
Szczerze mówiąc, to brzmi trochę dziwnie na początku.
Większość ludzi wciąż myśli o AI jako o narzędziu. Pytasz, ono odpowiada. Dajesz mu zadanie, ono pomaga. Łączysz je z workflow, a może zaoszczędzi trochę czasu.
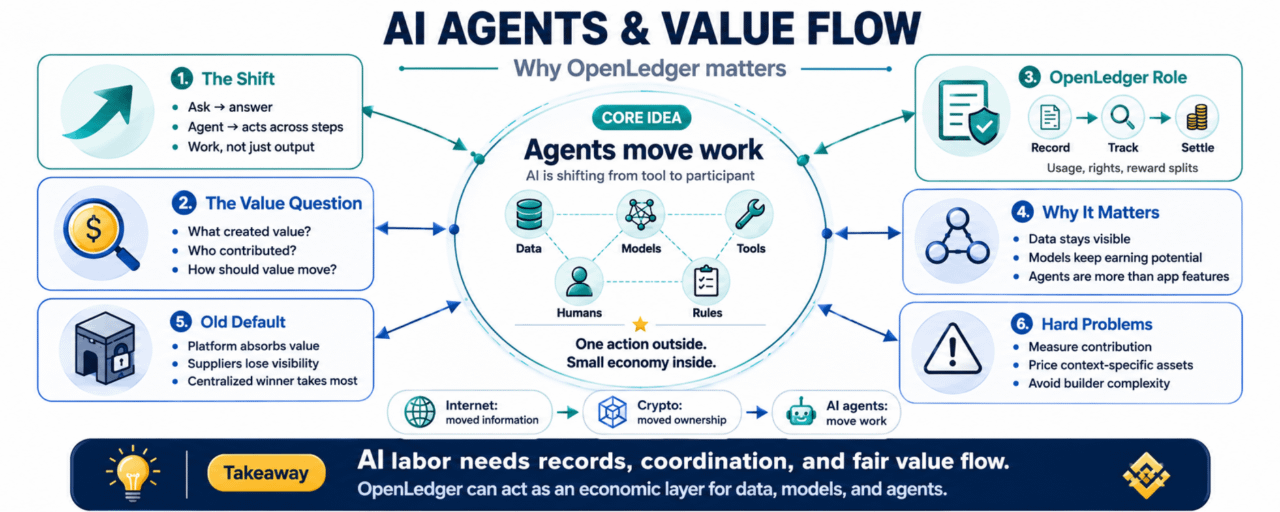
Ale agenci sprawiają, że obraz staje się mniej prosty.
Agent to nie tylko ktoś, kto czeka na jeden prompt. Może działać w różnych krokach. Może wywoływać narzędzia, sprawdzać informacje, podejmować decyzje, przekazywać pracę do innego systemu, a czasem wracać z wynikiem, który bardziej przypomina wykonaną pracę niż odpowiedź.
To tam, gdzie stare myślenie zaczyna wydawać się cienkie.
Bo kiedy agenci zaczynają działać, następne pytanie nie dotyczy tylko tego, czy są użyteczni.
Chodzi o to, jak ta praca jest wyceniana.
I kto posiada elementy, które umożliwiły wykonanie tej pracy.
W tym miejscu@OpenLedger staje się interesujące z innej perspektywy.
Nie tylko jako miejsce na dane lub modele. Bardziej jako możliwa warstwa ekonomiczna dla samej pracy AI.
Zazwyczaj można powiedzieć, kiedy nowy rynek się formuje, ponieważ język wokół niego wydaje się niedokończony. Ludzie zapożyczają stare słowa, ponieważ nowe nie są jeszcze gotowe. Czy agent to produkt? Usługa? Pracownik? Element oprogramowania? Uczestnik sieci?
Może to trochę z każdego z nich.
Agent, który pomaga w obsłudze klienta, może zależeć od prywatnego zestawu danych. Inny agent, który prowadzi badania, może zależeć od narzędzi wyszukiwania, modeli rankingowych i wiedzy specyficznej dla danej dziedziny. Agent handlowy może zależeć od sygnałów, danych z testów wstecznych i zasad ryzyka. Agent kodujący może zależeć od modeli, repozytoriów, środowisk testowych i poprawek ludzkich.
Z zewnątrz rezultat wygląda na jedną akcję.
Wewnątrz to mała gospodarka.
To jest ta część, która ma znaczenie.
Pomysł OpenLedger na odblokowanie płynności dla danych, modeli i agentów zaczyna mieć większy sens, gdy patrzysz na AI w ten sposób. Celem nie jest tylko uczynienie tych rzeczy widocznymi. Chodzi o to, aby pozwolić im uczestniczyć w tworzeniu wartości, nie będąc w pełni wchłoniętymi ani zapomnianymi.
Agent może być użyteczny z powodu modelu, który za nim stoi.
Model może być użyteczny z powodu danych, które go wspierają.
Dane mogą być użyteczne z powodu ludzi lub systemów, które je stworzyły.
A ostateczna praca może zależeć od nich wszystkich na raz.$PLAY
Więc pytanie się zmienia.
To nie jest tylko: "Czy agent wykonał zadanie?"
Staje się to: "Co pomogło agentowi wykonać to zadanie i jak wartość powinna poruszać się przez ten łańcuch?"
To jest bardzo inny rodzaj internetu.
Wczesny internet przesuwał informacje.
Krypto próbowało przesunąć własność.
Agenci AI mogą zacząć przesuwać pracę.
A praca ma wartość.
Nie w głośny czy abstrakcyjny sposób. W bardzo prosty sposób. Jeśli agent oszczędza czas, czyni proces tańszym, znajduje coś użytecznego lub wykonuje zadanie, za które ktoś by zapłacił, to wówczas powstała jakaś wartość.
Ale jeśli praca zależy od wielu ukrytych wkładów, dzielenie się wartością staje się skomplikowane.
Tutaj księga może stać się praktyczna.
Nie dlatego, że wszystko musi być finansowane. To byłoby za dużo. Ale dlatego, że niektóre prace AI będą potrzebować zapisów. Będą potrzebować dowodu na to, co zostało użyte, kto dał dostęp, jakie zasady obowiązywały i jak nagrody powinny być dzielone, gdy praca przynosi przychody.$AIA
Bez tego, domyślna ścieżka jest prosta.
Platforma wygrywa.
Agent może działać na platformie. Model może należeć do platformy. Dane mogą być wchłonięte przez platformę. Workflow może stać się częścią platformy. A po pewnym czasie wszyscy inni stają się dostawcami z bardzo małą widocznością.
To nie jest nowe. To się wydarzyło wcześniej.
Ale AI przyspiesza to.
#OpenLedger zdaje się dążyć do innej opcji, w której elementy stojące za pracą AI mogą pozostać połączone ze swoją własną wartością. Zestaw danych nie musi znikać w systemie. Model nie musi być traktowany jako jednorazowy plik. Agent nie musi być tylko funkcją w aplikacji kogoś innego.
Każdy z nich może stać się czymś z użyciem, historią i potencjałem zarobkowym.
Oczywiście rodzi to trudne pytania.
Jak zmierzyć wkład jednego zestawu danych?
Jak wycenić model, który jest użyteczny tylko w określonych kontekstach?
Jak możesz wiedzieć, kiedy agent stworzył rzeczywistą wartość?
Jak zatrzymać system przed staniem się zbyt skomplikowanym dla normalnych budowniczych?
To nie są małe problemy.
A może odpowiedzi będą nierówne przez jakiś czas.
Ale kierunek nadal wydaje się ważny, ponieważ AI już zmierza w kierunku systemów wieloagentowych i wyspecjalizowanych workflowów. Im więcej się to dzieje, tym mniej sensu ma traktowanie każdego użytecznego wkładu jako niewidocznej infrastruktury.#BNBBreaks740USDTUp12Percent
Tutaj zachodzi cicha zmiana.
AI kiedyś dotyczyło dostępu do inteligencji.
Teraz staje się to kwestią koordynacji między wieloma formami inteligencji. Wiedza ludzka. Uczenie maszynowe. Prywatne dane. Modele domenowe. Autonomiczne agenty. Sieci narzędzi.
Kiedy te rzeczy współpracują, nie tylko produkują treści. Produkują wyniki.
A wyniki to tam, gdzie zaczyna się ekonomia.
Dlatego skupienie OpenLedger na danych, modelach i agentach wydaje się bardziej osadzone niż mogłoby się na pierwszy rzut oka wydawać. Nie chodzi tylko o monetyzację statycznych aktywów. Patrzy na elementy, które mogą napędzać pracę AI w przyszłości.
Może to jest lepszy sposób, aby to ująć.
Nie AI jako jeden mózg.
Nie blockchain jako magiczne rozwiązanie.
Raczej jak system rejestracji dla świata, w którym prace wykonują wiele niewidocznych części.
Część ludzka.
Część maszyny.
Część własności.
Część współdzielona.
Część wciąż trudna do zdefiniowania.
A gdzieś między nimi wszystkimi wartość będzie musiała się poruszać.
$OPEN
Artykuł
AI powoli zmienia się z czegoś, czego używamy, w coś, co uczestniczy.
The token mentioned in this article may be subject to high volatility. DYOR.
Zastrzeżenie: zawiera opinie osób trzecich. To nie jest porada. Binance AI może być używane bez gwarancji. Zobacz Regulamin