
#Neuraxon Academia de Inteligência — Volume 10
Pela Equipe Científica Qubic

Se construirmos um sistema artificial e quisermos saber se ele é inteligente, o que exatamente medimos? Achamos que sabemos quando ouvimos que o ChatGPT-5 anuncia que venceu o DeepSeek e depois que o Claude varre o Gemini.
Mas a pergunta ainda está lá, intacta. Medir a inteligência artificial não é medir velocidade ou temperatura. Não temos uma unidade de medida, por mais estranho que isso possa parecer.
Na psicologia, lidamos com esse problema há mais de um século. A inteligência artificial o enfrenta há uma década. E o faz rapidamente, com muito dinheiro em jogo e com uma tentação constante: declarar vitória.
O Fator g: Um único número para resumir a inteligência geral.
No início do século XX, Charles Spearman percebeu que, quando uma criança tinha um bom desempenho em uma disciplina, tendia a ter um bom desempenho nas outras, mesmo que fossem disciplinas sem relação aparente. As pontuações correlacionavam-se entre si, todas positivamente. Ele chamou esse padrão de variedade positiva e deduziu que deveria haver um fator latente comum por trás de todas essas habilidades díspares: o fator g, ou inteligência geral (Spearman, 1904).
A ideia é sedutora. Se todos os testes cognitivos se agrupam em um único fator, basta extrair esse fator por meio de análise fatorial para obter uma medida resumida da capacidade geral. Na prática clínica, esse primeiro fator geralmente explica entre 40 e 50% da variância no desempenho (Detterman & Daniel, 1989; Deary et al., 2009).
Mas cuidado, pois aqui reside a primeira armadilha. O fator g é populacional. Ele não mede o indivíduo, mas a variância dentro dos indivíduos (Hernández-Orallo et al., 2021). Dizer que um sujeito específico tem muito g é, estritamente falando, um erro. O fator g emerge ao comparar muitos sujeitos, não ao examinar um só. Assim como na personalidade, você é o mais extrovertido do seu grupo etário. E você continua sendo assim aos 50 anos em relação ao seu grupo, mesmo que em intensidade seja menos extrovertido do que aos 20.
O que o QI realmente mede? Entendendo os resultados dos testes de inteligência.
Mas, afinal, o que mede o QI?
Ela mede uma posição relativa. A escala é calibrada em uma amostra com média de 100 e desvio padrão de 15. Um QI de 130 não representa uma quantidade absoluta de inteligência armazenada na mente de alguém; representa a afirmação de que essa pessoa está dois desvios padrão acima da média de seu grupo normativo. O número está associado ao indivíduo, sim, mas seu significado é populacional. É uma posição em um ranking, não um conteúdo.
Sua altura é absoluta: você tem 180 centímetros de altura, mesmo que seja o último ser humano na Terra. Seu QI, não: estar acima da média exige uma média, e uma média exige outras pessoas. Ninguém pode ser mais inteligente que a média em uma ilha deserta.
Agora se entende por que transferir isso para a IA é tão delicado. Quando alguém calcula um fator g para um conjunto de grandes modelos de linguagem (LLMs), esse fator é um artefato do conjunto escolhido. Estamos medindo uma posição em uma tabela e a apresentamos como se fosse uma propriedade interna do sistema.
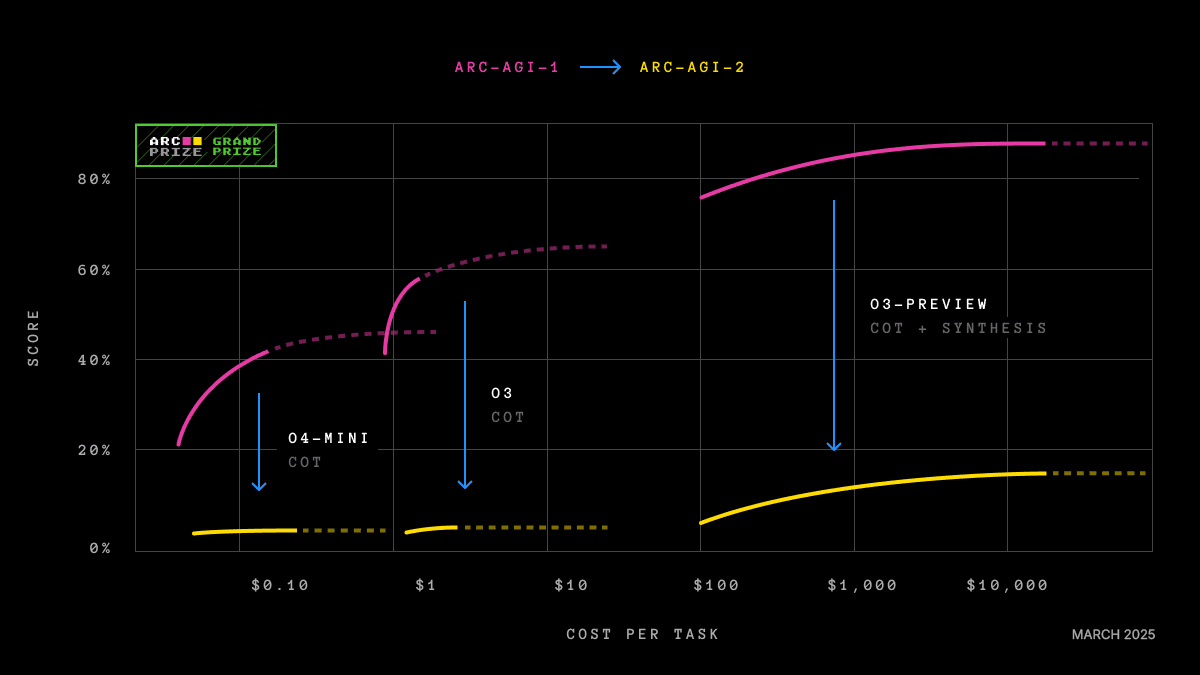
Aplicando o fator g à inteligência artificial: uma tentação perigosa
A tentação de transferir tudo isso para a IA era irresistível. Gignac e Szodorai propuseram que, se o desempenho dos modelos em diversas tarefas se correlaciona positivamente, também deveria ser possível identificar um fator geral de capacidade em sistemas artificiais. E, de fato, vários trabalhos recentes aplicam análise fatorial a baterias de testes em LLMs e encontram um fator g unidimensional que permanece estável entre modelos, baterias e métodos de extração (Ilić, 2023). Parece uma confirmação. É prudente manter a cautela.
O surgimento de um primeiro fator dominante não prova a existência de uma capacidade geral análoga à humana. Prova apenas que os resultados desses modelos covariam. E covariam por uma razão muito superficial: compartilham arquitetura, conjunto de dados de treinamento e receitas de otimização. Um modelo grande e bem treinado executa todas as tarefas com mais eficiência do que um modelo pequeno e mal treinado. Isso basta para criar uma bela variedade positiva que nada nos diz sobre generalidade cognitiva. Diz apenas sobre a escala da computação. ATENÇÃO: O fator que extraímos pode ser simplesmente um fator de tamanho disfarçado de inteligência.
Além disso, o cérebro não concentra a inteligência em um único módulo. Uma multiplicidade de subsistemas especializados processa informações em paralelo e, quando uma informação se destaca, torna-se globalmente disponível para o restante do sistema, que pode então recombiná-la para novos fins (Baars, 1988; Dehaene & Changeux, 2011). O que chamamos de generalidade é disponibilidade global: colocar um conhecimento adquirido em um contexto a serviço da resolução de um problema em outro. Não se trata de um número escalar armazenado; é um padrão de acesso e integração. Este é o tipo de arquitetura funcional que a Neuraxon tenta emular — subsistemas modulares com dinâmica de tempo contínuo e plasticidade em múltiplas escalas temporais, em vez de um transformador monolítico.
François Chollet e a abordagem moderna: Medindo o que você ainda não sabe como fazer
Em contraposição ao legado psicométrico, François Chollet propôs, em 2019, uma virada conceitual. Seu argumento, em Sobre a Medida da Inteligência, é que estávamos medindo a coisa errada.
Os parâmetros tradicionais de IA premiam habilidades, competências específicas em tarefas concretas. Mas uma habilidade pode ser adquirida com dados e computação: basta treinar o suficiente em uma tarefa para dominá-la. A inteligência, afirma Chollet, não é habilidade, mas eficiência na aquisição de habilidades: o quanto se aprende com o pouco que se tem, ao se deparar com uma tarefa genuinamente nova (Chollet, 2019).
Inteligência é o que você faz quando não sabe o que fazer.
Essa distinção muda tudo. Um sistema que resolve um milhão de problemas porque já viu dez milhões de problemas semelhantes não é inteligente. Um sistema inteligente é aquele que, ao se deparar com um problema para o qual não estava preparado, descobre a estrutura e se adapta com poucos exemplos. A métrica deixa de ser o resultado final e passa a ser a inclinação do aprendizado.
ARC-AGI: O teste de referência que avalia o raciocínio genuíno da IA
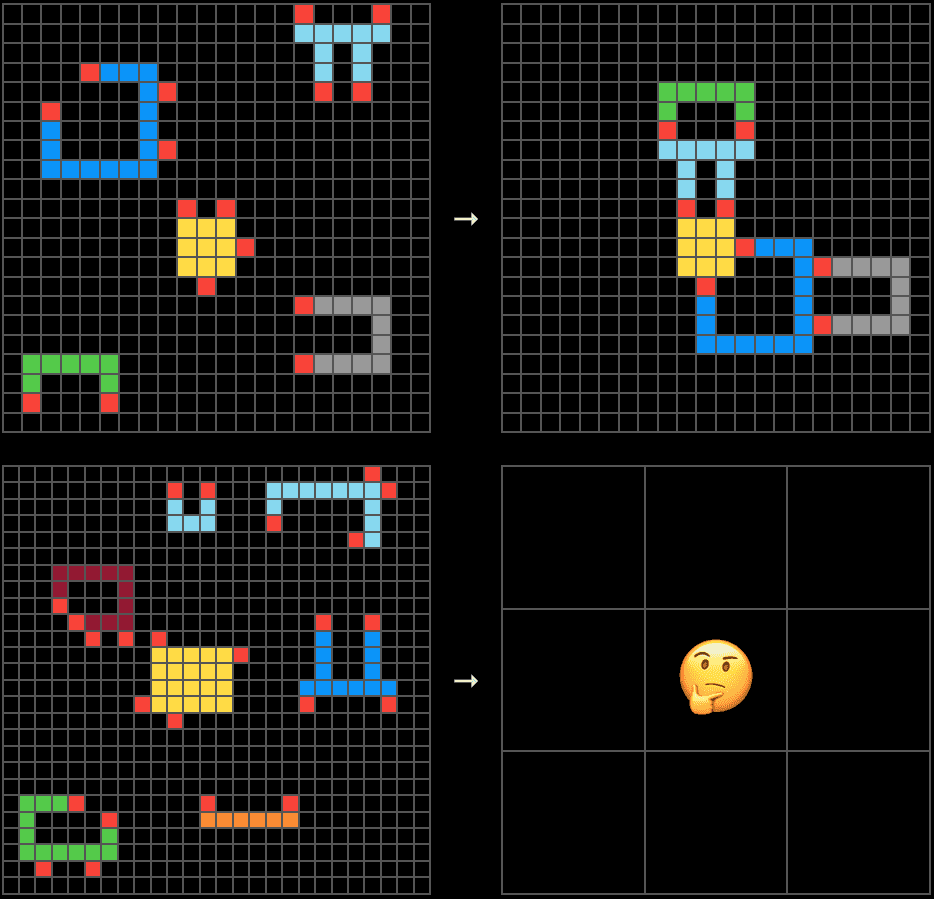
O ARC-AGI nasceu dessa ideia, e sua versão mais recente, o ARC-AGI-3, a leva adiante. Não se trata de um teste de perguntas e respostas. É um conjunto de ambientes interativos, como minijogos, nos quais o agente explora um mundo desconhecido, deduz qual é o objetivo sem que lhe seja dito em linguagem natural, constrói um modelo do ambiente e adapta sua estratégia passo a passo (Prêmio ARC, 2025).
Os princípios de design são explícitos: ambientes 100% solucionáveis por humanos, sem conhecimento prévio ou instruções ocultas, e com novidade suficiente para evitar a memorização. O que é avaliado não é o acerto, mas a eficiência na aquisição da habilidade ao longo do tempo.
É o oposto do fator g: em vez de procurar o que um sistema já domina e resumi-lo, procura o que ele ainda não sabe fazer e mede quanto custa aprendê-lo.
Contaminação de dados: por que as notas de referência do LLM são infladas?
A razão fundamental pela qual a abordagem de Chollet é importante, e por que o fator g aplicado aos mestrados em Direito é tão impreciso, tem um nome técnico: contaminação de dados. Se a prova, ou algo quase idêntico, estivesse nas anotações que o aluno estudou, sua nota não mediria o que ele consegue raciocinar. Ela mediria o que ele memorizou.
Os modelos de linguagem são treinados com base em livros, fóruns, repositórios de código, artigos, praticamente todo o texto disponível. Os benchmarks com os quais os avaliamos são publicados na internet. A conclusão é que fragmentos dos testes acabam dentro dos dados de treinamento, o que viola a separação entre treinamento e avaliação e infla as pontuações (Xu et al., 2024; Deng et al., 2024). Auditorias empíricas detectaram níveis de contaminação que variam de 1% a 45% em benchmarks amplamente utilizados, e o problema aumenta com o tempo (Li et al., 2024).
Não se trata de um problema menor relacionado a algumas questões vazadas. Em benchmarks como o MMLU ou o GSM8K, parte do que interpretamos como raciocínio pode ser pura memorização (Chen et al., 2025). Quando técnicas de descontaminação são aplicadas, reescrevendo os itens vazados sem alterar sua dificuldade, a precisão cai: em um estudo, 22,9% no GSM8K e 19,0% no MMLU (Zhu et al., 2024).
Itens parafraseados, ou mesmo traduzidos para outro idioma, burlam os detectores de sobreposição superficial e continuam a inflar os resultados (Yang et al., 2023; Yao et al., 2024). As soluções usuais (parafrasear, traduzir, ajustar o contexto) são consideradas eficazes sem terem sido rigorosamente validadas. E, para a maioria dos modelos abertos, não podemos sequer verificar nada, porque seus dados de treinamento não são publicados. Estamos corrigindo provas sem saber o que o aluno estudou.
Aqui se compreende por que a ARC-AGI escolheu o caminho que escolheu. Um ambiente interativo e inovador, sem instruções em linguagem natural e projetado para impedir a memorização por força bruta, é, por sua própria natureza, resistente à contaminação.
Então, o que devemos medir para avaliar a inteligência artificial?
O fator g é uma propriedade populacional que, aplicada a modelos que compartilham arquitetura e corpus, corre o risco de medir a escala da computação e não a generalidade. A lição para quem constrói sistemas artificiais não é escolher entre o fator g e a Inteligência Artificial Geral Retórica (ARC-AGI) como se fossem equipes rivais. É entender qual pergunta cada um responde. Uma análise fatorial pode ser útil para descrever a estrutura interna do desempenho de um sistema, desde que o primeiro fator não seja confundido com a essência da inteligência. E um protocolo do tipo ARC é indispensável para o que realmente importa: verificar se o sistema generaliza além do que observou ou se apenas repete informações.
Quando avaliamos um sistema apenas pela sua resposta final, estamos a medi-lo sem levar em conta a sua dimensão temporal: o planeamento, a atualização de crenças, a integração de evidências ao longo de várias etapas. É exatamente isso que o ARC-AGI-3 decidiu pontuar, e exatamente isso que um exame estático não consegue captar.

Por que arquiteturas de IA inspiradas no cérebro, como a Neuraxon, seguem um caminho diferente?
Se a inteligência não é um número armazenado, mas a integração eficiente de subsistemas especializados, como sugere a teoria da integração parietofrontal (P-FIT) e a disponibilidade global do espaço de trabalho no cérebro…
Se essa integração é, acima de tudo, um fenômeno temporal, com escalas de tempo…
Assim, um sistema construído sobre arquiteturas modulares com esferas funcionais, plasticidade em múltiplas escalas temporais e dinâmica contínua não precisa ser avaliado pedindo-lhe que recite respostas.
A questão correta não é quantos benchmarks ele supera, mas com que eficiência adquire novos comportamentos, ao longo do tempo, em ambientes para os quais não foi preparado. Essa é a direção que a Neuraxon tenta seguir. Computar o tempo – ou seja, a adaptação – não respostas decoradas que simulam ser um bom aluno, quando, na realidade, ele já sabe as perguntas.
Referências
Chollet, F. (2019). Sobre a medida da inteligência. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). A neurociência das diferenças de inteligência humana. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Abordagens experimentais e teóricas para o processamento consciente. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Correlações de testes mentais entre si e com variáveis cognitivas. Inteligência.
Gignac, GE e Szodorai, ET (2024). Definir e identificar um fator geral de capacidade em sistemas de IA.
Guttman, L. (1955). A determinação das matrizes de pontuação fatorial com implicações para cinco outros problemas básicos da teoria do fator comum. British Journal of Statistical Psychology.
Hernández-Orallo, J., et al. (2021). Inteligência geral desvendada por meio de uma métrica de generalidade para inteligência natural e artificial. Scientific Reports.
Honey, C. J., et al. (2012). Dinâmica cortical lenta e a acumulação de informação em longas escalas de tempo. Neuron, 76(2), 423–434.
Ilić, D. (2023). Revelando o fator de inteligência geral em modelos de linguagem: uma abordagem psicométrica. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). A Teoria da Integração Parieto-Frontal (P-FIT) da inteligência. Ciências Comportamentais e Cerebrais.
Spearman, C. (1904). "Inteligência geral" determinada e medida objetivamente. American Journal of Psychology, 15, 201–293.
Roberts, M., et al. (2024). Evidências temporais de contaminação a partir de datas de corte de treinamento.
Schönemann, P. H. (2008). Uma réplica a Mackintosh e algumas observações sobre o conceito de inteligência geral. arXiv:0808.2343.
Xu, C., et al. (2024). Contaminação de dados de referência de grandes modelos de linguagem: uma pesquisa.
Yang, S., et al. (2023). Repensando benchmark e contaminação para modelos de linguagem com amostras reformuladas.
Zhu, Q., et al. (2024). Descontaminação em tempo de inferência: reutilizando benchmarks vazados para avaliação de LLM. Resultados do EMNLP 2024.
Prêmio ARC (2025). ARC-AGI-3: Um benchmark de raciocínio interativo. Relatório Técnico.
Explore a série completa da Neuraxon Intelligence Academy.
Este é o Volume 10 da Academia de Inteligência Neuraxon, da Equipe Científica da Qubic. Se você está chegando agora, explore a série completa para obter uma compreensão abrangente da ciência por trás da abordagem da Neuraxon, Aigarth e Qubic para inteligência artificial descentralizada inspirada no cérebro:
NIA Volume 1: Por que a inteligência não é computada em etapas, mas no tempo — Explora por que a inteligência biológica opera em tempo contínuo, em vez de etapas computacionais discretas como os modelos de lógica de longo prazo tradicionais.
NIA Volume 2: Dinâmica Ternária como Modelo de Inteligência Viva — Explica a dinâmica ternária e por que a lógica de três estados (excitatório, neutro, inibitório) é importante para modelar sistemas vivos.
NIA Volume 3: Neuromodulação e IA Inspirada no Cérebro — Aborda a neuromodulação e como a sinalização química do cérebro (dopamina, serotonina, acetilcolina, norepinefrina) inspira a arquitetura da Neuraxon.
NIA Volume 4: Redes Neurais em IA e Neurociência — Uma comparação aprofundada de redes neurais biológicas, redes neurais artificiais e a abordagem de terceiro caminho da Neuraxon.
NIA Volume 5: Astrócitos e IA inspirada no cérebro — Como o controle astrocítico transforma a plasticidade da rede neural por meio da estrutura AGMP no Neuraxon.
NIA Volume 6: Máquinas Conscientes vs. Organismos Inteligentes: A Consciência da IA Explicada — Explora a consciência da IA através das lentes da Teoria do Espaço de Trabalho Global, da Teoria da Informação Integrada e da codificação preditiva.
NIA Volume 7: O Jogo da Vida de Conway, Vida Artificial e Ecossistemas Digitais — A ciência por trás da complexidade emergente e da criticidade auto-organizada de Qubic, Aigarth e Neuraxon.
NIA Volume 8: Criticidade Cerebral e a Taxa de Ramificação em Redes Neurais e Artificiais — Por que uma taxa de ramificação próxima de 1 e a criticidade auto-organizada são princípios de design bioinspirados no Neuraxon.
NIA Volume 9: As Origens do Fator g: Da Educação e Neurociência à Inteligência Artificial — Explora as origens do fator g na educação, neurociência e IA.
Qubic é uma rede descentralizada e de código aberto para tecnologia experimental. Para saber mais, visite qubic.org. Participe da discussão no X, Discord e Telegram.