@Mira - Trust Layer of AI #Mira
De ani de zile, discuția din jurul inteligenței artificiale s-a concentrat aproape exclusiv pe capacitate: modele mai mari, inferență mai rapidă, mai multe date și rezultate din ce în ce mai impresionante care par, cel puțin la suprafață, să se apropie de raționamentul uman. Totuși, sub acest progres rapid se află o întrebare mai liniștită și mai dificilă pe care industria a început abia recent să o abordeze cu seriozitate: cum determinăm când un sistem AI este de fapt de încredere? Nu doar convingător, nu doar încrezător, ci fiabil într-un mod în care instituțiile, piețele și infrastructura critică se pot baza fără ezitare.
Provocarea există deoarece sistemele moderne de inteligență artificială nu produc cunoștințe în sensul tradițional, ci generează probabilități modelate de tiparele din datele lor de antrenament. Un model poate suna autoritar în timp ce fabrică în tăcere o citare, citind greșit o clauză de reglementare sau combinând fragmente de informații într-un ceva care pare logic, dar se bazează pe fundații instabile. Aceste eșecuri apar rar dramatic. În schimb, ele se manifestă ca distorsiuni subtile care trec neobservate până când consecințele lor ies la iveală în rapoartele financiare, rezumatele de cercetare sau deciziile automatizate care se bazează pe ieșirea modelului ca și cum ar fi un fapt verificat.
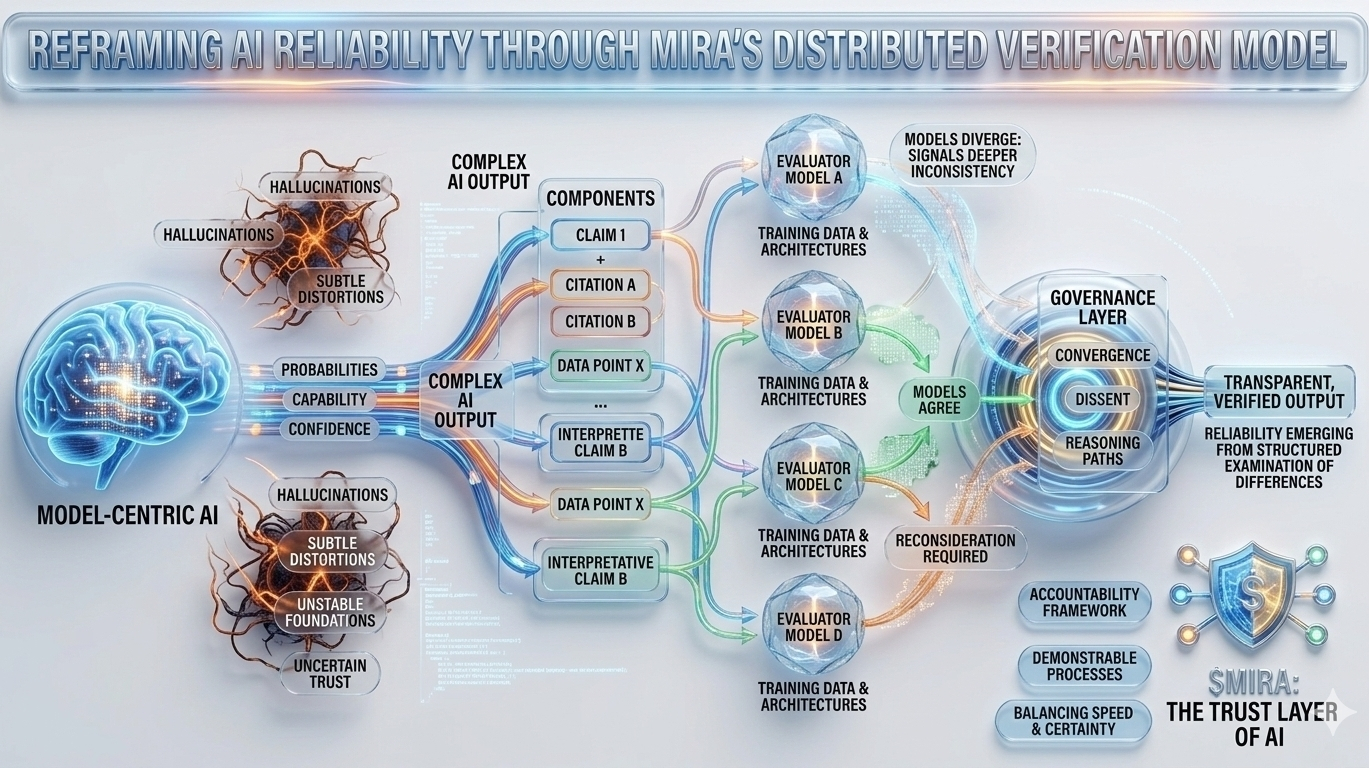
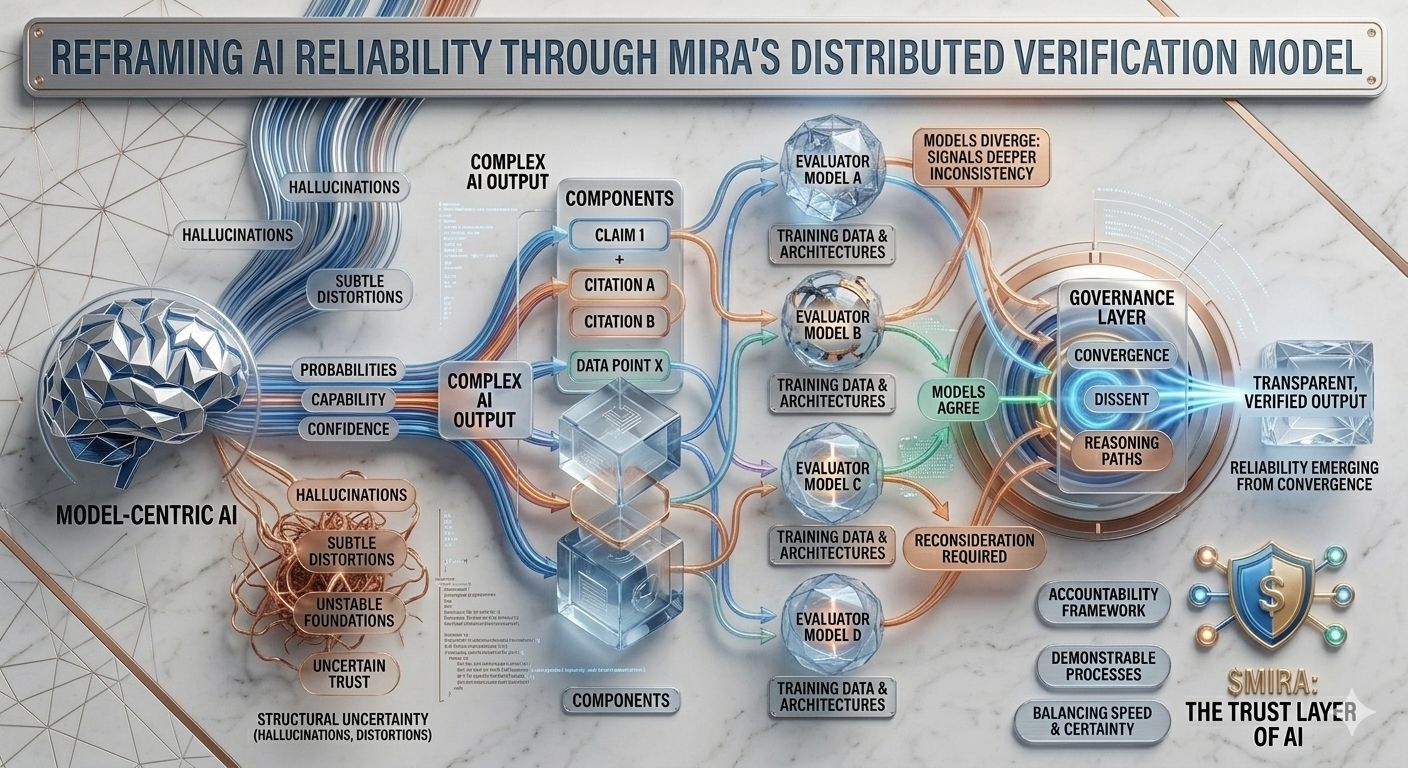
Această incertitudine structurală este exact problema pe care Mira încearcă să o abordeze, nu cerând perfecțiune de la un singur model, ci regândind întregul proces prin care sunt produse și validate răspunsurile AI. În arhitectura Mira, o ieșire AI este tratată mai puțin ca o concluzie finalizată și mai mult ca o ipoteză care intră într-un proces de verificare. În loc să aibă încredere în calea de raționare a unui singur model, sistemul distribuie evaluarea între mai multe modele independente care examinează aceeași afirmație din perspective diferite, fiecare modelată de corpuri de antrenament distincte, arhitecturi și prejudecăți interne.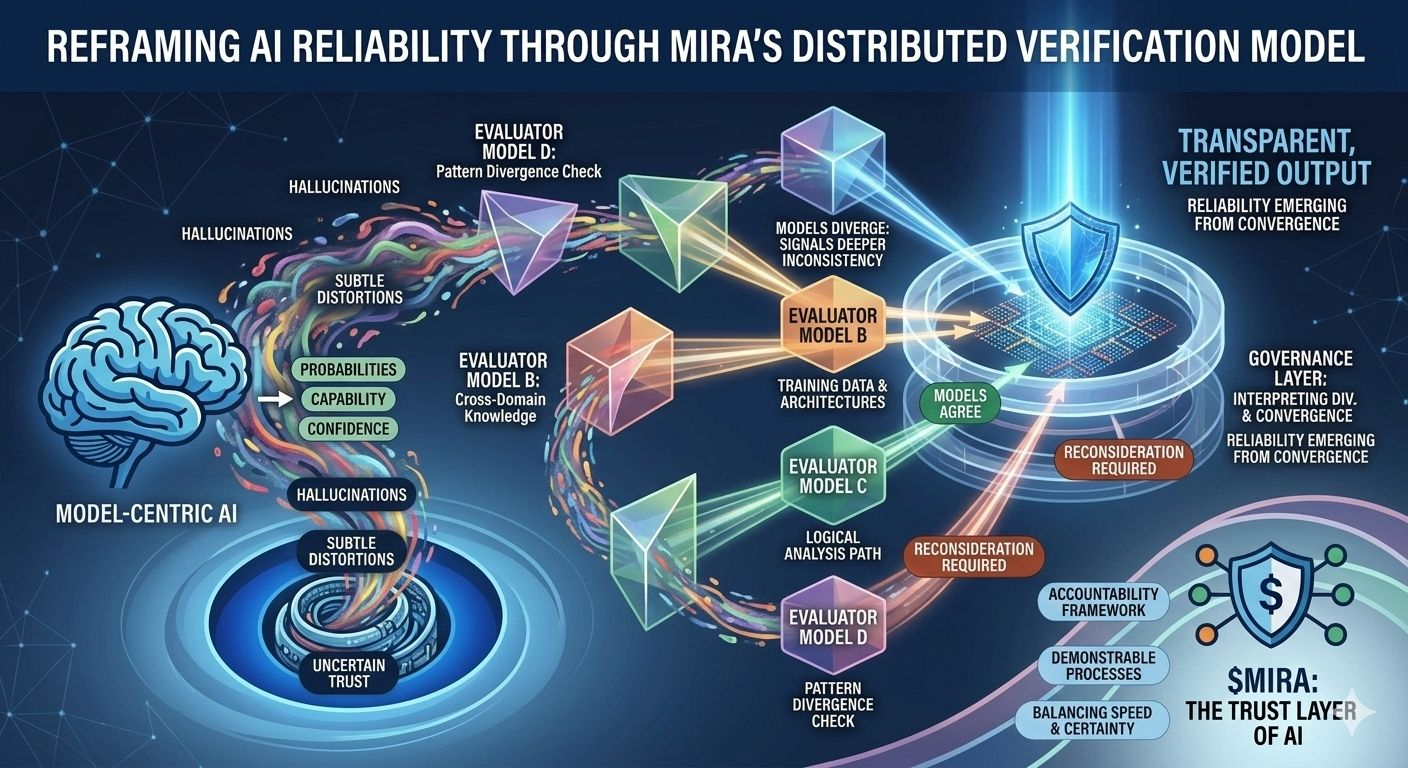
Ceea ce face această abordare deosebit de interesantă este că obiectivul nu este acordul orb între modele. Votul simplu al majorității ar oferi doar o asigurare superficială, deoarece modelele antrenate pe date suprapuse moștenesc adesea presupuneri și puncte oarbe similare. Cadrele de guvernare ale Mirei se concentrează în schimb pe interpretarea modului în care modelele sunt de acord, unde diverg și dacă dezacordul semnalează o inconsistență mai profundă în cadrul afirmației în sine. Cu alte cuvinte, fiabilitatea apare nu din răspunsuri uniforme, ci din examinarea structurată a diferențelor în raționare.
Pentru a face acest lucru posibil, ieșirile complexe AI trebuie mai întâi să fie împărțite în componente mai mici și verificabile. Un rezumat de cercetare generat devine o serie de afirmații urmărite, o explicație legală se transformă într-o secvență de afirmații interpretative, o analiză financiară se separă în aserțiuni cuantificabile care pot fi verificate independent. Fiecare dintre aceste fragmente poate fi apoi evaluat de modele separate, permițând sistemului să cartografieze nu doar dacă răspunsul general pare corect, ci și care elemente specifice rezistă la examinare și care necesită reconsiderare.
Această schimbare poate părea subtilă, dar reprezintă o schimbare profundă în locul în care se află încrederea într-un sistem AI. Pipele tradiționale concentrează autoritatea în cadrul modelului în sine: dacă modelul funcționează bine, sistemul funcționează bine; dacă eșuează, întregul proces se prăbușește. Mira distribuie acea responsabilitate între un strat de guvernare care evaluează afirmațiile înainte de a se solidifica în ieșiri. În acest mediu, credibilitatea nu provine din scorul de încredere al unui model, ci din convergența căilor de raționare evaluate independent.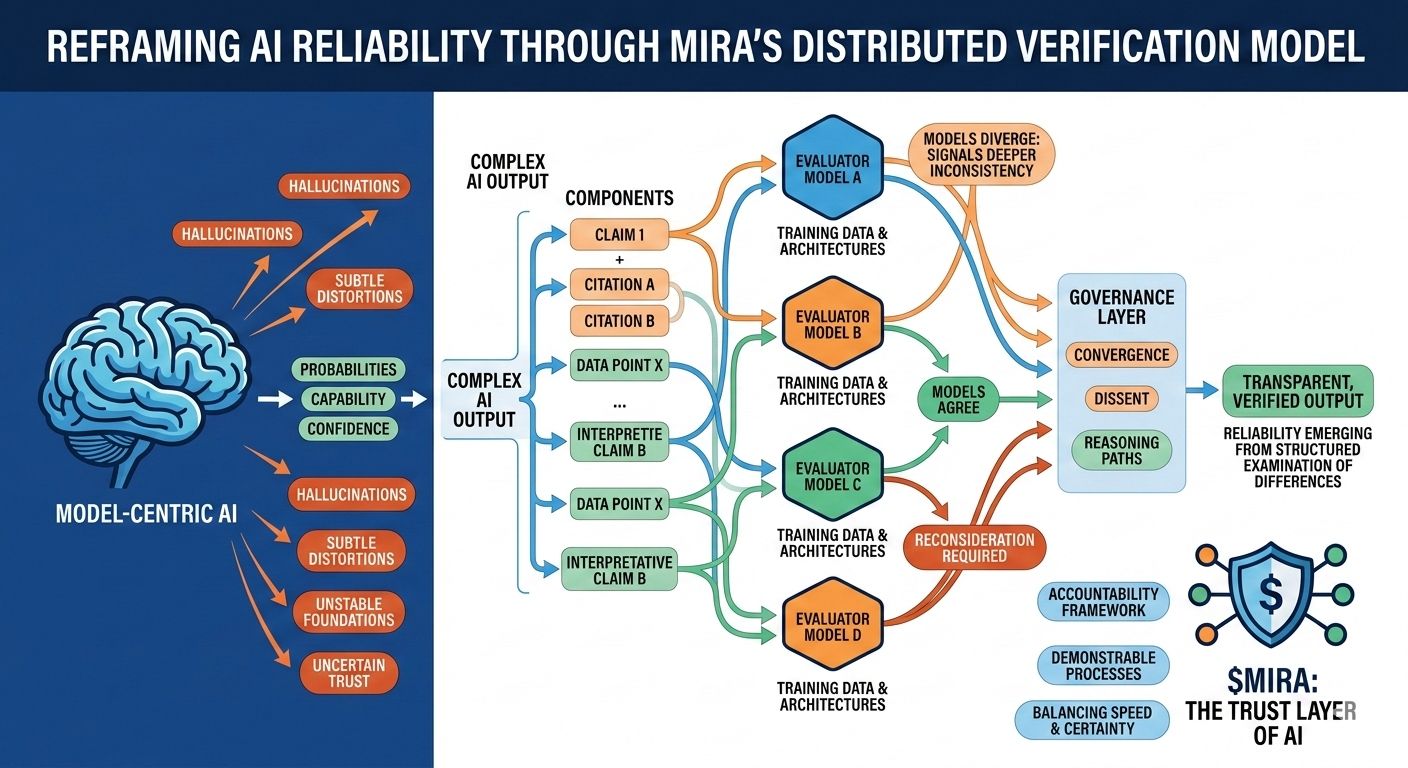
Desigur, distribuirea verificării nu elimină fiecare formă de eroare. Modelele antrenate pe seturi de date similare pot reproduce în continuare informații învechite, iar solicitările sofisticate adversariale pot exploata slăbiciuni sistemice comune între arhitecturi. Consensul multi-model reduce probabilitatea halucinațiilor aleatoare, dar nu poate preveni complet eroarea coordonată care apare din presupunerile comune încorporate în ecosistemul AI mai larg. Din acest motiv, transparența devine la fel de esențială ca verificarea însăși. Utilizatorii trebuie să înțeleagă dacă modelele de verificare reprezintă cu adevărat perspective independente sau doar variații ale aceluiași sistem de bază.
O altă dimensiune a acestui design se află în implicațiile sale economice. Verificarea nu este gratuită: fiecare apel suplimentar de model introduce costuri computaționale, latență și complexitate a infrastructurii. Pe măsură ce sistemele AI integrează tot mai mult straturi de verificare, dezvoltatorii trebuie să facă alegeri deliberate cu privire la momentul în care validarea profundă este necesară și când răspunsurile rapide sunt suficiente. Aplicațiile construite pe AI verificat evoluează, prin urmare, în gestionari de fiabilitate care echilibrează constant viteza, costul și certitudinea, determinând totodată care ieșiri necesită un control mai profund sau supraveghere umană.
Aceste compromisuri vor remodela probabil modul în care platformele AI concurează în anii următori. Capacitatea de sine nu va mai defini cele mai puternice sisteme. În schimb, abilitatea de a demonstra procese de verificare transparente, de a comunica clar incertitudinea și de a expune cu grație dezacordul între modele poate deveni caracteristica definitorie a infrastructurii AI de încredere. Sistemele care recunosc limitările lor în timp ce conțin sistematic erorile se vor dovedi în cele din urmă mai valoroase decât cele care pur și simplu proiectează încredere.
Văzut din această perspectivă, modelul Mirei nu se concentrează atât pe construirea de modele individuale mai inteligente, ci mai mult pe construirea unui cadru de responsabilitate în jurul inteligenței mașinilor în sine. Răspunsurile AI devin propuneri mai degrabă decât declarații—afirmații care trebuie să treacă printr-o rețea de evaluatori independenți înainte de a fi acceptate ca ieșiri credibile. Într-un astfel de sistem, greșelile rămân inevitabile, dar impactul lor este conținut prin mecanisme de verificare care identifică slăbiciunile înainte de a se propaga în decizii, sisteme financiare sau discurs public.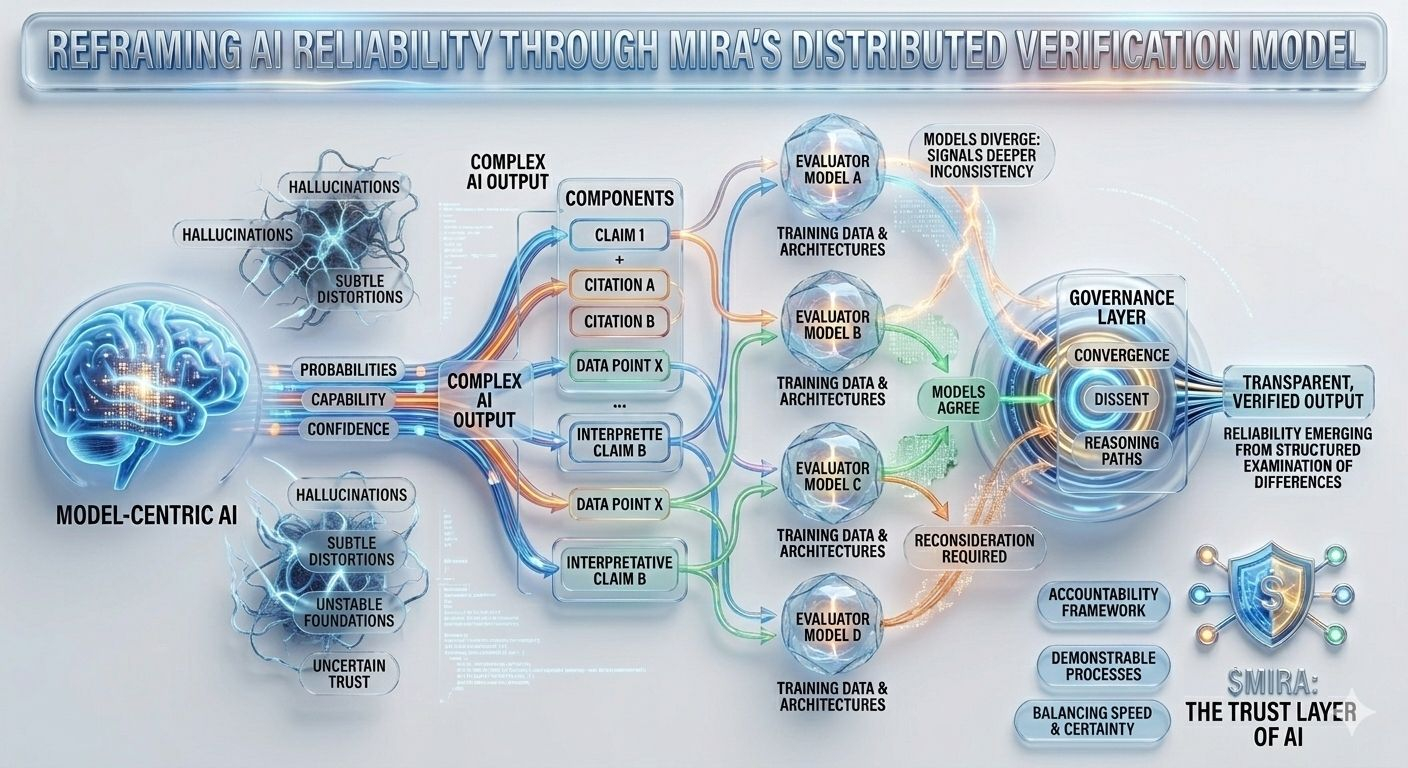
În cele din urmă, viitorul AI fiabil poate depinde mai puțin de atingerea unui acord perfect între modele și mai mult de definirea modului în care acel acord este interpretat, cum sunt analizate semnalele de dezacord și ce măsuri de siguranță sunt activate atunci când consensul începe să se fractureze. Măsura adevărată a încrederii nu va fi dacă mașinile produc întotdeauna răspunsul corect, ci dacă sistemele din jurul lor sunt concepute pentru a întreba, testa și valida acele răspunsuri înainte ca lumea să se bazeze pe ele.
$MIRA
