
I used to think the hard part of AI was mostly building the model but OpenLedger makes me look at the problem from a wider angle. My sense is that its real argument is not “put AI on a blockchain” so much as “make the whole life of a model accountable from the first proposal to the moment someone actually uses it.” The idea sounds simple at first yet it changes where the value is supposed to sit.
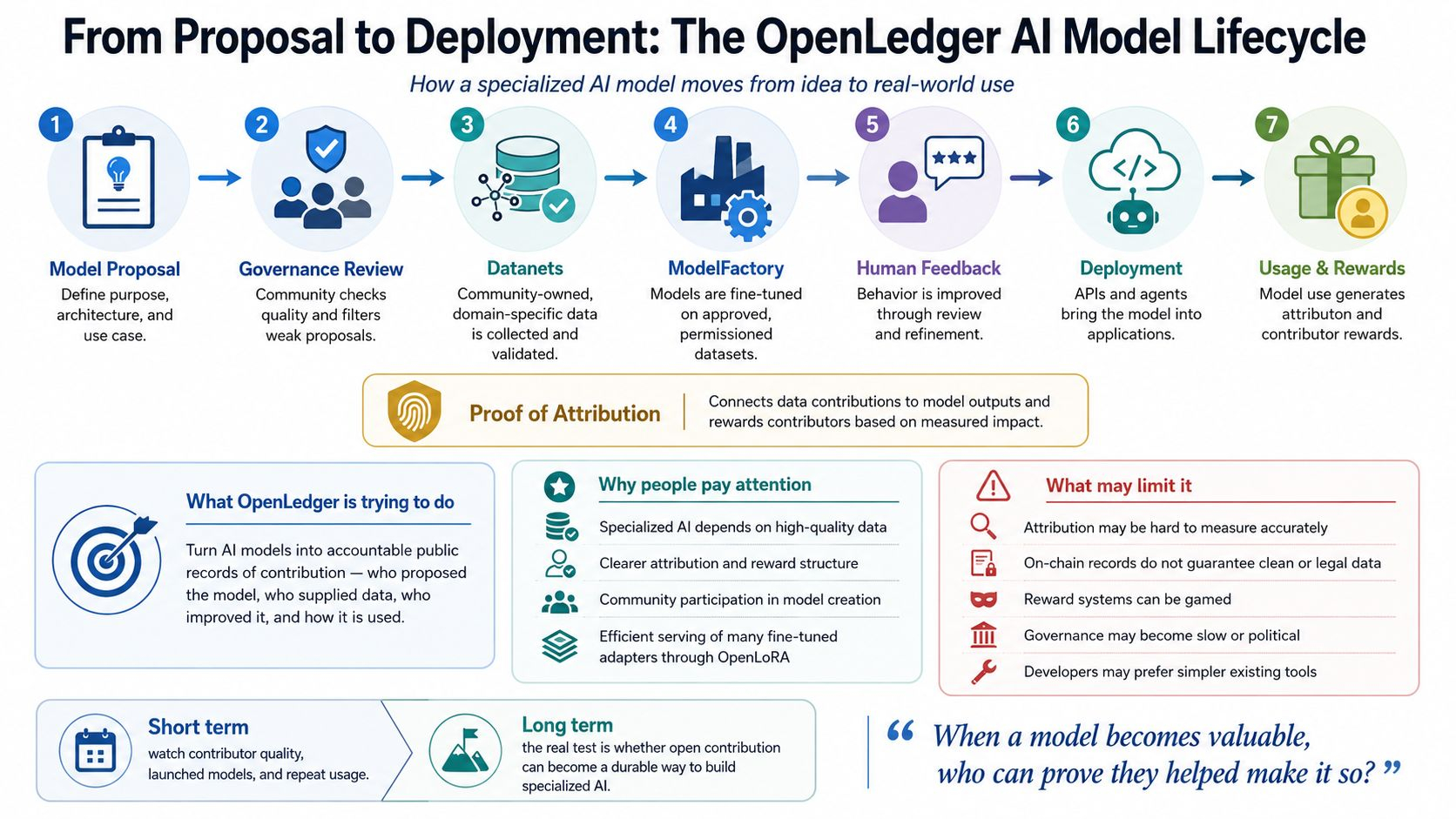
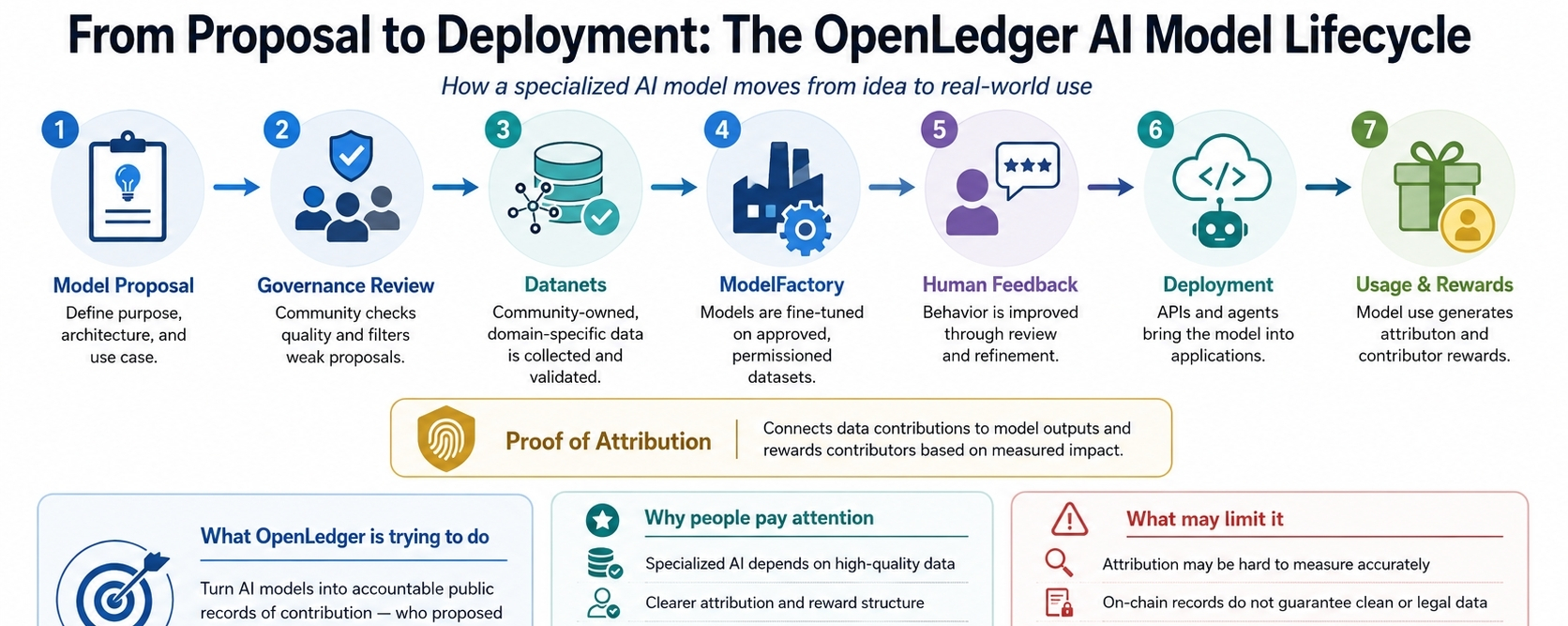
OpenLedger describes itself as infrastructure for training and deploying specialized AI models with community owned datasets called Datanets. The system brings uploads training rewards and governance activity onto the chain so the model can carry a record of how it came together. In plain terms the project is trying to make a model less like a closed product and more like a public record of contribution. It asks who suggested the model who supplied the data who helped improve it and how the finished system is used. Its documentation says Datanets collect and validate domain specific data while Proof of Attribution connects data contributions to model outputs and rewards contributors according to their measured impact.
I find the lifecycle useful because it forces a project to answer a question that normal AI development often pushes aside. Why should this model exist at all? OpenLedger’s whitepaper frames the process as starting with a model proposal where developers explain the purpose architecture and use case. Staking may be used to reduce spam. After that governance reviews the proposal and the project moves toward data gathering model tuning human feedback and eventual use through APIs or agent integrations. This is more than a workflow because it also works as an economic filter. The theory is that models should move forward when there is enough interest useful data and real participant commitment behind them.
That is the strongest part of the idea in my view. AI becomes more practical when it is narrower better sourced and closer to a real task. A general chatbot may be impressive but a specialized model for fields such as medical notes legal research environmental data or customer support depends heavily on data quality. OpenLedger is paying attention to that point. Its ModelFactory is presented as a fine tuning tool that uses permissioned and approved datasets. OpenLoRA is designed to serve many fine tuned adapters efficiently instead of treating every specialized model as a separate heavy deployment.
What surprises me is that the short term appeal and the long term challenge are closely connected. In the short run the market can understand the story because attribution rewards and shared model value are easy ideas to follow. Traders and investors may watch whether Datanets attract serious contributors and whether developers actually launch useful models. They may also look for repeat demand from inference usage rather than one time attention. Another important question is whether rewards go to genuinely useful inputs or to people who learn how to game the system.
Longer term I think the central question is whether attribution can be accurate enough to matter. Recording activity on chain does not automatically prove that data is legally clean high quality or meaningfully responsible for a model’s answer. Measuring influence at inference time is a hard technical and social problem. If the system over rewards noisy data or if governance becomes popularity politics then the lifecycle could feel elegant on paper but heavy in practice. The same could happen if developers find the process slower than existing tools.
My thesis is that OpenLedger’s model lifecycle is most interesting not as a replacement for today’s AI platforms but as a test of whether open contribution can become a durable production method. Right now the project’s value depends on execution through usable tools credible attribution useful models and real demand. Later if those pieces hold together the bigger idea is that AI models may need supply chains as visible as software repositories and payment systems. I am not convinced that every model needs this structure. I am convinced that specialized AI built from many people’s data and labor raises one uncomfortable question that OpenLedger is trying to answer. When a model becomes valuable who can prove they helped make it so?


