that manual layer grows quietly. First a confirmation window. Then a watcher script. Then an override log. None of it appears dramatic. The system keeps running. Autonomy just becomes supervised.
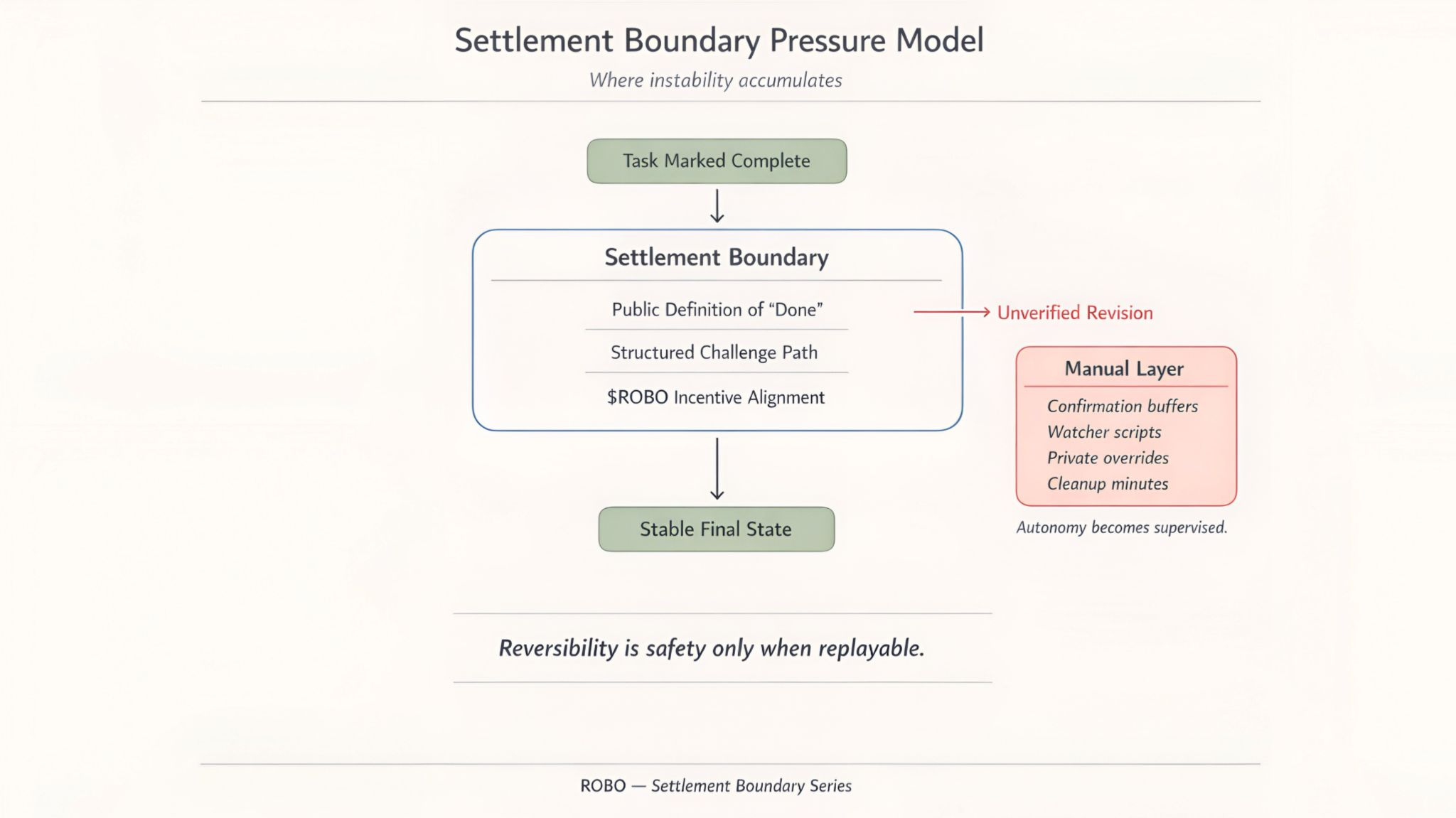
If ROBO matters... it matters at the settlement boundary.
I think about unverified completion in three places where the cost becomes visible under repetition. Dispute rate. Time to stable finality. Resolution legibility.
Dispute rate is the first leak.
Not total volume. Where disputes go. Unstructured disputes settling off-protocol are worse than visible ones. Cleaner on paper. Messier underneath. I'd split by cause. Performance interpretation. Policy change. Scoring adjustment. Operator override. Then watch whether they trend toward structured resolution or disappear into private threads.
If disputes shrink and stabilize, healthy. If they move into shadow processes, unhealthy.
Time to stable finality is the second place the cost surfaces.
Not time to initial success. Time until the outcome can't be reversed without explicit protocol action.
Fast initial success with unstable finality is deferred ambiguity. In cascading systems instability multiplies downstream. Teams respond by inserting delay buffers. That's not resilience. It's institutional hesitation.
I'd measure two numbers. Median close time on uncontested completions. And how far that number moves during the three days after a policy update. If it doubles and stays doubled... teams have already started building around it.
When finality stays tight autonomy stays cheap. When it loosens and sticks the venue is quietly hiring humans.
Resolution legibility is the third place unverified completion becomes either a feature or a tax.
Every dispute needs a stable reason code and replayable path. If reason categories drift or cleanup time grows per dispute the system is teaching manual arbitration instead of automation.
Healthy systems compress reconciliation minutes over time. Unhealthy systems accumulate special cases.
This is the trade that gets mispriced. Reversibility is treated as safety by default. In production coordination reversibility is only safety when it's replayable and externally verifiable. Otherwise it's polite instability.
Only late in the analysis does a token matter. $ROBO doesn't prevent disagreement. It funds the settlement layer that makes disagreement structured. Challenge processing. Proof verification. Incentive alignment for resolution rather than avoidance. If ROBO ever claims value from real robotic coordination finality must become cheaper than hesitation.
I end with the simplest check I know.
Pick a quiet week then an incident week. Watch dispute rate. Watch median close time and how far it moves in the three days after a policy update. Watch whether it comes back or just stays moved.
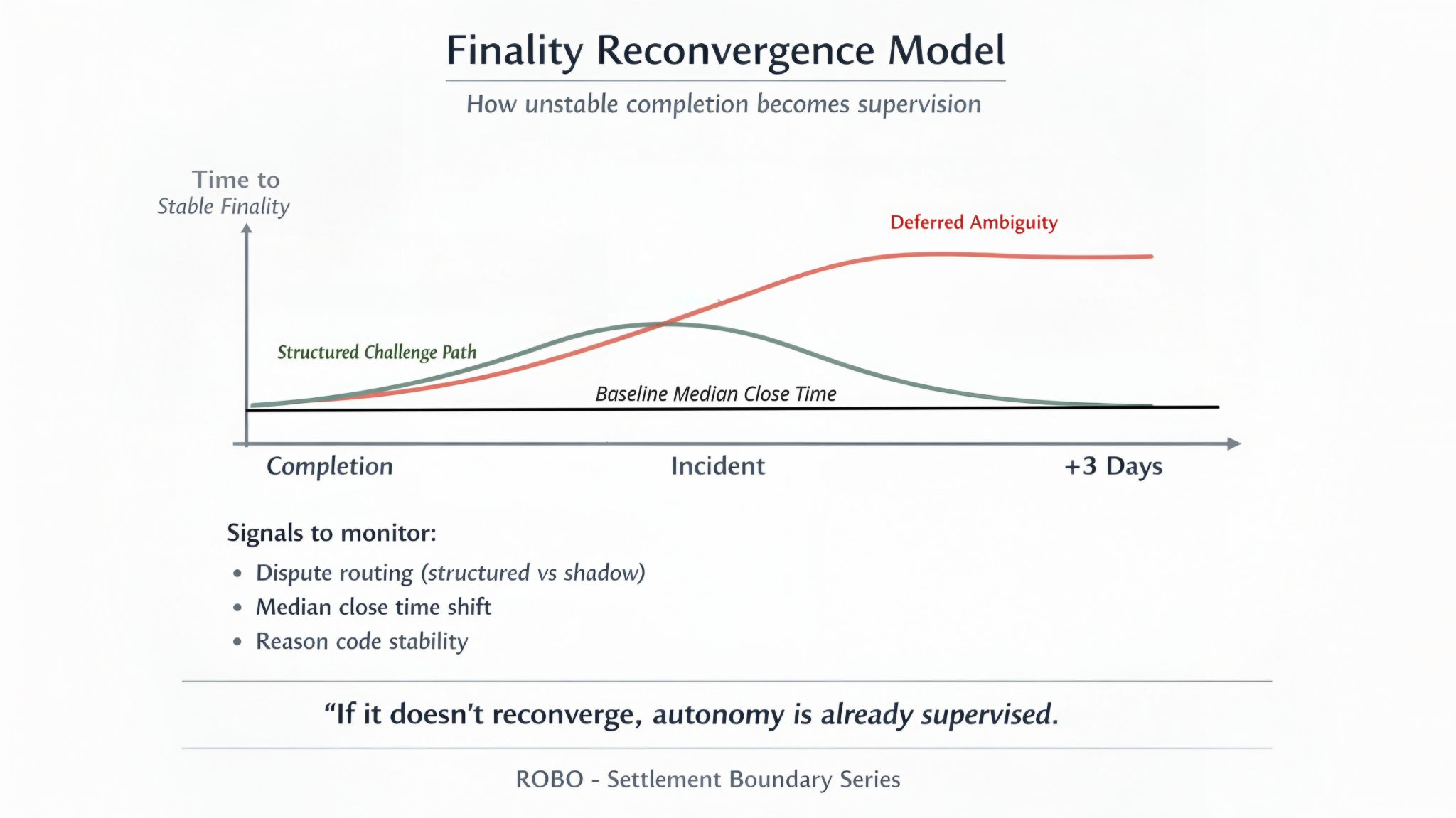
That last part. Whether it comes back. That's the whole test honestly.
In healthy systems incident scars fade and tails collapse. In unhealthy systems buffers persist and supervision grows.
Autonomy doesn't fail loudly. It's more like a slow leak in a system nobody checks because the pressure gauge still reads normal.
By the time anyone notices the manual layer is already load bearing.