 @Mira - Trust Layer of AI #Mira
@Mira - Trust Layer of AI #Mira
Când oamenii vorbesc despre îmbunătățirea AI-ului, conversația începe de obicei cu modele mai mari, mai multe date de antrenament sau o inferență mai rapidă. Prima mea reacție la această formulare este scepticismul. Nu pentru că aceste lucruri nu contează, ci pentru că ratează problema mai tăcută din spatele majorității sistemelor AI de astăzi: interpretarea. AI poate produce volume enorme de ieșire, dar întrebarea reală este dacă cineva poate avea încredere în mod fiabil în ceea ce înseamnă aceste ieșiri.
Aceasta este lacuna pe care interpretarea de încredere încearcă să o închidă. Provocarea nu este doar că modelele halucinează ocazional; este că utilizatorii rareori au o modalitate clară de a verifica dacă o afirmație specifică generată de un sistem AI ar trebui să fie crezută. Când un răspuns pare rafinat și încrezător, este ușor să uiți că sistemul care îl produce poate trasa din modele incerte mai degrabă decât din fapte verificabile.
Cele mai multe desfășurări AI actuale tratează această incertitudine ca pe un compromis acceptabil. Dacă un răspuns pare rezonabil și ajunge rapid, sistemul este considerat de succes. Dar odată ce AI începe să susțină decizii financiare, operațiuni automate sau procese de guvernanță, „ceea ce pare rezonabil” nu mai este suficient. Interpretarea devine o problemă de infrastructură mai degrabă decât o îmbunătățire cosmetică.
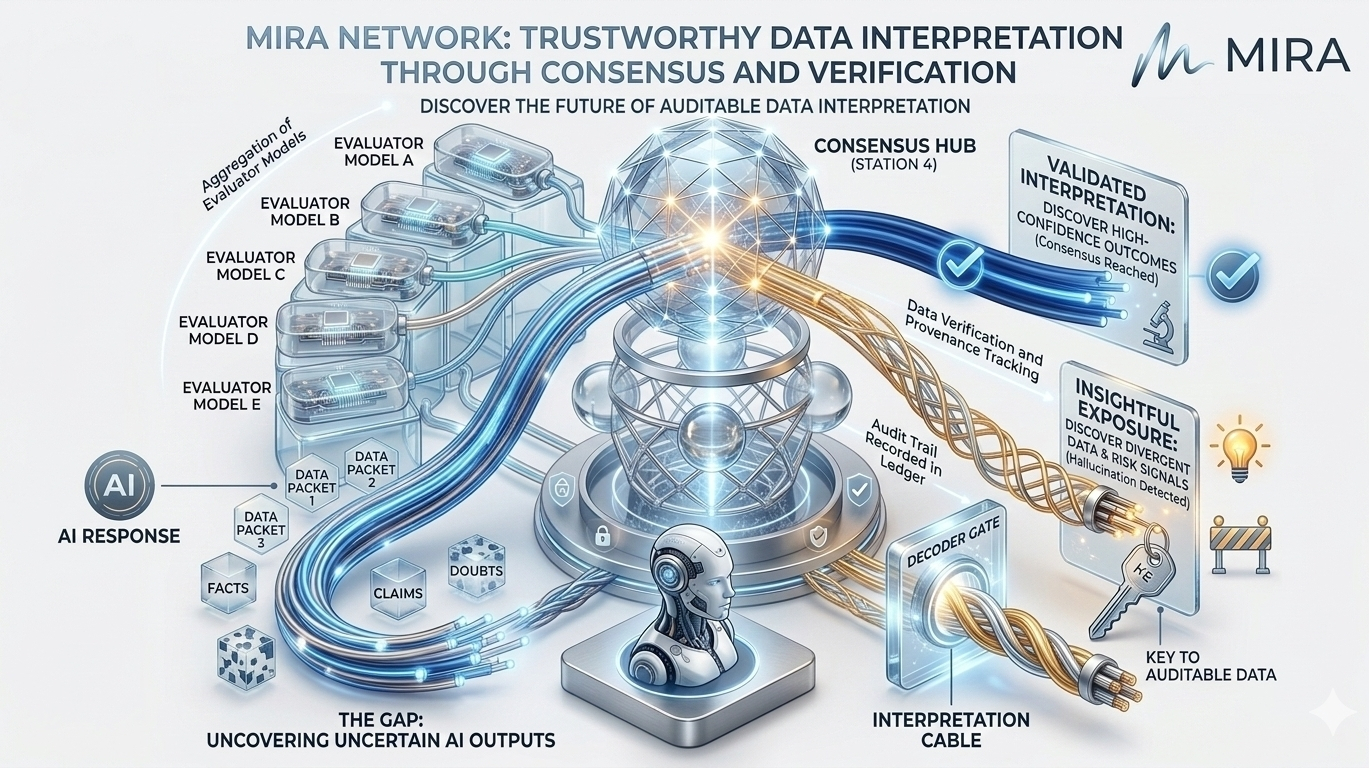
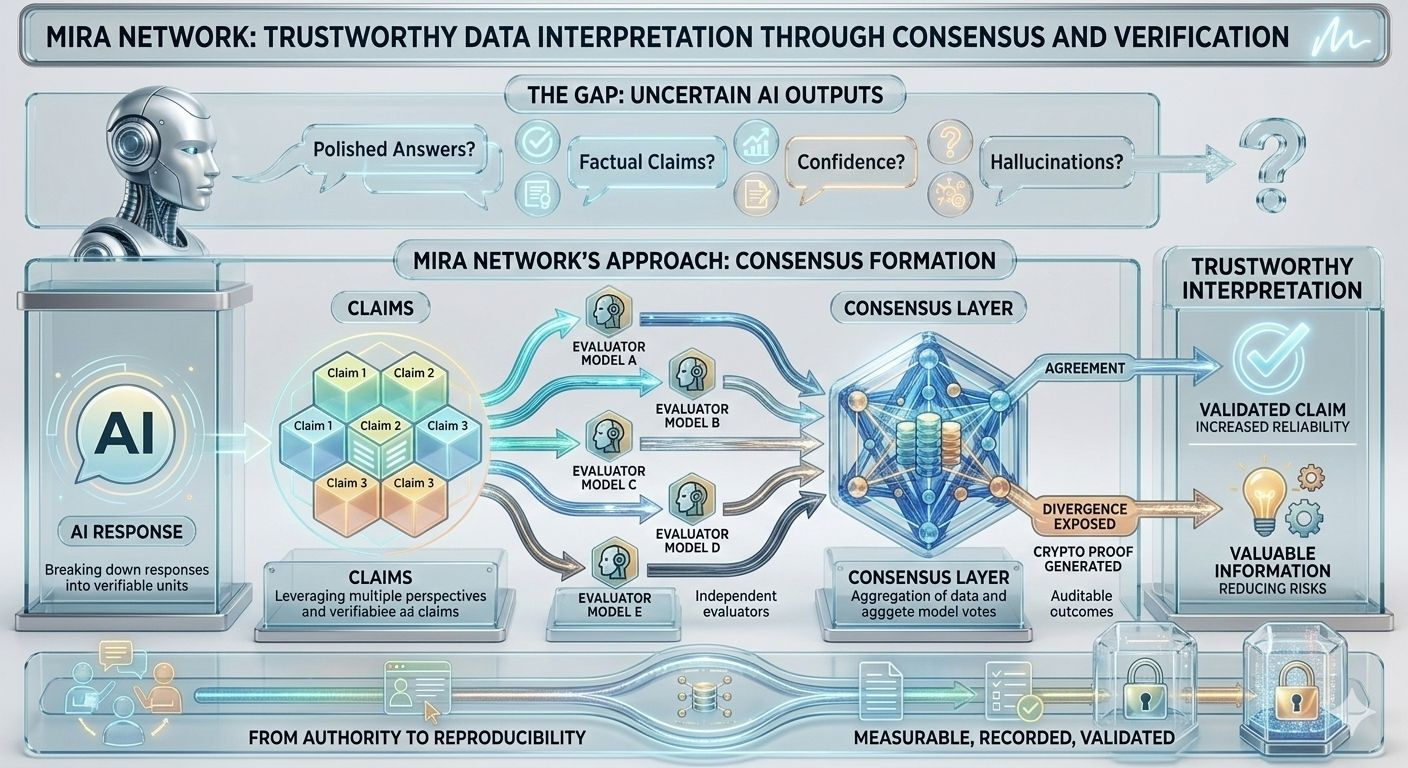
Aici este locul în care Mira Network introduce o abordare diferită. În loc să trateze un răspuns AI ca o singură bucată de output, sistemul îl descompune în afirmații mai mici care pot fi evaluate independent. Fiecare afirmație poate fi examinată în mai multe modele, permițând rețelei să compare interpretările în loc să se bazeze pe o singură sursă de raționament.
Odată ce te gândești la asta în acest mod, interpretarea datelor încetează să mai fie o sarcină de un singur model și începe să arate mai mult ca formarea unui consens. Dacă mai multe sisteme independente evaluează aceeași afirmație și ajung la concluzii similare, probabilitatea de fiabilitate crește. Dacă interpretările lor diverge, dezacordul în sine devine informație valoroasă.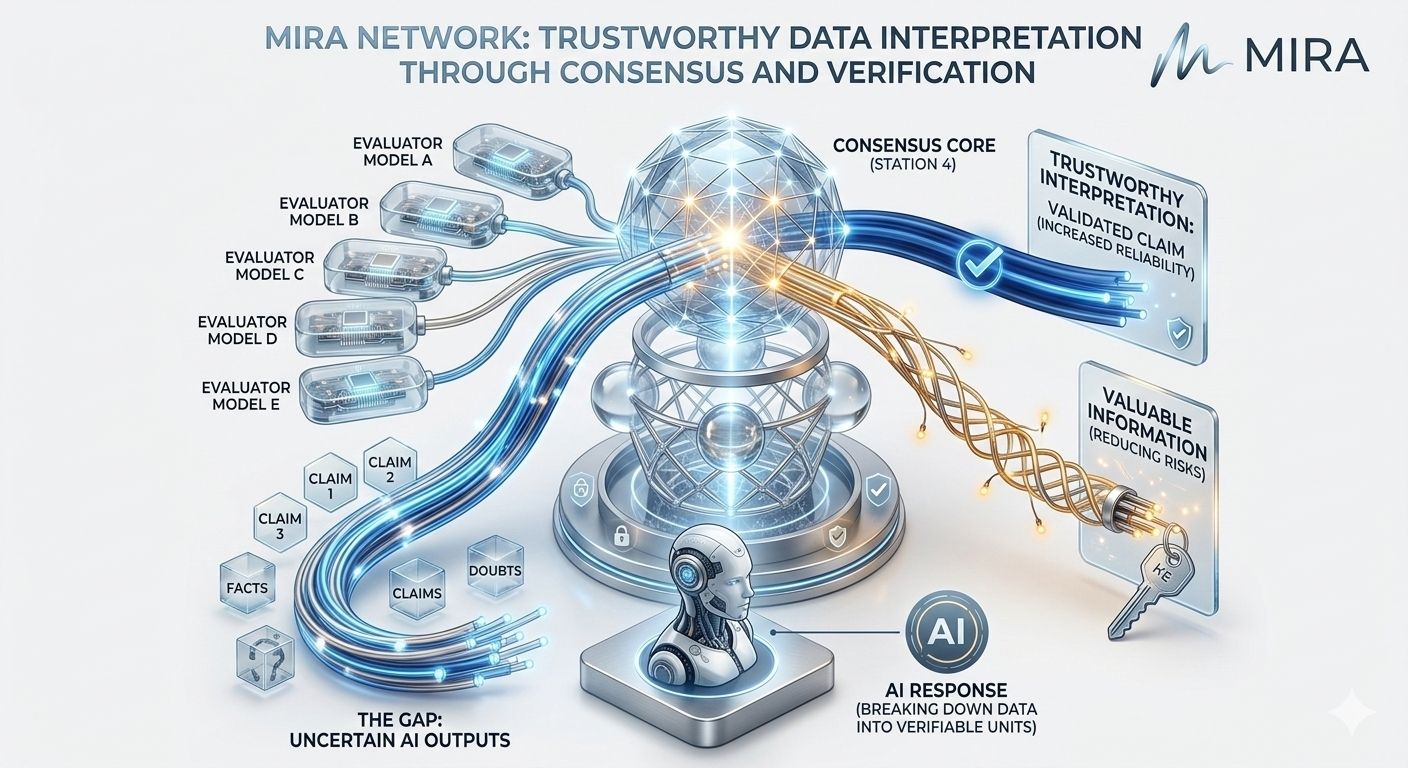
Dar partea interesantă nu este doar verificarea - este modul în care procesul de verificare devine structurat. Transformarea afirmațiilor în unități verificabile înseamnă că interpretarea poate fi măsurată, înregistrată și validată. În loc să aibă încredere în scorul de încredere al unui model, utilizatorii interacționează cu un sistem care produce dovezi criptografice că mai mulți evaluatori au examinat informațiile.
Desigur, aceasta ridică o altă întrebare: cine efectuează acea muncă de evaluare? Într-o rețea de verificare descentralizată, rolul se mută de la un singur furnizor AI centralizat la un set distribuit de participanți care rulează diferite modele. Fiecare participant contribuie cu analize, iar rețeaua agregă rezultatele într-o interpretare condusă de consens.
Această schimbare modifică stimulentele în jurul fiabilității datelor. În serviciile AI tradiționale, utilizatorii au încredere implicită în furnizorul care operează modelul. Cu un strat de verificare, încrederea devine distribuită între evaluatori independenți ale căror concluzii trebuie să se alinieze pentru a valida o afirmație. Sistemul devine mai puțin despre autoritate și mai mult despre reproducibilitate.
În mod natural, mecanismele din spatele acelui proces contează mult. Afirmațiile trebuie să fie structurate suficient de clar pentru a putea fi evaluate independent. Evaluatorii trebuie să aibă stimulente pentru a oferi judecăți precise, în loc să fie de acord pur și simplu cu majoritatea. Și rețeaua are nevoie de un mod de a înregistra rezultatele transparent, astfel încât interpretarea să rămână auditabilă în timp.
Aceste detalii sunt locul în care interpretarea se mută de la concept la infrastructură. Verificarea nu se referă doar la verificarea faptelor; este despre proiectarea unui sistem în care perspective multiple pot converg pe un răspuns de încredere fără a depinde de un singur gardian.
Există, de asemenea, o implicație mai largă care adesea este trecută cu vederea. Odată ce interpretarea AI devine verificabilă, se deschide calea pentru automatizare în domenii care anterior necesitau supraveghere umană. Sistemele autonome ar putea face referire la afirmații validate în loc de output-uri brute ale modelului, reducând riscul ca o singură halucinație să perturbe un întreg flux de lucru.
Aceasta nu înseamnă că verificarea elimină complet incertitudinea. Discrepanțele între modele vor continua să apară, iar rețeaua trebuie să decidă cum se rezolvă aceste conflicte. Dar chiar și acel proces poate fi valoros, deoarece expune ambiguitatea în loc să o ascundă în spatele unui singur răspuns încrezător.
În timp, adevărata măsură a succesului pentru sisteme precum Mira Network nu va fi pur și simplu dacă verifică corect output-urile AI în condiții normale. Adevăratul test va veni atunci când datele sunt neclare, modelele nu sunt de acord sever sau stimulentele împing participanții spre manipulare. Interpretarea de încredere contează doar dacă continuă să funcționeze atunci când mediul informațional devine complicat.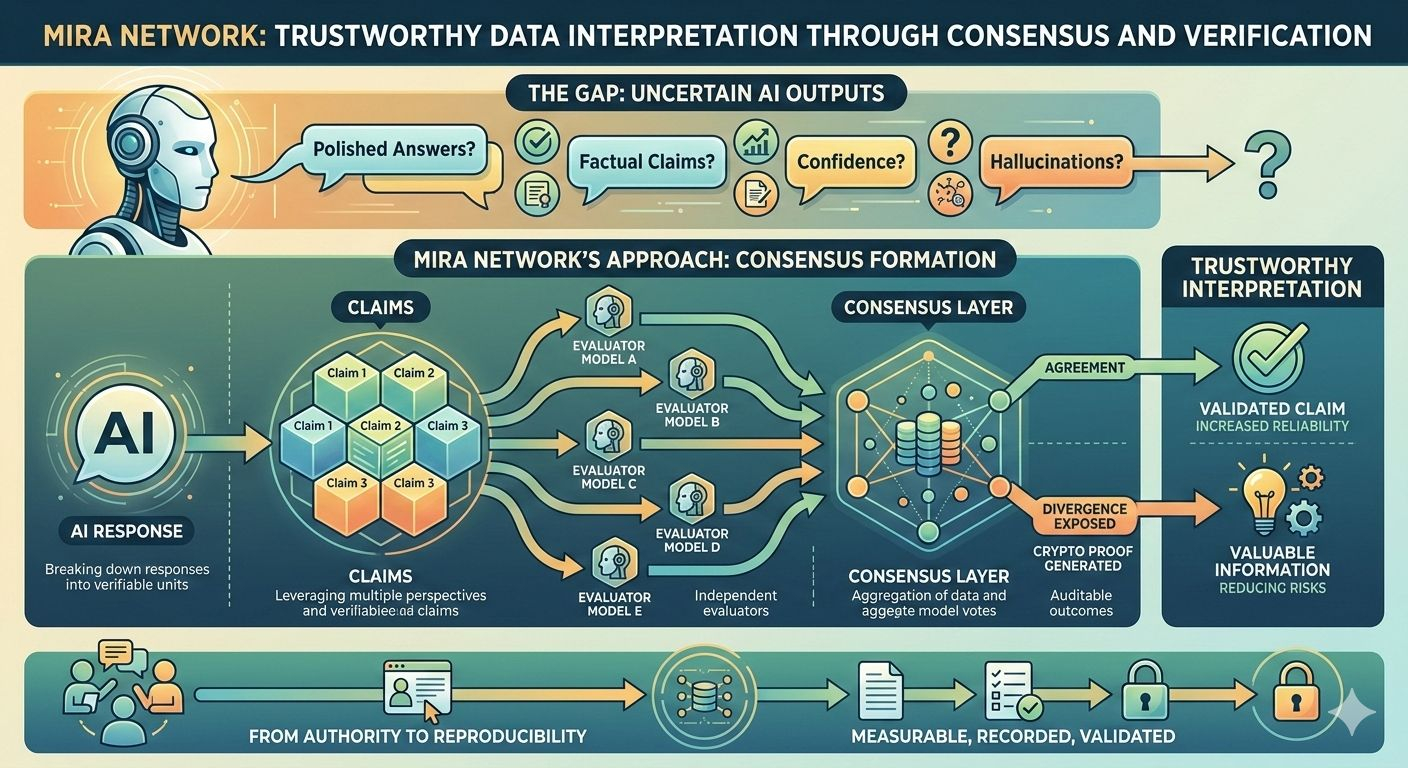
Așadar, cea mai importantă întrebare nu este dacă AI poate genera răspunsuri mai repede sau mai fluent. Întrebarea este dacă ecosistemul poate construi sisteme care interpretează acele răspunsuri în moduri pe care oamenii le pot verifica, audita și se pot baza pe ele. Pentru că într-o lume din ce în ce mai modelată de decizii automate, diferența dintre informație și interpretare de încredere poate ajunge să fie cel mai important strat dintre toate.
