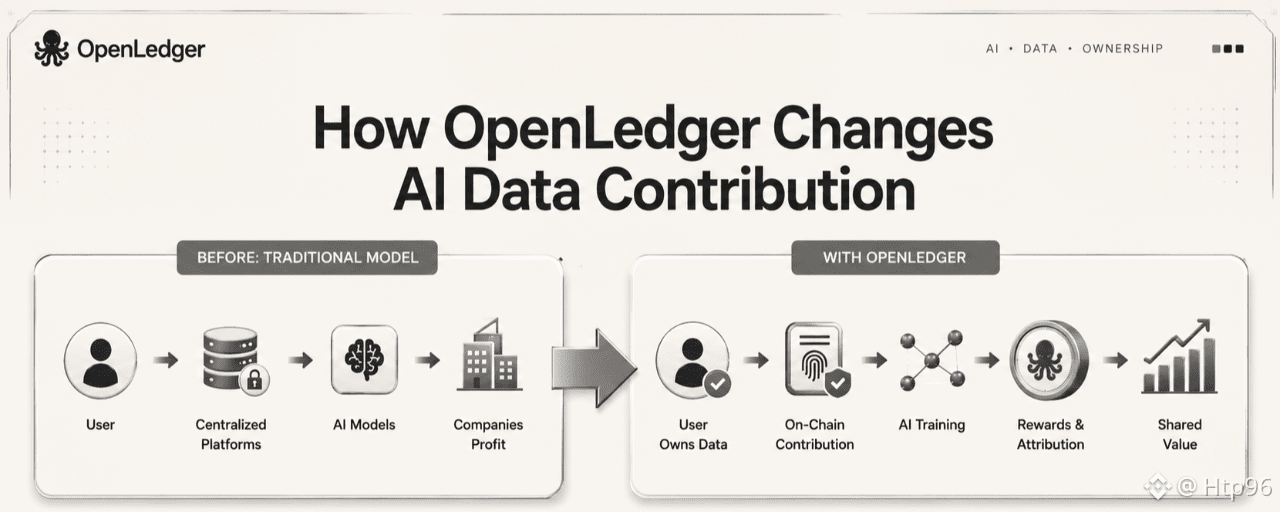
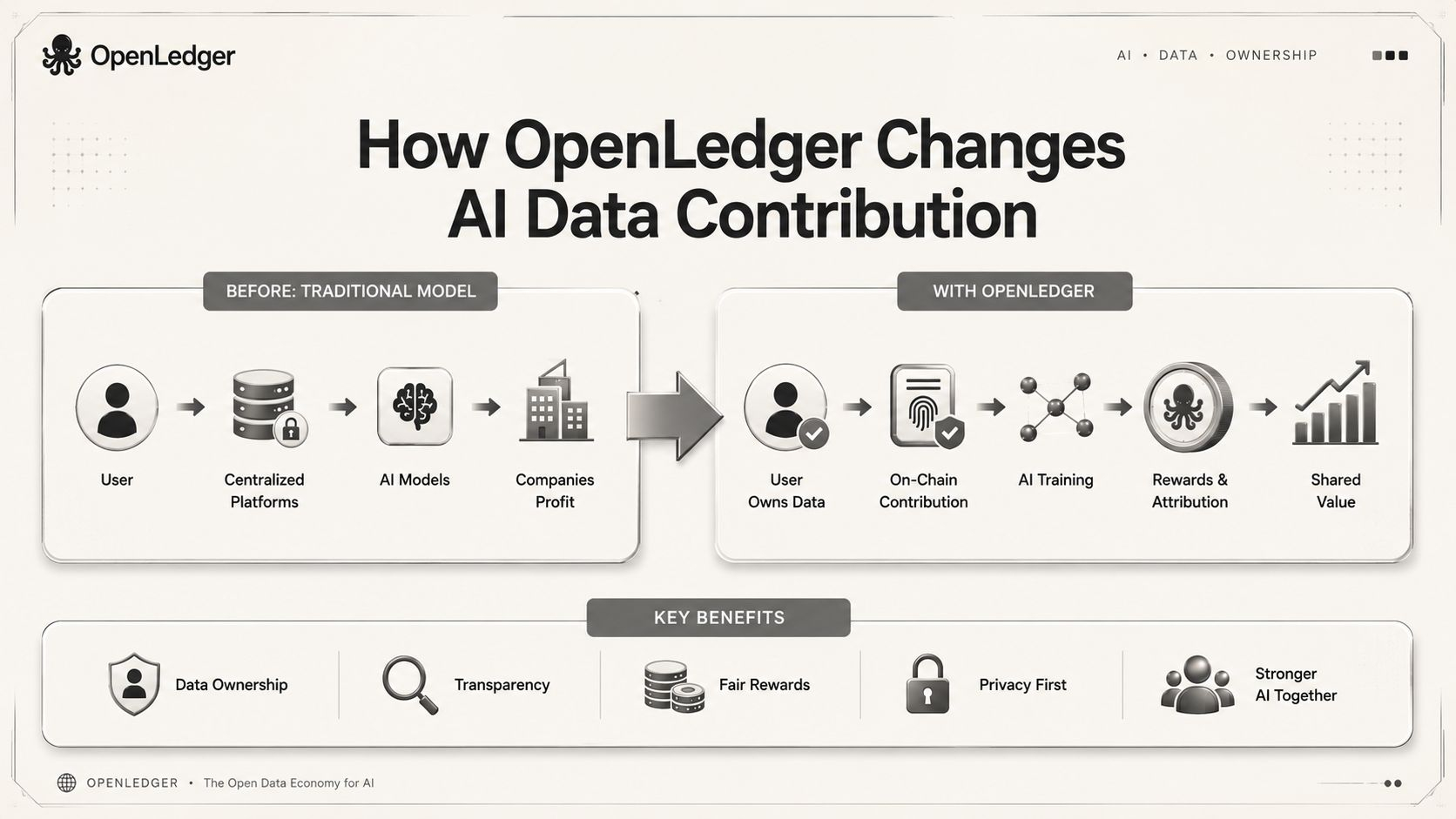
Mình đã theo dõi khá nhiều dự án AI crypto trong hai năm qua và nhận ra một pattern khá nhàm: phần lớn trong số đó đều có cùng một cấu trúc pitch.
Lấy một mô hình AI có sẵn, bọc thêm một lớp token vào, gọi nó là phi tập trung, và bán narrative về tương lai của AI thuộc về cộng đồng.
Token pump một đợt theo hype AI, rồi dần về lại giá trị thật khi không ai có thể giải thích được token đó đang làm gì cụ thể trong hệ.
Câu hỏi mình luôn đặt ra với bất kỳ dự án AI crypto nào là: nếu bỏ token đi, phần còn lại có hoạt động không?
Và nếu có, token đang giải quyết vấn đề gì mà không có token thì không giải được?
Với phần lớn dự án AI crypto, câu trả lời cho câu hỏi thứ hai là không rõ ràng.
Token tồn tại để raise capital và tạo incentive ngắn hạn, không phải vì hệ thực sự cần token để vận hành đúng.
Đây là chỗ mình thấy OpenLedger $OPEN bắt đầu có sự khác biệt đáng nói, dù mình sẽ không nói nó hoàn hảo.
Thứ đầu tiên mình thấy khác là OpenLedger không cố xây một mô hình AI mới.
Đây là điểm quan trọng hơn nó nghe có vẻ.
Phần lớn dự án AI crypto đều bắt đầu bằng tham vọng xây mô hình riêng, vì đó là thứ nghe impressive nhất trong pitch deck.
Nhưng xây mô hình AI cạnh tranh với GPT-4 hay Claude đòi hỏi nguồn lực tính toán và dữ liệu ở quy mô mà gần như không dự án crypto nào có thể tiếp cận.
Kết quả là họ thường end up với một mô hình yếu hơn nhiều so với những gì đã có sẵn, wrapped trong một lớp token và gọi đó là đổi mới.
OpenLedger đang cố làm thứ khác.
Thay vì cạnh tranh ở lớp mô hình, họ đang cố xây lớp hạ tầng kinh tế bên dưới, nơi dữ liệu được đóng góp, định giá, và phân phối reward theo cơ chế on-chain.
Đây là một bài toán khó hơn về mặt cơ chế nhưng thực tế hơn nhiều về mặt nguồn lực, và quan trọng hơn là nó giải quyết một vấn đề thật mà lớp mô hình không tự giải quyết được.
Thứ hai là cách OpenLedger tiếp cận vấn đề dữ liệu khác với hầu hết dự án cùng mảng.
Trong AI, dữ liệu là thứ tạo ra sự khác biệt thật sự giữa mô hình tốt và mô hình trung bình.
Không phải kiến trúc, không phải compute, mà là chất lượng và đa dạng của dữ liệu huấn luyện.
Các công ty AI lớn hiểu điều đó rất rõ, đó là lý do họ đổ nguồn lực khổng lồ vào việc thu thập và làm sạch dữ liệu.
Phần lớn dự án AI crypto bỏ qua vấn đề dữ liệu hoàn toàn hoặc giải quyết nó theo cách rất bề mặt.
Họ nói về “community-contributed data” như thể chỉ cần người dùng upload thứ gì đó lên là xong, mà không có cơ chế nào để đảm bảo dữ liệu đó có chất lượng, không trùng lặp, hay thật sự hữu ích cho việc huấn luyện.
OpenLedger đang cố xây lớp verification và quality assessment cho dữ liệu đóng góp, để reward chảy về phía dữ liệu chất lượng cao thay vì chỉ về phía dữ liệu nhiều về số lượng.
Đây là thứ cần thiết để cơ chế đóng góp cộng đồng hoạt động được trong thực tế, không phải chỉ trên giấy.
Thứ ba là vị trí của token trong hệ.
Mình để ý trong OpenLedger, token không chỉ là phương tiện raise capital hay governance voting tool theo nghĩa tượng trưng.
Nó đang cố gắng trở thành đơn vị đo lường và thanh toán cho giá trị thật bên trong hệ, từ reward cho người đóng góp dữ liệu, đến thanh toán cho người chạy node xử lý inference, đến phí truy cập mô hình từ phía người dùng doanh nghiệp.
Khi token có vòng lặp kinh tế thật bên trong hệ, nó không còn phụ thuộc hoàn toàn vào kỳ vọng bên ngoài để có giá trị.
Đó là thứ phân biệt một token có utility thật với một token chỉ có narrative.
Tất nhiên mình cũng thấy những điểm mình chưa chắc với OpenLedger.
Bài toán measurement vẫn là câu hỏi lớn nhất.
Để reward phân phối đúng theo chất lượng đóng góp, hệ phải đo được chính xác đóng góp đó có giá trị như thế nào với output của mô hình.
Đây là vấn đề kỹ thuật cực kỳ khó và chưa có giải pháp hoàn hảo ngay cả trong nghiên cứu học thuật, chứ không chỉ trong Web3.
Nếu lớp measurement bị méo, toàn bộ cơ chế reward sẽ bị khai thác theo hướng sai.
Người tối ưu hóa cách đo sẽ thắng, không phải người đóng góp dữ liệu thật sự chất lượng.
Và đó là cách nhiều hệ incentive đẹp trên giấy chết trong thực tế.
Nhưng so với phần lớn dự án AI crypto mà mình đã theo dõi, #openLedger ít nhất đang đặt đúng câu hỏi và đang cố xây đúng lớp để trả lời câu hỏi đó.
Trong một không gian đầy dự án đang bán narrative AI mà không có gì bên dưới, đó đã là sự khác biệt đáng chú ý.
Mình sẽ tiếp tục theo dõi phần thực thi, vì đó mới là chỗ mọi thứ thường vỡ hoặc không vỡ.
@OpenLedger #OpenLedger $OPEN