When I hear “multi model validation” my first reaction isn’t that it sounds advanced. It sounds overdue. Not because ensemble systems are new but because we’ve spent the last few years pretending that scaling a single model was the same thing as increasing reliability. It isn’t. Bigger answers aren’t the same as verified answers.
That’s the quiet shift inside Mira Network’s design. It doesn’t treat intelligence as something you trust because it sounds confident. It treats it as something you validate because it can be wrong.
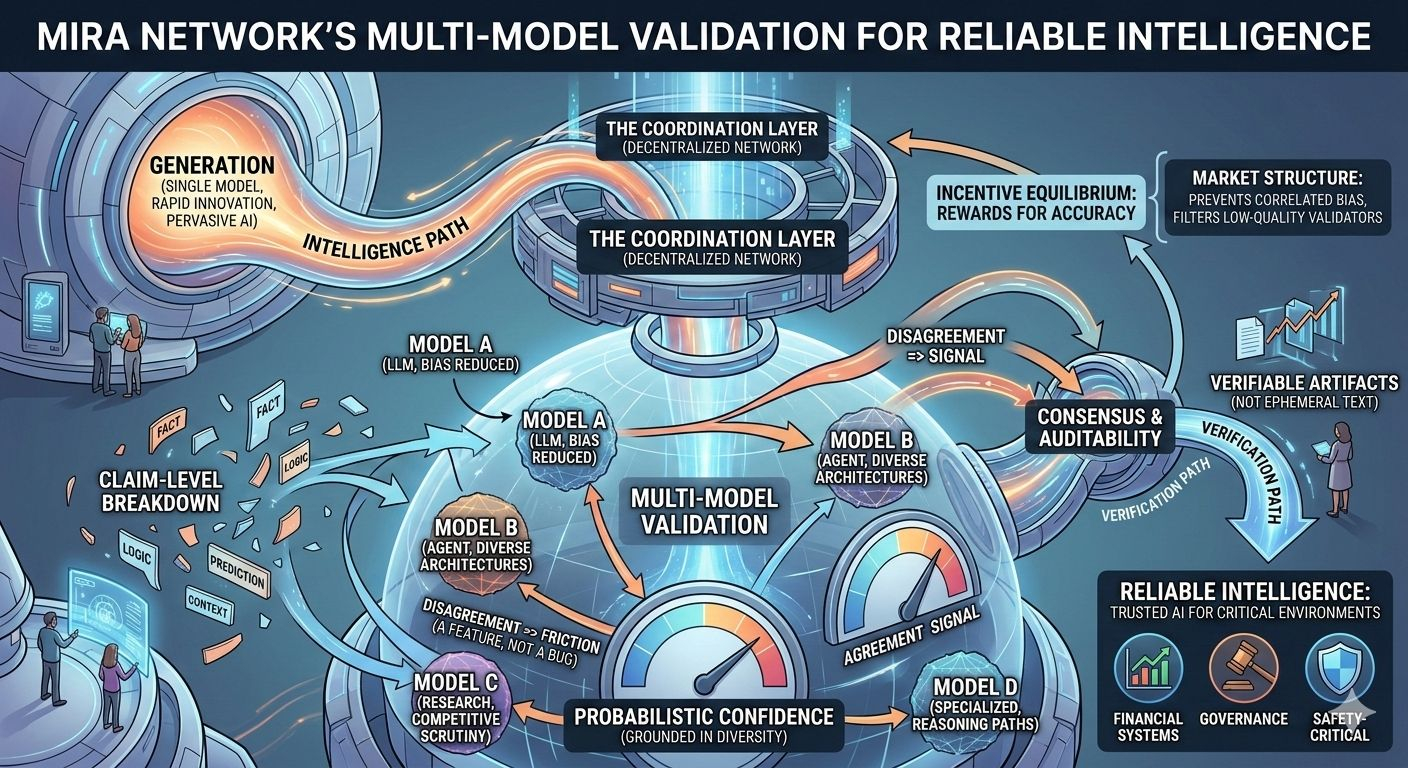
Most AI systems today operate like black boxes with persuasive language. If the output looks coherent, we accept it. If it’s wrong, we blame the model version, tweak prompts or add guardrails. But structurally the trust assumption doesn’t change one system generates and we hope it behaves.
Multi model validation flips that responsibility. Instead of one model producing an answer that gets shipped downstream outputs are broken into discrete claims. Those claims are then evaluated across multiple independent models. Agreement becomes signal. Disagreement becomes friction. And friction in this context is not a bug it’s a feature because reliability isn’t about eliminating uncertainty. It’s about exposing it.
When multiple models evaluate the same claim you introduce a form of competitive scrutiny. Each model becomes a checker of the others. The result isn’t majority opinion for its own sake it’s probabilistic confidence grounded in diversity. Different architectures, training data biases and reasoning paths reduce the risk that a single blind spot dominates the outcome but the deeper change isn’t just technical. It’s architectural.
By routing validation through a decentralized coordination layer Mira turns model agreement into something closer to consensus. Validation isn’t happening inside a single provider’s infrastructure. It’s happening across a network where results can be logged, verified and audited. That transforms AI outputs from ephemeral text into verifiable artifacts.
Of course consensus doesn’t magically eliminate cost. Multiple evaluations mean more computation. More computation means more coordination. Somewhere in that pipeline, incentives have to align who submits claims who validates them how disputes are resolved and how malicious or low quality validators are filtered out. This is where multimodel validation stops being a research concept and becomes market structure.
If validators are rewarded for accuracy the system encourages disciplined evaluation. If they’re rewarded for speed or volume quality can degrade. If participation is too centralized correlated bias creeps back in. Reliability in this design isn’t a static property it’s an incentive equilibrium and like any equilibrium it behaves differently under stress.
In calm conditions models tend to agree on straightforward claims. Consensus looks strong. But the real test appears in edge cases ambiguous data, adversarial prompts, fast moving events. That’s when disagreement spikes. The question then becomes how does the system handle divergence? Does it surface uncertainty transparently? Does it delay execution? Does it assign confidence scores that downstream applications can interpret rationally?
Because multi model validation only improves reliability if applications actually respect the signal.
If downstream systems treat “validated” as binary yes or no they may ignore nuanced confidence gradients. But if they integrate probabilistic outputs into risk models, pricing engines or autonomous agents validation becomes infrastructure. It stops being a badge and starts being a control layer.
There’s another subtle shift here accountability. In singlemodel systems failure is easy to misattribute. Was it the training data? The prompt? The deployment wrapper? In a multi model framework disagreement becomes traceable. You can see which models diverged which validators flagged issues and how consensus was reached. That auditability doesn’t just improve debugging it changes trust dynamics. Users aren’t asked to believe. They’re shown the verification path.
That transparency however introduces its own competitive layer. Validators with stronger performance histories gain reputation. Models that consistently align with validated truth gain weighting. Over time, reliability becomes something measurable and marketable.
This is why I don’t see Mira’s multi model validation as just a safeguard against hallucinations. I see it as a structural attempt to separate intelligence generation from intelligence verification. Generation can innovate rapidly. Verification can remain disciplined. The two don’t have to move at the same speed.
And that separation matters if AI is going to operate autonomously in financial systems governance layers or safety critical environments. Confidence without verification scales risk. Verification without diversity collapses into circular validation. Multi model coordination attempts to balance both.
The long term value of this design won’t be judged by how often models agree in normal conditions. It will be judged by how the network behaves when incentives are tested when adversarial actors try to game consensus when market volatility pressures latency when validators face correlated errors. In those moments reliability is no longer theoretical It’s operational.
So the real question isn’t whether multi model validation improves answer quality. It’s whether the incentive structure coordination logic and transparency mechanisms are strong enough to keep reliability intact when conditions are messy.
Because in the end intelligence isn’t powerful because it can generate. It’s powerful because it can be trusted.
@Mira - Trust Layer of AI $MIRA #Mira #USCitizensMiddleEastEvacuation #MarketRebound $TOWNS

