
„Myślę, że to już teraz. Myślę, że osiągnęliśmy AGI.” To były słowa Jensena Huanga w podcaście Lexa Fridmana, które wstrząsnęły społecznością AI i ponownie wznieciły najważniejszą debatę w sztucznej inteligencji: czy osiągnięto sztuczną ogólną inteligencję?
Jednak CEO Nvidia celowo unikał jakiejkolwiek rzetelnej wyjaśnienia, badań czy debaty na temat tego, co tak naprawdę oznacza AGI. Jego definicja AGI to czysta wydmuszka: system AI, który może zbudować firmę wartą 1 miliard dolarów. Tylko to. Większość definicji AGI odnosi się do dopasowania szerokiego zakresu ludzkich umiejętności poznawczych. Dla Jensena Huanga inteligencja równa się implicitnie skali. Z większymi modelami, większą ilością parametrów, więcej danych i większymi obliczeniami, systemy będą stawać się bardziej zdolne. Z tego punktu widzenia inteligencja jest produktem ubocznym ilościowej ekspansji.
Hipoteza Skalowania: Dlaczego większe modele AI nie oznaczają mądrzejszej AI
Zakładamy, że to podejście przyniosło niezaprzeczalne postępy. Modele dużej skali wykazują imponującą wydajność w szerokim zakresie zadań, często przewyższając ludzkie benchmarki w wąskich dziedzinach (Bommasani i in., 2021). Jednak wielokrotnie wskazaliśmy, że to podstawowe założenie jest kruche: zwiększona pojemność nie przyniesie ogólności.
Ograniczenie nie jest jedynie praktyczne, ale strukturalne. Skalowanie poprawia wydajność w znanych rozkładach, ale nie gwarantuje spójnego zachowania poza nimi (Lake i in., 2017). Wzmacnia to, co już istnieje; nie reorganizuje systemu. Jak podkreśliło badanie IBM, dzisiejsze LLM wciąż mają trudności z fundamentalnymi zadaniami rozumowania: przewidują, ale nie rozumieją naprawdę.
W rezultacie te systemy często wykazują znany wzór: silna lokalna kompetencja połączona z globalną niespójnością. Mogą rozwiązywać złożone problemy, a jednocześnie zawodzić w prostych. Mogą generalizować w niektórych kontekstach, a w innych upadają. Problem nie leży w braku zdolności, lecz w braku integracji. Dlatego debata o skalowaniu AGI w 2026 roku nasiliła się: obliczenia są fizyczne, a skalowanie osiągnęło malejące zwroty.
Ramy poznawcze Google DeepMind do mierzenia postępów AGI
Druga pozycja, wyrażona w ostatnich ramach przez Google DeepMind, definiuje inteligencję jako multidimensionalny konstrukt składający się z zdolności poznawczych, takich jak percepcja, pamięć, uczenie się, rozumowanie i metakognicja. O wiele lepiej…
Z tego punktu widzenia postęp w kierunku AGI można mierzyć, oceniając systemy w ramach zestawu zadań zaprojektowanych do badania każdej z tych zdolności (Burnell i in., 2026). Ale jak są projektowane zadania? Czy trenujemy AI pytaniami i odpowiedziami, które napotkają w badaniach?
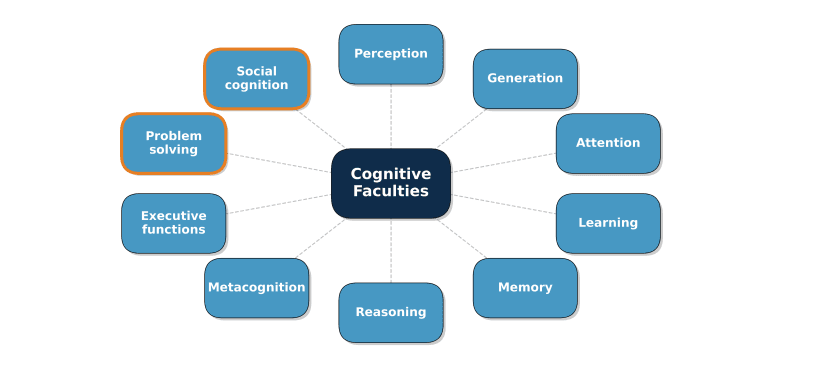
Źródło: Burnell, R. i in. (2026). Mierzenie postępów w kierunku AGI: Ramy poznawcze. Google DeepMind. Zobacz artykuł (PDF)
Przynajmniej to podejście uznaje, że inteligencja nie jest jedną skalarną wielkością, lecz złożonym zestawem interakcji zdolności, osadzonym w dziesięcioleciach pracy w naukach poznawczych (Carroll, 1993; Cattell, 1963).
Dlaczego same profile poznawcze nie mogą definiować sztucznej ogólnej inteligencji
Jednak ograniczenie leży w tym, jak te zdolności są traktowane. Chociaż ramy uznają ich interakcję, ostatecznie oceniają je jako oddzielne komponenty, budując 'profil poznawczy' mocnych i słabych stron.
To wprowadza krytyczne i zaskakujące zniekształcenie.
Ponieważ inteligencja nie jest sumą zdolności. To, co wyłania się, gdy te zdolności są zorganizowane pod jedną dynamiczną. W rzeczywistości czynnik g, jak wyjaśniliśmy w naszym pierwszym naukowym dokumencie podstawowym, pokazuje wyraźną hierarchię. Komponenty organizują się w warstwy!
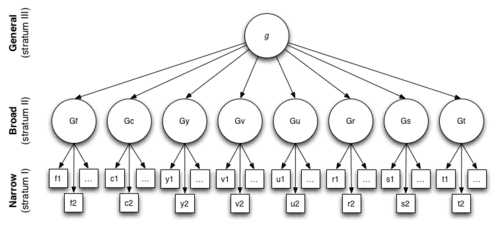
Źródło: Sanchez, J. i Vivancos, D. (2024). Podróż Qubic AGI: Inteligencja ludzka i sztuczna: W kierunku AGI z Aigarth. Zobacz artykuł na ResearchGate
System może zdobywać wysokie oceny w wielu dziedzinach i nadal nie zachowywać się inteligentnie w ogólnym sensie. Nie dlatego, że brakuje mu zdolności, ale dlatego, że te zdolności nie są spójnie zintegrowane. Ramy DeepMind celowo unikają wskazywania, jak te procesy są implementowane, koncentrując się zamiast tego na tym, co system może zrobić. To sprawia, że jest użyteczne jako narzędzie benchmarkingowe, ale niewystarczające jako teoria inteligencji. Jakoś wydaje się, że firmy zajmujące się AI zapominają, co wiemy o inteligencji przez wiek: czym ona jest, jak ją mierzyć, jakie są komponenty, obszary i ich interakcje.
Problem najsłabszego ogniwa: Dlaczego średnia wydajność AI ukrywa krytyczne awarie
Kluczowym problemem jest to, że wydajność jest mierzona, ale organizacja nie.
I to prowadzi do głębszego problemu: słabość systemu leży w najsłabszym ogniwie jego łańcucha. System może działać dobrze w ujęciu ogólnym, a jednocześnie systematycznie zawodzić w określonych wymiarach, takich jak utrzymanie kontekstu czy stabilność. Te awarie nie są marginalne. Definiują system.
System, który rozumuje, ale nie potrafi utrzymać kontekstu, który się uczy, ale nie potrafi transferować, który generuje, ale nie potrafi weryfikować, nie jest częściowo inteligentny. Jest strukturalnie ograniczony. A to ograniczenie nie pojawia się w uśrednionych profilach, ponieważ uśrednianie maskuje punkt awarii.
W prawdziwej inteligencji nie ma tolerancji dla wewnętrznej nieciągłości. W momencie, gdy jeden komponent przestaje integrować się z innymi, zachowanie przestaje być ogólne i staje się lokalne (Kovacs i Conway, 2016).
To właśnie ten wzór obserwujemy w obecnych systemach AI: wysoko rozwinięte zdolności, które są słabo połączone. Jak zbadaliśmy w naszym dogłębnym porównaniu biologicznych i sztucznych sieci neuronowych, luka między rozpoznawaniem wzorców a prawdziwą integracją poznawczą pozostaje ogromna.
Podejście Qubic: Inteligencja jako adaptacyjna organizacja w warunkach niepewności
Dla Qubic/Aigarth/Neuraxon inteligencja nie jest definiowana przez liczbę zdolności, jakie ma system, ani przez to, jak dobrze radzi sobie w zdefiniowanych zadaniach, ale przez to, jak się zachowuje, gdy już nie wie, co robić. Bo to jest kwintesencja inteligencji: co robisz, gdy nie wiesz, co robić.
W tym sensie inteligencja jest zasadniczo procesem adaptacyjnym w warunkach niepewności (Bereiter, 1995). To spojrzenie jest zgodne z klasycznymi definicjami, w których inteligencja rozumiana jest jako zdolność do rozwiązywania nowych problemów, budowania modeli wewnętrznych i działania na ich podstawie (Goertzel i Pennachin, 2007). Ale rozszerza je, podkreślając substrat, w którym te procesy zachodzą.
Dowody biologiczne: Czynnik G, sieci mózgowe i integracja poznawcza
Z tej perspektywy, inteligencja wyłania się z organizacji systemu, a nie z jego komponentów. Dowody biologiczne wspierają tę zmianę. Ogólny czynnik inteligencji (g) nie jest wyjaśniany przez izolowane moduły poznawcze, lecz przez efektywność i integrację sieci mózgowych na dużą skalę (Jung i Haier, 2007; Basten i in., 2015). Inteligencja silniej koreluje z wzorcami połączeń i skoordynowaną aktywnością niż z wydajnością poszczególnych regionów.
Nasze badania nad konektomem muszki owocowej dodatkowo wzmacniają tę zasadę: nawet w najprostszym kompletnym mapowaniu mózgu, jakie kiedykolwiek stworzono, inteligencja zaczyna się od architektury. Konektom Drosophila pokazuje, że część inteligencji może tkwić w strukturze jeszcze przed wystąpieniem uczenia.
Aigarth i Multi-Neuraxon: Architektura AI inspirowana mózgiem dla prawdziwego AGI
Architektury takie jak Aigarth i Multi-Neuraxon próbują zoperacjonalizować ten pomysł. Zamiast maksymalizować skalę lub wyliczać zdolności, koncentrują się na tym, jak wiele współdziałających jednostek (Sfery, kanały oscylacyjne i dynamiczne mechanizmy bramkowania) mogą produkować spójne zachowanie w różnych kontekstach (Sanchez i Vivancos, 2024).
W tych systemach inteligencja nie jest z góry zdefiniowana. Nie jest zakodowana w modułach ani oceniana jako lista zdolności. Wyłania się z interakcji między komponentami, które same są adaptacyjne, czasowo zorganizowane i wzajemnie ograniczone. Jak badamy w Neuraxon Intelligence Academy, te sieci włączają neuromodulację, plastyczność wieloskalarową i bramkowanie astrocytów, zasady bezpośrednio zaczerpnięte z neuronauki, aby stworzyć systemy z wewnętrzną ekologią, a nie tylko mocą obliczeniową.
Ważne jest, że to podejście bezpośrednio odnosi się do problemu ignorowanego przez pozostałe dwa: integracja. Pytanie o świadomość AI a inteligencja dodatkowo oświetla tę różnicę: system, który integruje wiele skal, utrzymuje dynamiczną stabilność i ewoluuje bez utraty spójności, stanowi znacznie mocniejszą podstawę dla ogólnej inteligencji.
Wnioski: Dlaczego debata o AGI musi wyjść poza hype i benchmarki
Ponieważ w zorganizowanym systemie, awaria w jednym komponencie propaguje się przez całość. Dlatego ani ekonomiczna definicja Jensena Huanga, ani profilowanie poznawcze DeepMind nie uchwytują istoty sztucznej ogólnej inteligencji. Droga do AGI nie prowadzi przez większe klastry GPU ani dłuższe listy zdolności poznawczych. Prowadzi przez fundamentalną reorganizację sposobu, w jaki budowane są systemy AI: od optymalizacji do organizacji.
Musimy przejść od optymalizacji (LLM) do organizacji (Aigarth). Mocno wierzymy, że to jest jedna z najważniejszych zmian w przyszłości sztucznej inteligencji.
Referencje naukowe
Basten, U., Hilger, K., i Fiebach, C. J. (2015). Gdzie inteligentne mózgi się różnią: ilościowa meta-analiza funkcjonalnych i strukturalnych badań obrazowania mózgu dotyczących inteligencji. Inteligencja, 51, 10–27. https://doi.org/10.1016/j.intell.2015.04.009
Bereiter, C. (1995). Właściwości transferu. Nauczanie na Transfer: Wspieranie Generalizacji w Uczeniu, 21–34.
Bommasani, R., Hudson, D. A., Adeli, E. i in. (2021). O możliwościach i ryzykach modeli podstawowych. arXiv preprint arXiv:2108.07258. https://arxiv.org/abs/2108.07258
Burnell, R., Yamamori, Y., Firat, O. i in. (2026). Mierzenie postępów w kierunku AGI: Ramy poznawcze. Google DeepMind. Zobacz artykuł
Carroll, J. B. (1993). Ludzkie zdolności poznawcze: przegląd badań analizy czynnikowej. Cambridge University Press. https://doi.org/10.1017/CBO9780511571312
Cattell, R. B. (1963). Teoria inteligencji płynnej i skrystalizowanej: krytyczny eksperyment. Journal of Educational Psychology, 54(1), 1–22.
Goertzel, B. i Pennachin, C. (2007). Sztuczna inteligencja ogólna. Springer.
Jung, R. E. i Haier, R. J. (2007). Teoria integracji parieto-frontalnej (P-FIT) inteligencji. Behavioral and Brain Sciences, 30(2), 135–154. https://doi.org/10.1017/S0140525X07001185
Kovacs, K. i Conway, A. R. A. (2016). Teoria pokrywania procesów: zjednoczone podejście do ogólnego czynnika inteligencji. Psychological Inquiry, 27(3), 151–177. https://doi.org/10.1080/1047840X.2016.1153946
Lake, B. M., Ullman, T. D., Tenenbaum, J. B. i Gershman, S. J. (2017). Budowanie maszyn, które uczą się i myślą jak ludzie. Behavioral and Brain Sciences, 40, e253. https://doi.org/10.1017/S0140525X16001837
Sanchez, J. i Vivancos, D. (2024). Podróż Qubic AGI: Inteligencja ludzka i sztuczna: W kierunku AGI z Aigarth. Preprint. Zobacz na ResearchGate