
@Mira - Trust Layer of AI #Mira
I’ve been thinking a lot about how often AI systems sound confident but turn out to be wrong. As someone who follows both crypto infrastructure and machine learning closely, I’ve noticed that the gap between fluency and reliability is still wide. The models can generate complex answers in seconds, yet verifying whether those answers are correct often takes much longer than producing them. That imbalance feels unsustainable if we expect AI to operate in financial, legal, or governance contexts.
The core friction is simple: modern AI is probabilistic, not deterministic. It predicts likely sequences of words based on patterns, not grounded truth. When deployed at scale, small hallucinations compound into large systemic risks. In decentralized systems, where code and data may trigger irreversible transactions, even a minor factual error can have measurable economic consequences. Trusting a single model’s output without verification is efficient in the short term, but fragile over time.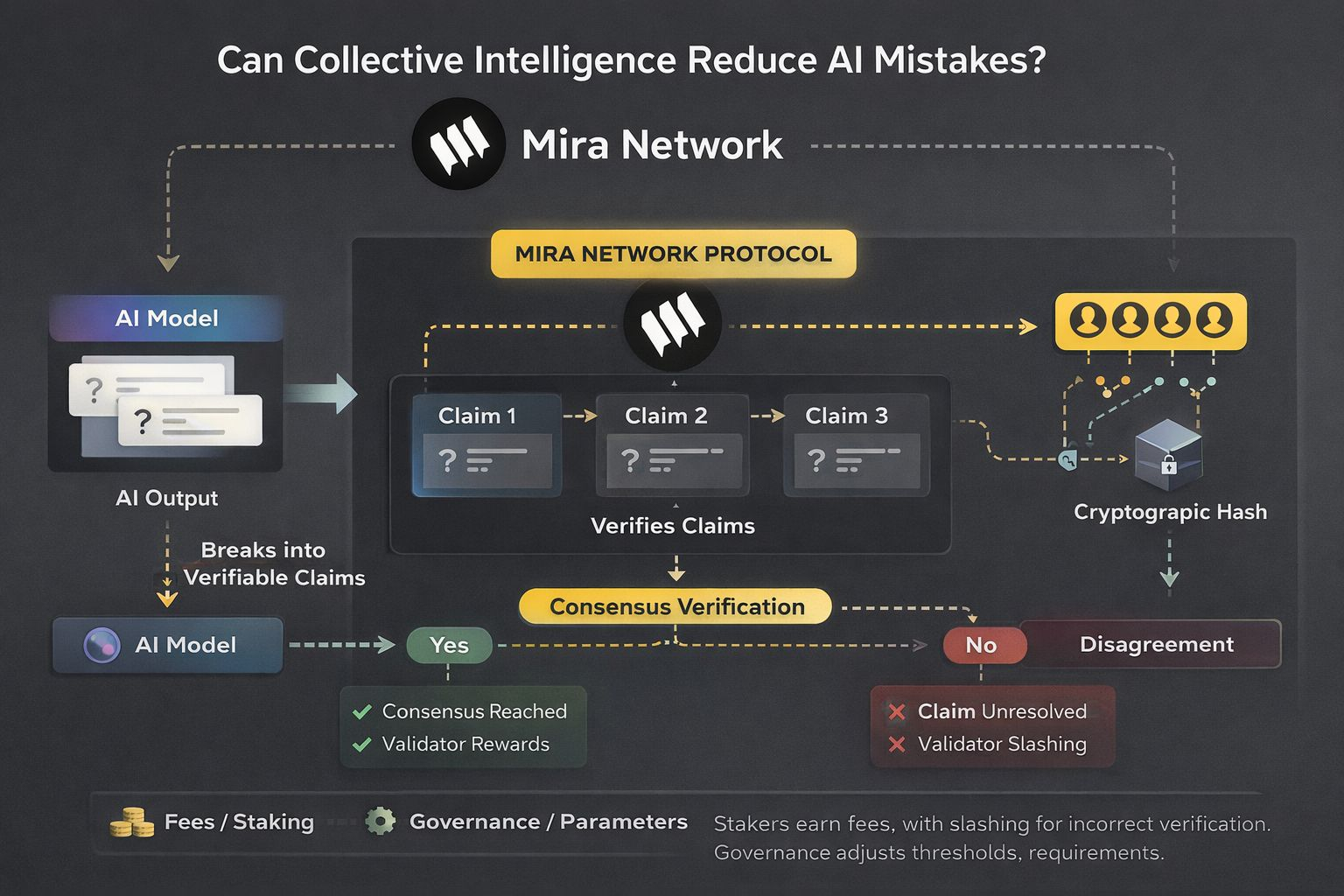
It is like relying on one witness in a courtroom when the stakes are high, instead of cross-examining several independent testimonies.
Mira Network approaches this problem by reframing AI output as a set of claims rather than a monolithic answer. Instead of asking the user to trust a model’s entire response, the network decomposes it into smaller, verifiable units. Each claim becomes an object that can be independently evaluated. This structural change is subtle but important. By breaking down complex responses into atomic statements, the chain can apply consensus logic to each component, rather than treating the whole answer as a black box.
At the consensus layer, validators are selected based on staking participation and predefined performance parameters. They do not retrain the model; instead, they verify claims against structured references or alternative model outputs. Selection is designed to reduce collusion risk by randomizing validator assignment per verification round. The state model records each claim as a discrete state transition, linking it cryptographically to its original AI output. If consensus reaches a predefined threshold, the claim is marked as verified; if disagreement persists, it is flagged and remains unresolved in the state tree.
The model layer is modular. It allows different AI engines to generate responses while separating generation from verification. This distinction is critical because it prevents the verifying actors from being the same entity that produced the claim. The cryptographic flow binds every claim to a hash of the original output and metadata, creating an immutable audit trail. Over time, this produces a ledger of validated AI statements, which can be referenced by downstream applications that require higher assurance levels.
Utility within the network ties directly to this verification economy. Participants stake tokens to act as validators, earning fees when they contribute to accurate consensus outcomes. Incorrect or malicious validation can result in slashing, aligning economic incentives with careful review. Governance mechanisms allow stakeholders to adjust parameters such as consensus thresholds, validator requirements, and fee distribution. This introduces a negotiation dynamic between security and efficiency: higher thresholds increase reliability but raise verification costs, while lower thresholds improve speed but reduce certainty.
Price formation, in this context, is less about speculation and more about usage intensity. If applications depend on verified AI claims for settlement or automation, demand for staking and verification services could increase. At the same time, excessive fee structures might discourage integration. The equilibrium will likely emerge from how developers weigh the cost of verification against the cost of AI errors. That tradeoff cannot be predefined; it evolves with real-world adoption patterns.Still, uncertainty remains. Collective intelligence can reduce mistakes, but it cannot eliminate ambiguity inherent in language or incomplete data. Consensus may confirm that multiple validators agree, yet agreement does not automatically equal truth if all parties rely on similar flawed references. The network attempts to diversify verification inputs, but systemic biases in training data or shared information sources can persist beyond protocol design.
There is also a practical limitation tied to scalability. As AI outputs grow longer and more complex, the number of atomic claims increases. Verifying each claim independently requires computational and coordination resources. Optimization techniques and batching mechanisms can mitigate this, but unforeseen technical constraints may appear as usage scales. The architecture assumes that decentralization and economic incentives can sustain high verification throughput, yet that assumption will only be tested under real transactional load.
Even with these open questions, the underlying idea feels grounded. Instead of replacing trust with blind automation, the network introduces structured doubt and formalized review. Collective intelligence here is not a vague concept; it is encoded into validator selection, staking mechanics, and cryptographic record-keeping. Whether it can meaningfully reduce AI mistakes depends on disciplined implementation and honest governance. But the attempt to align probabilistic intelligence with deterministic verification is, at minimum, a step toward making AI outputs less fragile in decentralized systems.
@Mira - Trust Layer of AI #Mira #mira $MIRA
