

I’ve gotten used to treating AI output as “draft material,” even when it looks confident on the surface. In my day-to-day reading, the failure mode that sticks with me isn’t that models are occasionally wrong, but that the wrongness can be hard to notice until it collides with something real. That gap between plausibility and truth is what makes “verified AI” feel less like a feature request and more like an operational requirement.
The core friction is that a single model has to balance two failure patterns that pull in different directions: hallucinations from overconfident pattern completion, and bias from systematic skew in training data and curation. Pushing a model to be more consistent can narrow its acceptable knowledge range and amplify bias, while widening its scope to reduce bias can raise variance and invite hallucinations. In high-stakes settings, the bottleneck isn’t generation speed or creativity, it’s the absence of a trustless way to separate “sounds right” from “is defensible,” without relying on one authority to decide what counts as true.
It’s like trying to certify the safety of a complex machine using only one inspector who must choose between checking fewer parts thoroughly or checking everything quickly.
MIRA frames a path toward human-free AI by treating verification as a first-class network function rather than a downstream manual process. The main idea is to transform an output into a set of independently checkable claims and then have multiple independent verifiers converge on those claims through decentralized consensus. Instead of trusting a single model’s internal confidence, trust is shifted to a collective decision that is costly to fake and cheap to audit after the fact. “Human-free” here doesn’t mean removing humans from the system’s values; it means reducing the need for humans to supervise each individual answer in real time.
Conceptually, the chain takes candidate content and standardizes the verification target so that different verifier models are answering the same question with comparable context. That standardization matters because naïvely sending an entire passage to many models can produce noisy results: each verifier may latch onto different sub-claims, interpret ambiguity differently, or implicitly assume different missing context. By breaking content down into claim-sized units, the network can measure agreement at the level where disagreement is meaningful, not at the level where it’s mostly interpretive drift.
Mechanically, the workflow starts with a user submitting content along with verification requirements such as a domain constraint and a desired consensus threshold. The network performs a transformation step that decomposes the content into discrete claims while preserving the logical relationships that matter for correctness. Those claims are then distributed across node operators running verifier models, and each node returns structured responses that can be aggregated. The consensus layer treats these responses as inputs to a decision rule, producing a verdict for each claim and a resulting certificate that records what was verified and how consensus was reached.
On the state and execution side, the whitepaper framing is oriented around verification tasks rather than a general-purpose smart contract platform, so it’s not fully clear what account model or VM the base chain uses, or how much logic is on-chain versus in an off-chain execution environment with on-chain commitments. What is clear is the cryptographic posture of the transaction lifecycle: users submit requests, nodes submit signed verification results, and the chain orders and finalizes those submissions into an auditable outcome. Finality assumptions are therefore tied to the chain’s consensus guarantees plus the economic assumptions behind who can influence outcomes.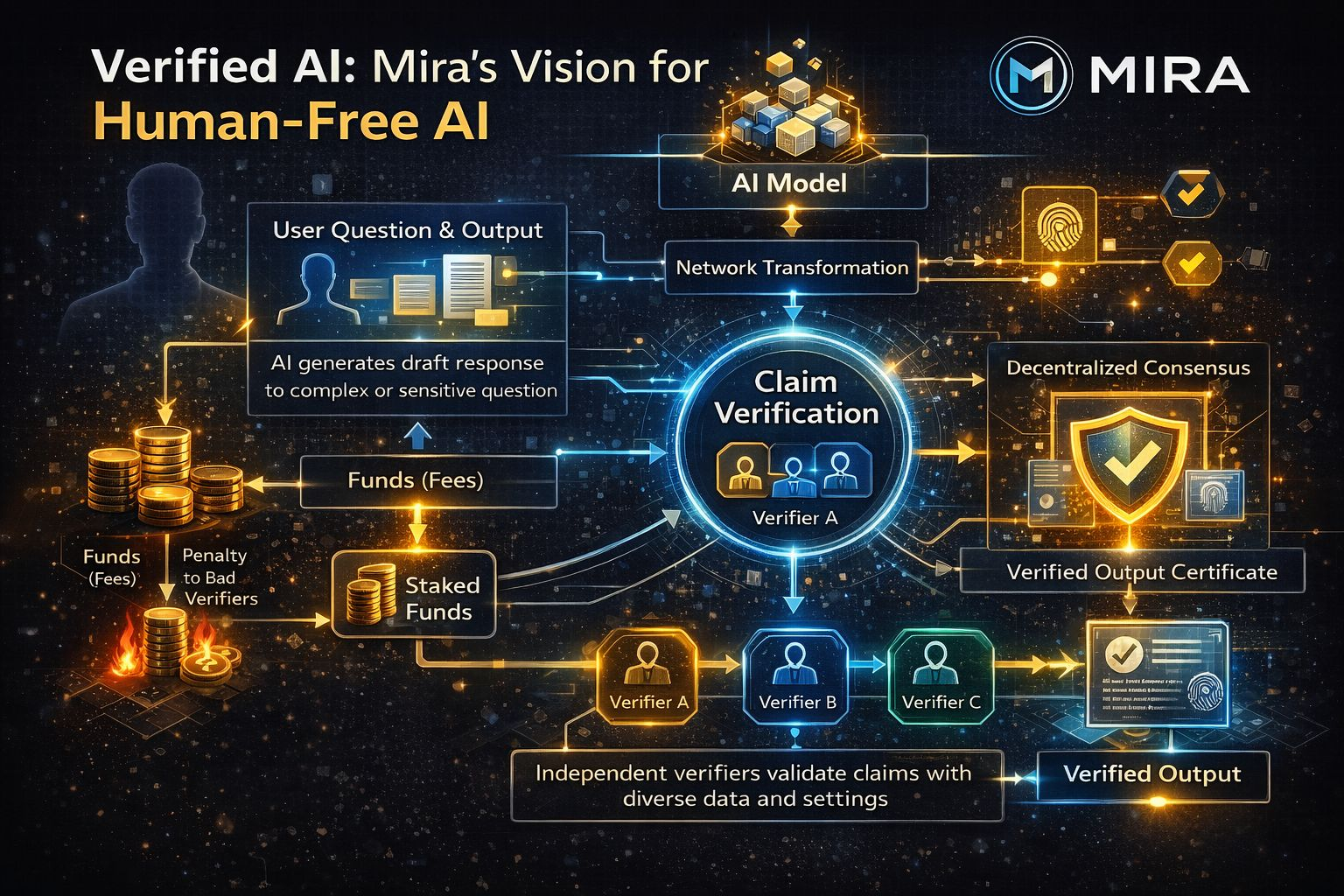
Data availability and storage assumptions are also shaped by privacy goals. The design leans on sharding claim fragments such that no single node learns the full candidate content, which reduces reconstruction risk. That implies a model where the network stores only what is necessary to prove verification occurred—likely commitments, outcomes, and certificates—while keeping sensitive raw content minimized or handled through constrained disclosure. The transformation component is described as becoming more decentralized over time, but the exact cryptographic technique for maintaining privacy under decentralization isn’t fully specified in the excerpt, so I treat that as an open implementation detail rather than a given.
Where the design gets practical is incentives. Verification is structured like constrained-choice inference, which creates an uncomfortable reality: guessing can be statistically attractive if there’s no penalty, because the response space is small compared to typical proof-of-work puzzles. The network counters this by coupling participation to stake and introducing slashing for behavior that deviates from expected honest inference, whether through consistent disagreement with consensus or detectable low-effort patterns. In this setup, fees paid by users fund verification rewards, while staking aligns verifiers with the long-term integrity of outcomes. Governance, if it exists in the mature design, would matter most in defining slashing conditions, acceptable verifier sets, and the evolution of transformation standards without drifting into centralized curation.
Price negotiation shows up here in a neutral way: users and verifiers effectively bargain over verification capacity through fees and reward rates. If verification demand is high, fees signal scarcity and attract more verification work; if demand is low, rewards compress and only efficient verifiers remain active. That market dynamic is less about speculation and more about whether the chain can sustain a stable cost of honesty—high enough to deter manipulation, low enough to be usable for routine verification.
One limitation I can’t resolve from the available material is how the network will handle domains where “truth” is inherently contextual or policy-bound, since consensus can converge on a shared bias as easily as it converges on a fact.
I come back to my opening habit—treating AI as draft—because it’s a rational adaptation to unreliable outputs. A verification-first network doesn’t magically make knowledge perfect, but it can change what it means to rely on an output by making the path from claim to evidence legible and economically defended. If “human-free AI” is ever going to be more than a slogan, it will probably look less like a single brilliant model and more like systems that make correctness the easiest equilibrium, even when nobody is watching.
@Mira - Trust Layer of AI $MIRA #Mira
