Acabei de ver uma discussão sobre segurança da IA que realmente me fez parar e rever várias vezes. Não é aquele velho problema onde o modelo simplesmente entra em colapso, mas sim algo mais insidioso, onde tudo parece estar bem, a demonstração flui suavemente, a operação online é estável, e então, em um certo dia, ele se desvia silenciosamente um pouquinho, e você não consegue perceber desde quando foi contaminado. Este é o verdadeiro lado aterrorizante da contaminação de dados.
Recentemente, o Inference Labs tem enfatizado continuamente a deriva. Antes, eu costumava pular esse termo, até que vi o conteúdo do TruthTensor e finalmente acordei. O mesmo aviso, os mesmos dados, à primeira vista tudo parece normal, mas uma vez que você estende o tempo, o comportamento do modelo começa a mudar gradualmente. Não é que os parâmetros estejam ruins, mas sim que o próprio mundo está mudando, e o modelo muda junto. Você está avaliando o modelo de ontem, mas após a implementação você enfrenta o mundo de hoje, e o risco está oculto no amanhã.
Então eu quero falar sobre contaminação de dados, mas não quero entrar pelo lado das técnicas de ataque; quero discutir uma questão mais realista: já que o mundo real vai inevitavelmente sofrer deriva, por que a segurança ainda é tratada como algo único? Passar uma rodada de time vermelho, produzir um relatório, armazená-lo no arquivo e então declarar que está seguro? Honestamente, estou cada vez menos convencido por esse processo.
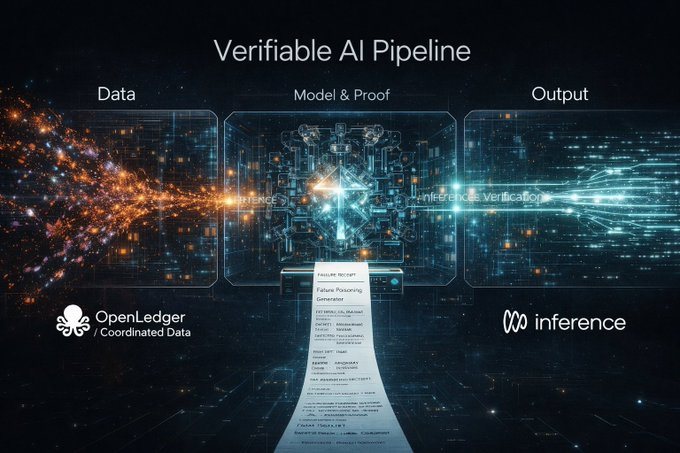
Essa questão coincidentemente se alinha com a rota de hoje do @inference_labs. Eles estão colaborando com o novo parceiro @OpenledgerHQ para colocar a coordenação e aquisição confiável dos dados de treinamento no topo, enquanto o Inference Labs se encarrega da camada de validação do modelo e da inferência. Desde os dados até o modelo e os resultados da inferência, pela primeira vez, tudo foi claramente dividido em um pipeline auditável. Este passo, na verdade, é muito mais importante do que simplesmente ajustar os parâmetros do modelo para torná-lo mais forte.
É exatamente porque há esta camada adicional de dados que o significado do time vermelho se torna realmente completo. Muitas pessoas falam sobre a contaminação de dados presumindo que atacam apenas o modelo, mas na realidade, o que é contaminado primeiro no mundo real geralmente são os dados. Se os dados upstream forem rastreáveis e a inferência no meio for verificável, o alvo do ataque do time vermelho se torna toda a pipeline, e a fronteira de segurança é considerada fechada.
Adicionando o DSperse, essa coisa realmente pode se concretizar. Não é um confronto direto com todo o grande modelo, mas sim desmembrar a validação em partes, como desmontar peças de um carro e verificar uma a uma, em vez de colidir o carro inteiro contra a parede. Para o time vermelho, isso é muito crucial, pois a contaminação de dados muitas vezes não é simplesmente furar o modelo, mas sim ajustar silenciosamente o volante em uma parte específica.
Eu sempre achei particularmente estranho que os relatórios do time vermelho basicamente estão contando histórias. Um PDF, algumas descrições, algumas capturas de tela, no fundo, ainda é sobre fazer as pessoas confiarem em você. Mas o Inference Labs já transformou o processo de inferência em evidências verificáveis, os dados upstream também estão indo em direção à verificação, então por que as evidências de ataque ainda permanecem na fase oral? Isso é realmente muito desconectado.
Então eu dei a essa ideia um nome bem simples, mas útil: Recibo de Falha. A segurança sem recibo se assemelha mais a rumores, não a descobertas científicas.
Na minha visão, um recibo de falha qualificado é na verdade simples: basta permitir que outros possam reproduzir a falha que você mencionou. Deve indicar a impressão digital do compromisso do modelo, o hash do compromisso da entrada, o estado do mundo da deriva no momento da ativação, a categoria específica da falha e, por fim, fornecer um comando que pode ser executado. Falhas que não podem ser reproduzidas, eu realmente acho difícil considerá-las vulnerabilidades.
Se o Inference Labs realmente quiser transformar o jogo do time vermelho em um mecanismo em cadeia, o que eu mais gostaria de ver é um processo que é na verdade muito direto: primeiro, enviar o hash do recibo de falha, junto com um depósito de dinheiro; após o encerramento do período de janela, tornar públicos os exemplos e os scripts de reprodução, e os validadores da rede usam o DSperse para rebater em partes, o pagamento só ocorre se houver sucesso, e a falha resulta na queima do depósito. Parece duro, mas é o mais eficaz contra bots.
Claro que haverá problemas, vulnerabilidades ruins vão proliferar, cópias de amostras para roubar créditos vão acontecer e a divulgação muito precoce fará com que os atacantes aprendam mais rápido. Portanto, o commit-reveal e a divulgação atrasada são indispensáveis, primeiro provando que existe um caminho reproduzível, e depois liberando os detalhes mais tarde, dando um tempo para correções.
Eu realmente espero que a função de recompensa inclua um indicador sobre se essa falha tem relação com a deriva. Na verdade, existem muitas vulnerabilidades que podem ser reproduzidas em um ambiente estático, mas aquelas que podem ser acionadas de forma estável e a longo prazo em um mundo em deriva são realmente raras. A avaliação dinâmica do TruthTensor conectada a toda a pipeline confiável já está sugerindo que a segurança da IA no futuro não será uma defesa pontual, mas sim uma linha de produção contínua de adversidades.
@inference_labs se vocês realmente querem levar o jogo do time vermelho para a direção de mecanismos, nesta atual OpenLedger que gerencia dados, e vocês que gerenciam o modelo e a pipeline de inferência verificável, qual parte vocês padronizariam primeiro?
A. Formato do recibo de falha
B. Curva de recompensa
C. Mecanismo de divulgação e divulgação atrasada
D. Ambiente de reprodução de deriva (drift harness)
Eu pessoalmente sou bem D. Não existe um mundo que possa ser reproduzido de forma unificada por todos, mesmo o recibo mais bonito só pode reproduzir emoções.
Se você acha que a ideia do recibo de falha é útil, basta responder com uma letra; quero ver o que todos acham que falta nesta pipeline verificável de IA.