Sempre achei que era uma pena que o lagostim só conseguisse digitar. Estudei e descobri que ele pode falar com qualquer voz que você autorizar a usar, e o efeito realmente me surpreendeu quando surgiu. (Funciona com o mesmo princípio da navegação, um pouco mais livre, quem entende, entende, hehe)
Este artigo ensina você a configurar essa funcionalidade do zero.
Condições prévias: OpenClaw 2026.3.x, Python 3.x, ffmpeg já instalado.

O que você precisa preparar
Um computador, pode ser Mac, Windows ou Linux.
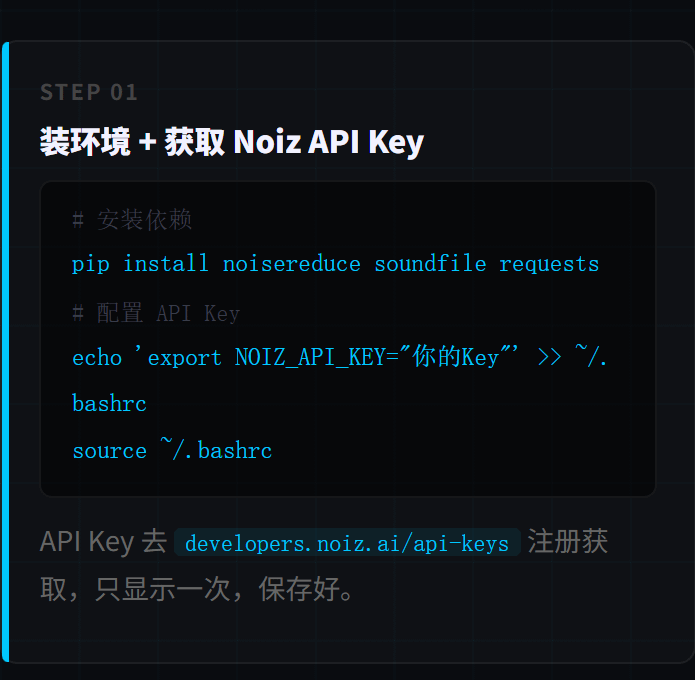
O mais importante é a Chave API Noiz, que é o núcleo de todo o tutorial, sendo uma plataforma de clonagem de voz AI com bom suporte em chinês. Etapas para obter:
Abra o navegador e acesse developers.noiz.ai/api-keys, registre-se e entre no Dashboard, clique em Criar Chave API, copie e salve, aparecerá apenas uma vez.
Primeiro passo: instalar habilidades de voz
Primeiro, instale as dependências do Python:
pip install noisereduce soundfile requests
Verifique se o ffmpeg está instalado:
ffmpeg -version
Se não tiver, usuários de Mac devem executar brew install ffmpeg, usuários de Ubuntu devem executar apt install ffmpeg.
Depois, configure a chave API do Noiz:
echo 'export NOIZ_API_KEY="suaAPIKey"' >> ~/.bashrc
source ~/.bashrc
Segundo passo: preparar amostras de voz
A qualidade da amostra de voz determina diretamente o efeito de clonagem, este passo é o mais crucial.
Grave um áudio de 20-30 segundos com sua própria voz (ou uma voz que você goste), exigências: voz humana pura, sem música de fundo, som claro, volume moderado. Após gravar, converta para o formato WAV nomeado como my_voice.wav.

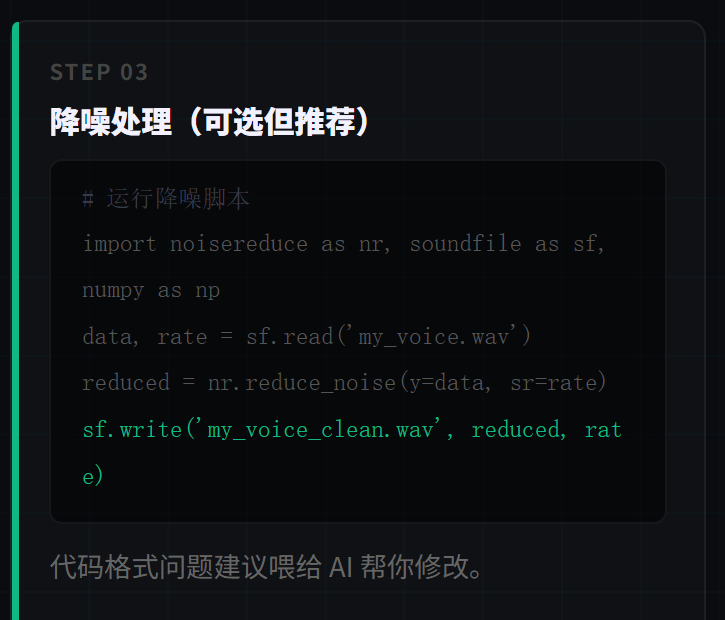
Se a gravação tiver ruído, use este código para redução de ruído:
import numpy as np
import soundfile as sf
import noisereduce as nr
data, rate = sf.read('my_voice.wav')
if len(data.shape) > 1:
data = np.mean(data, axis=1)
noise_sample = data[:int(rate * 0.3)]
reduced = nr.reduce_noise(y=data, sr=rate, y_noise=noise_sample, prop_decrease=0.8)
sf.write('my_voice_clean.wav', reduced, rate)
print("Redução de ruído concluída")
```
Sugestão de problemas de formatação de código: forneça ao AI para te ajudar a corrigir.
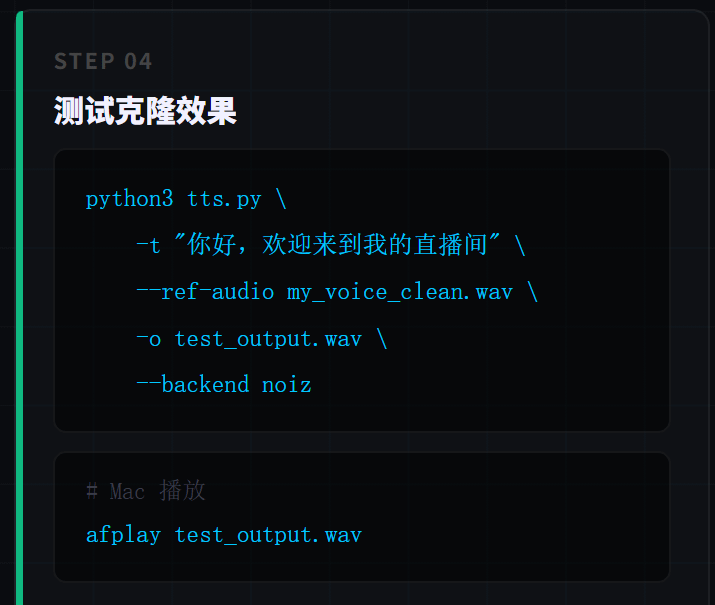
Terceiro passo: testar a clonagem de voz
python3 ~/.openclaw/workspace/skills/tts/scripts/tts.py \
-t "Olá, bem-vindo ao meu stream" \
--ref-audio my_voice_clean.wav \
-o test_output.wav \
--backend noiz
```
Reproduza para ouvir o efeito:
```
# Mac
afplay test_output.wav
# Linux
aplay test_output.wav
Quarto passo: integrar o camarão
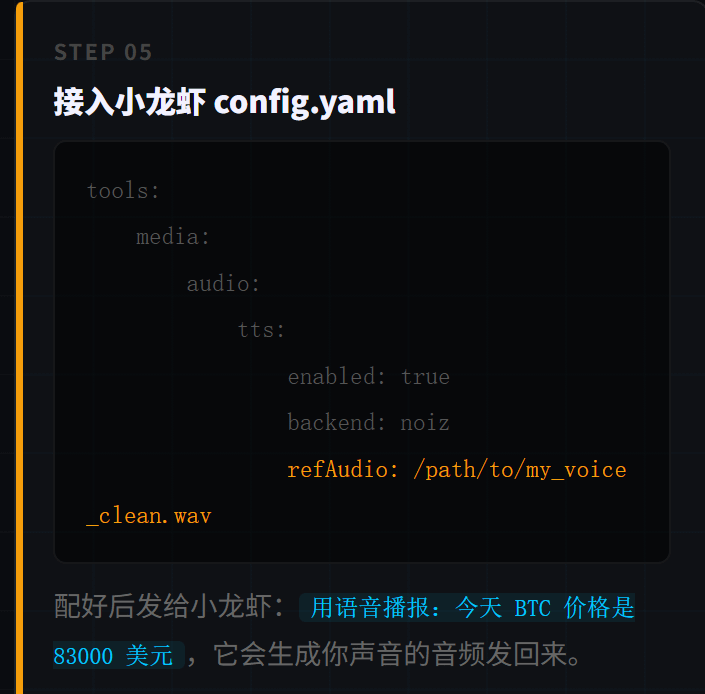
Adicione a configuração de saída de voz no config.yaml:
ferramentas:
mídia:
áudio:
habilitado: verdadeiro
tts:
habilitado: verdadeiro
backend: noiz
apiKey: YOUR_NOIZ_API_KEY
refAudio: /path/to/my_voice_clean.wav
```
Depois de configurado, envie para o camarão:
```
Use a voz para anunciar: hoje o preço do BTC é 83000 dólares, aumento de 24 horas de 2.3%
```
Ele irá gerar um áudio dizendo isso com sua voz, enviado de volta diretamente para o Telegram.
---
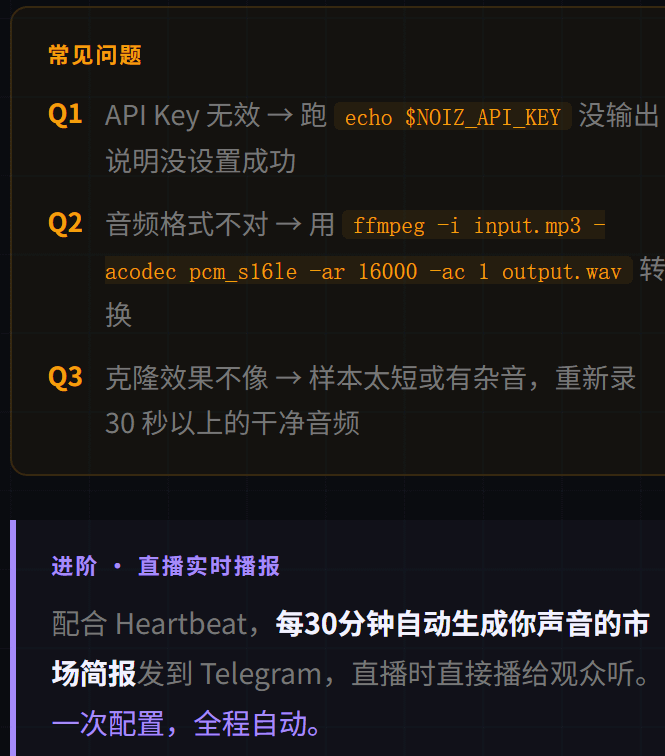
Perguntas frequentes
Falha na configuração da chave API: Chave API inválida: verifique se a variável de ambiente está configurada corretamente, execute `echo $NOIZ_API_KEY`, se não houver saída, significa que não está configurada corretamente.
Formato de áudio incorreto: Noiz requer um arquivo WAV com taxa de amostragem de 16000 Hz, profundidade de 16 bits e mono, use este comando para converter:
```
ffmpeg -i input.mp3 -acodec pcm_s16le -ar 16000 -ac 1 output.wav
O efeito de clonagem não está bom: amostra muito curta ou com ruído, grave novamente um áudio limpo de mais de 30 segundos e tente novamente.
Avançado: transmissão ao vivo com anúncios em tempo real
Com o Heartbeat, gere automaticamente um resumo de mercado com sua voz a cada 30 minutos, enviado diretamente ao Telegram, e durante a transmissão, reproduza para a audiência.
heartbeat:
schedules:
- cron: "*/30 "
prompt: |
Pesquisar os preços mais recentes do BTC ETH e dinâmicas importantes,
gerar um resumo de até 50 palavras no formato de anúncio de voz,
sintetizar áudio com minha voz e enviar para mim.