I want to share what happened when I first plugged @Mira - Trust Layer of AI into our production pipeline it wasn’t a smooth, magical upgrade, but more of a series of small, revealing shocks. We were already running AI-generated insights for market trends, and the models were “good enough” most days. Around 82% of the claims they produced aligned with our internal audits, which sounds decent until you scale to thousands per hour. The rest? Slightly misleading statements, overconfident phrasing, or references that didn’t actually check out. That’s where $MIRA entered the stack.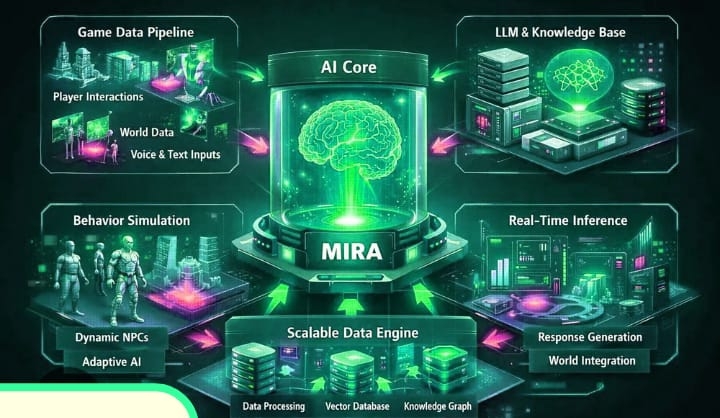
We set up Mira as a middleware verification layer between the AI outputs and the dashboards our team consumes. Each claim generated by the model gets hashed, submitted to decentralized validators, and a consensus score is returned. Early on, the system added roughly 480ms of latency per claim tolerable for our batch workflows but noticeable. We debated whether to aggregate claims for efficiency or keep them separate for granularity. Aggregation was faster by 17%, but individual claim validation caught subtle errors that batching missed. Granularity won, even at the cost of some throughput.
Metrics started revealing patterns we hadn’t seen. About 10% of claims that our internal checks marked as “safe” were flagged by Mira as low-confidence. In practice, these often involved implied causation or probabilistic inference that humans glossed over. Conversely, a few claims that Mira scored low were actually fine; probabilistic evidence isn’t always explicit enough for validators to reach high consensus. That trade-off between caution and speed became a recurring theme in our architecture decisions.
Operationally, the difference was tangible. False alerts decreased by roughly 12%, and retractions of previously published summaries dropped from 3% to 1.2% over a month. The team also engaged differently with AI outputs: seeing decentralized consensus scores made them think in gradients rather than absolutes. I hadn’t expected that psychological effect it’s subtle but real.
Still, I remain skeptical about over-relying on any middleware layer. Decentralized consensus is only as strong as the diversity and honesty of its validators. I monitored node variance closely; when nodes converged too tightly, the risk of systemic bias increased. We also kept fallback procedures for high-frequency operations, where waiting for consensus wasn’t viable.
The practical takeaway is this: Mira doesn’t replace human judgment. It distributes and quantifies trust, making AI claims auditable and traceable. Integrating it forced us to reconsider what “confidence” actually means in a production AI system. Claims are no longer just outputs; they’re objects with measurable, distributed trust scores.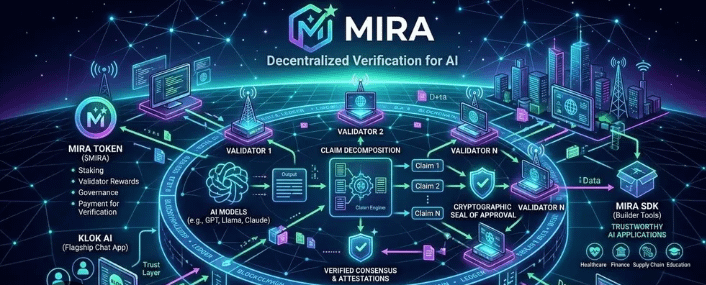
After months of running this setup, I see Mira less as a magic fix and more as a structural adjustment. It adds friction, yes, but friction that prevents blind automation from propagating unchecked errors. My reflection is simple: trust in AI isn’t binary, and decentralizing verification forces you to acknowledge the gray areas. That alone has changed how we build, review, and operationalize AI workflows.