I keep circling back to the same question: why does it always feel like financial systems are a mess when it comes to privacy?
I don’t mean messy in the abstract, I mean practically, in the day-to-day. You have users trying to pay bills, send money across borders, or invest in a new fund. You have institutions running huge back-office operations, juggling compliance, settlement, and reporting. You have regulators who need to know the rules are followed but not necessarily every trivial detail of every transaction. And yet, somehow, privacy is always treated like an afterthought a checkbox, a “feature” to turn on if someone complains, rather than the framework around which the system is built.
Take something as mundane as customer onboarding. Banks and brokers ask for mountains of personal data. Often, the user gives it once, and it is then duplicated across systems, databases, and sometimes third-party partners. Each duplication is another point of riskof mistakes, leaks, misuse. And every time a regulator tweaks a rule or demands new reporting, the institution scrambles to update scripts, run audits, and sometimes even share more data than they want. Nobody’s happy: the user feels surveilled, the institution is exposed to liability, and the regulator struggles with too much noise.
Why do most systems feel awkward here? Partly because privacy has been treated as optional. The default assumption is: “collect everything; share selectively; secure it later if possible.” It’s easy to understand why. If you’re building a financial product, the path of least resistance is to collect raw data, because downstream tasks credit scoring, anti-money-laundering checks, tax reporting require it. Designing around privacy from the start is slower, less familiar, and harder to standardize. But the result is a tangle of brittle exceptions, patchwork controls, and endless compliance headaches. In other words, systems work until they fail often spectacularly.
I’ve seen it fail. Large institutions have “compliance islands” where certain departments know rules but have no way to verify what another department has done with the same data. Small fintechs struggle with privacy policies that read fine on paper but collapse under audit. And every time a breach occurs, even a minor one, the financial, reputational, and regulatory costs skyrocket. That’s not theory; it’s operating reality.
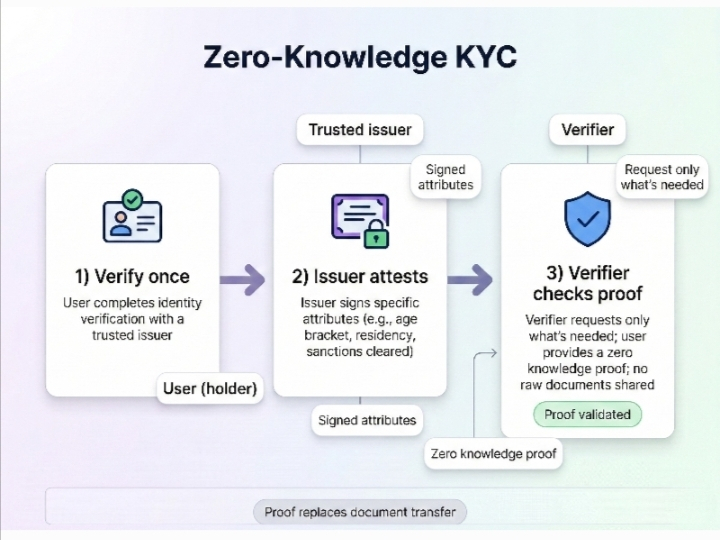
So what would it mean to build privacy by design? Not just a policy or a checkbox, but baked into the infrastructure itself. One way to think about it is like cryptographically verified information. Imagine a system where each piece of sensitive data is split into verifiable claims that can be independently validated without exposing the raw information. Each department, partner, or regulator can confirm compliance or correctness without needing full access to the underlying private details. You don’t hand over the full ledger; you hand over proofs that the ledger is correct.
It sounds abstract, but the implications are concrete. Settlement becomes less risky because you’re not relying on someone else to “honestly” handle private data. Compliance checks can run automatically and consistently, without humans copying, emailing, or printing sensitive records. Even cross-border operations, which are often bogged down by conflicting privacy laws, become more manageable because the system can provide proofs that satisfy multiple regulatory regimes without exposing the underlying personal information.
There’s also a human behavior angle. No matter how strong the encryption or how clever the verification, people will take shortcuts if a process feels cumbersome. If a bank teller, a compliance officer, or a developer can bypass privacy rules to get their job done faster, they often will. Designing privacy into the workflow so that it’s the path of least resistance, not the hardest path is crucial. If the system forces good behavior by default, you reduce the chance of both accidental and intentional misuse.
Of course, none of this is magic. Cryptographic verification and decentralized checks introduce their own complexity. They aren’t free; they require engineering skill, operational discipline, and careful governance. Regulators need to understand what “verified” actually means, or they will distrust it. Systems that claim to protect privacy but are opaque invite skepticism, audits, and possibly rejection. And in finance, the stakes are high: mistakes or misunderstandings can mean billions in exposure, legal action, or worse.
Another practical friction: interoperability. Financial ecosystems are deeply connected. Banks, payment networks, fintech apps, and government systems all speak different languages, maintain different data structures, and enforce different rules. A privacy-by-design system only works if everyone involved adopts it or at least understands its guarantees. Partial adoption leaves gaps and friction points. A proof of correctness is only as useful as the party evaluating it.
So who would actually use something like this, and why might it work? The early adopters are likely the institutions that face the most pain from current privacy practices: multinational banks, clearinghouses, and fintech platforms that operate across jurisdictions. They have the scale and risk exposure to justify investment, and they understand that better privacy design can reduce operational costs, mitigate regulatory fines, and improve customer trust.

But it will fail if it becomes too complex to operate, too opaque for regulators to understand, or too slow to integrate with existing systems. If the proofs are theoretically sound but practically unusable, institutions will fall back to manual workarounds. If the incentives for compliance aren’t aligned with economic reality, it won’t stick. Ultimately, it works only if it fits the messy, human reality of finance not just the idealized world of cryptography or protocols.
Looking at it from a slightly skeptical angle, I would say: this is infrastructure, not magic. It doesn’t make mistakes impossible. It doesn’t remove regulatory ambiguity. It doesn’t fix human error. But if implemented well, it can make mistakes measurable, minimize unnecessary data exposure, and make compliance consistent rather than ad hoc. In that sense, privacy by design is not about eliminating risk entirely it’s about structuring risk in a way that’s visible, verifiable, and manageable.
So maybe the takeaway is simple, if a bit cautious: regulated finance needs privacy built in, because trying to patch it on later always feels awkward and expensive. It works best where there’s a combination of technical rigor, operational discipline, and regulatory understanding. It will fail where adoption is partial, incentives are misaligned, or complexity exceeds comprehension. That’s not a limitation of the concept; it’s just reality. And in a world where AI, automation, and blockchain are increasingly mediating financial flows, those who figure out how to verify correctness without exposing private information first will have a tangible advantage and probably fewer nights spent firefighting compliance issues.
@Mira - Trust Layer of AI #Mira $MIRA