That night I wasn’t looking for innovation. I was looking for reassurance.
The logs were scrolling steadily across my screen, nothing dramatic, just the quiet rhythm of a system doing what it was designed to do. Then an operation failed. Not catastrophically. Not silently. It failed cleanly. The error message wasn’t decorative. It wasn’t vague. It told me exactly what happened, why it happened, and what would happen next.
And I remember leaning back in my chair, feeling something I hadn’t felt in a while during system observation calm.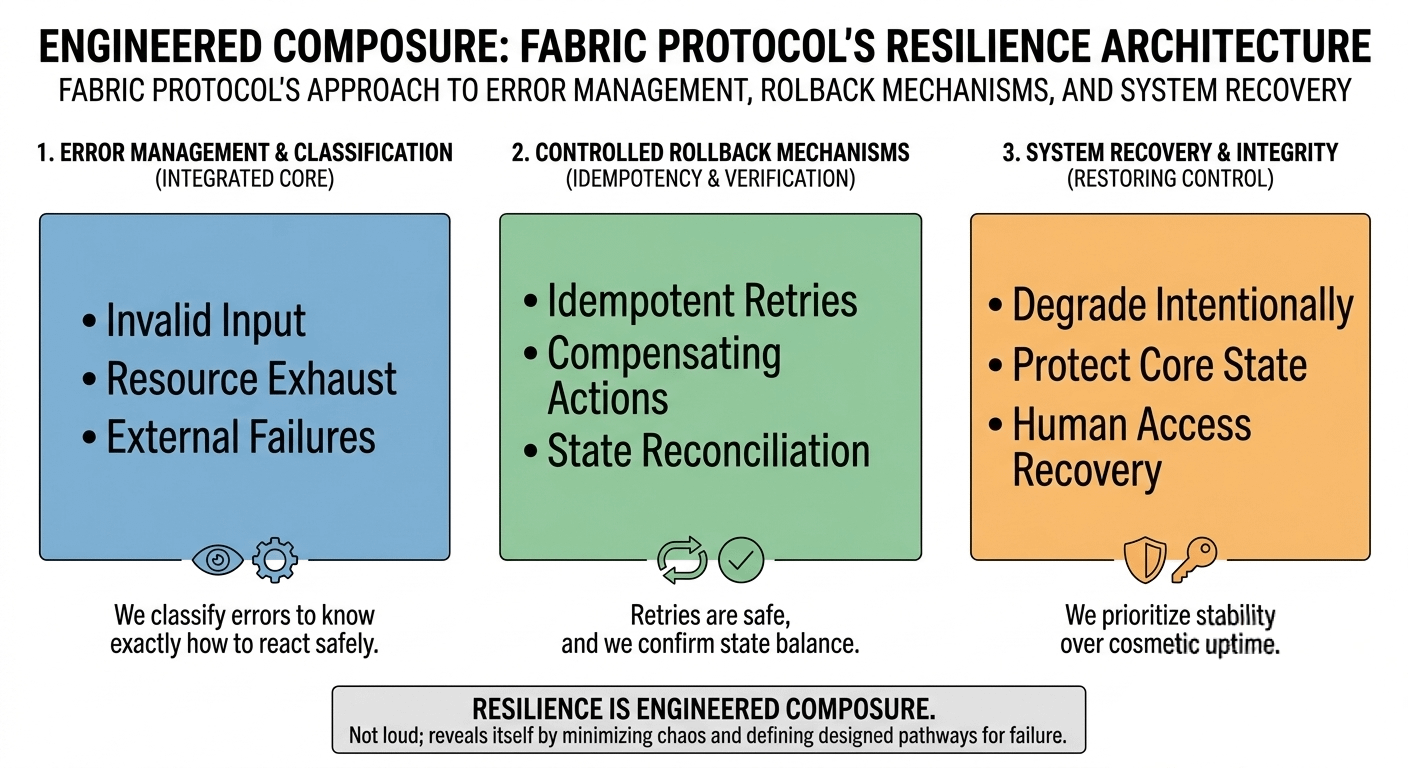
After enough cycles in this industry, you stop being impressed by speed benchmarks and theoretical throughput. What stays with you are the incidents. The moments when something breaks at 2 a.m., when retries multiply risk, when no one is sure whether state was committed or partially written. That is when architecture reveals its character.
What caught my attention about @Fabric Foundation was not how it executes when everything goes right. It was how deliberately it behaves when something goes wrong.
Most systems treat error handling as a defensive layer something that exists to shield the surface. But in Fabric’s design philosophy, error management feels integrated into the operational core. Errors are not aesthetic responses. They are structured signals. They differentiate between invalid inputs, exhausted resources, and external dependency failures in a way that informs decision-making. That distinction matters more than people realize. When you can clearly see whether a request failed before execution or after partial state mutation, your response changes entirely. Panic is replaced with procedure.
And procedure is what protects systems from human overreaction.
Rollback is where things usually deteriorate. I’ve seen more damage caused by blind retries than by initial faults. A transaction times out, uncertainty creeps in, someone resubmits, and suddenly there are duplicate entries or conflicting state transitions. The problem isn’t the first failure it’s the ambiguity around it.
Fabric foundation emphasis on idempotent operations shifts that dynamic. When user intent is designed to produce a single authoritative outcome regardless of repetition, retries stop being dangerous. They become safe. Rollback stops being a desperate reversal mechanism and becomes a controlled exception. That philosophical difference is subtle, but operationally enormous.
Because rollback, if we’re honest, is rarely a clean rewind. In distributed environments, actions propagate. Dependencies react. Logs record. Simply “undoing” an operation is often impossible without introducing new inconsistencies. What matters is whether compensating actions are traceable and verifiable. Fabric’s approach suggests that rollback is not considered complete until reconciliation confirms state alignment. That post-rollback verification discipline is what separates a contained incident from a slowly spreading inconsistency.
But recovery extends beyond transactions.
True recovery is about restoring control. A mature system knows when to degrade intentionally instead of collapsing unpredictably. It knows how to shed load, restrict high risk paths, and protect core state integrity while external dependencies fluctuate. A protocol that prioritizes cosmetic uptime over consistency is quietly borrowing risk from the future.
What I find reassuring is that Fabric’s architecture appears to favor integrity over appearance. If forced to choose between temporary limitation and silent state corruption, the bias seems clear. And that bias tells you something about long term thinking.
There is also the uncomfortable reality of human error. Lost credentials. Misconfigured permissions. Mistaken environment execution. These are not theoretical risks; they are routine operational hazards. A recovery philosophy that does not account for human fragility is incomplete. Structured access recovery, traceable revocation, and controlled reissuance processes are not glamorous features, but they determine whether a mistake becomes an incident or a disaster.
Watching Fabric’s structured handling of these layers error classification, safe retries, compensating rollback, reconciliation, and controlled recovery I began to realize something.
Resilience is not loud.
It does not announce itself through marketing language. It reveals itself in how little chaos follows a fault.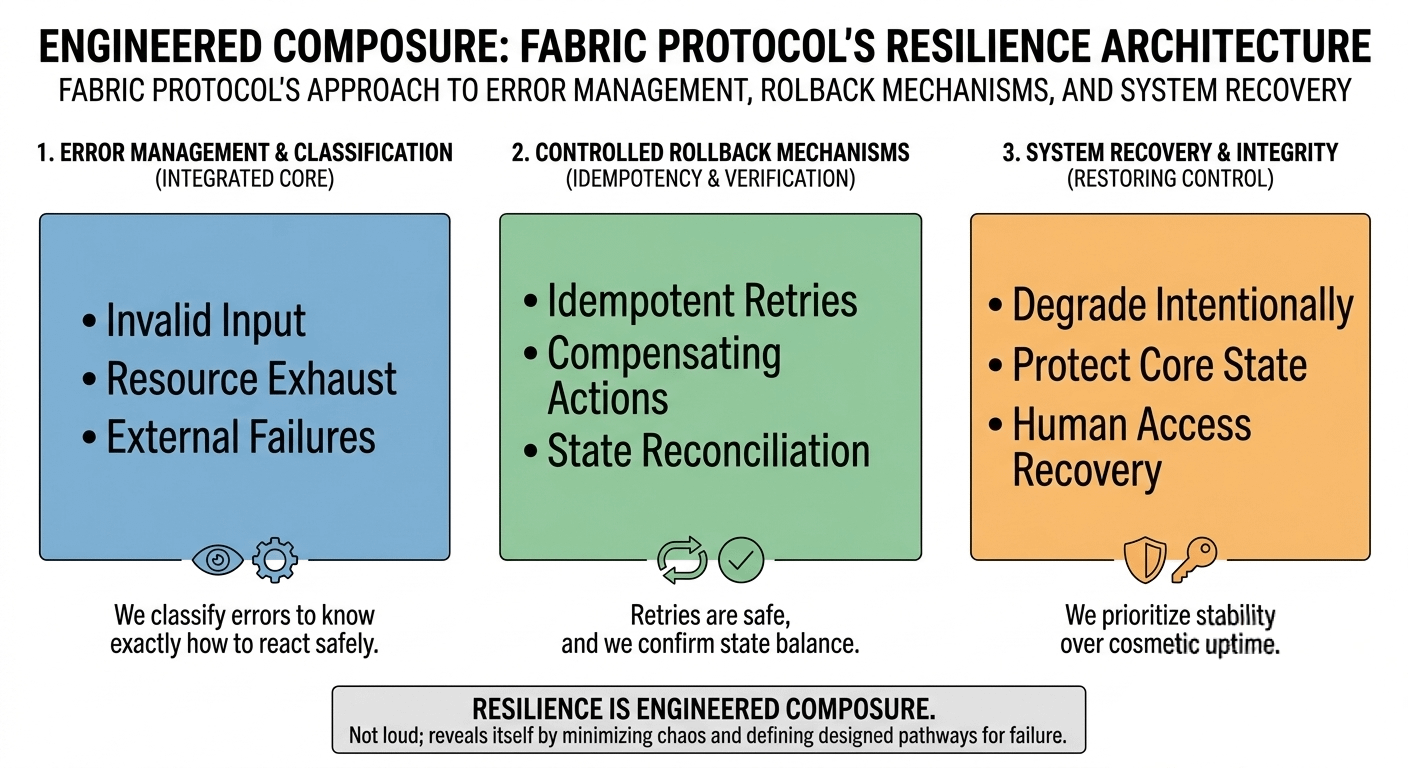
In crypto infrastructure, trust is rarely built during peak performance. It is built during constraint congestion, dependency failure, governance tension, security events. The question is never whether a system will fail. The question is whether failure has a designed pathway.
That is the shift I felt that night in front of my screen. Not excitement. Not hype. Just composure.
And in this industry, composure is engineered not promised.