Continu să urmăresc @OpenLedger și încerc să-mi dau seama dacă dataneturile contribute de comunitate produc date de calitate sau dacă descentralizarea colectării datelor înseamnă doar descentralizarea gunoiului la scară.
Ceea ce urmăresc nu este dacă infrastructura de atribuire funcționează. Urmărirea a cine a contribuit cu ce este o problemă rezolvată din punct de vedere ingineresc. Ceea ce urmăresc este dacă datele contribuie efectiv cu ceva valoros sau dacă stimularea contribuției creează cantitate fără calitate.
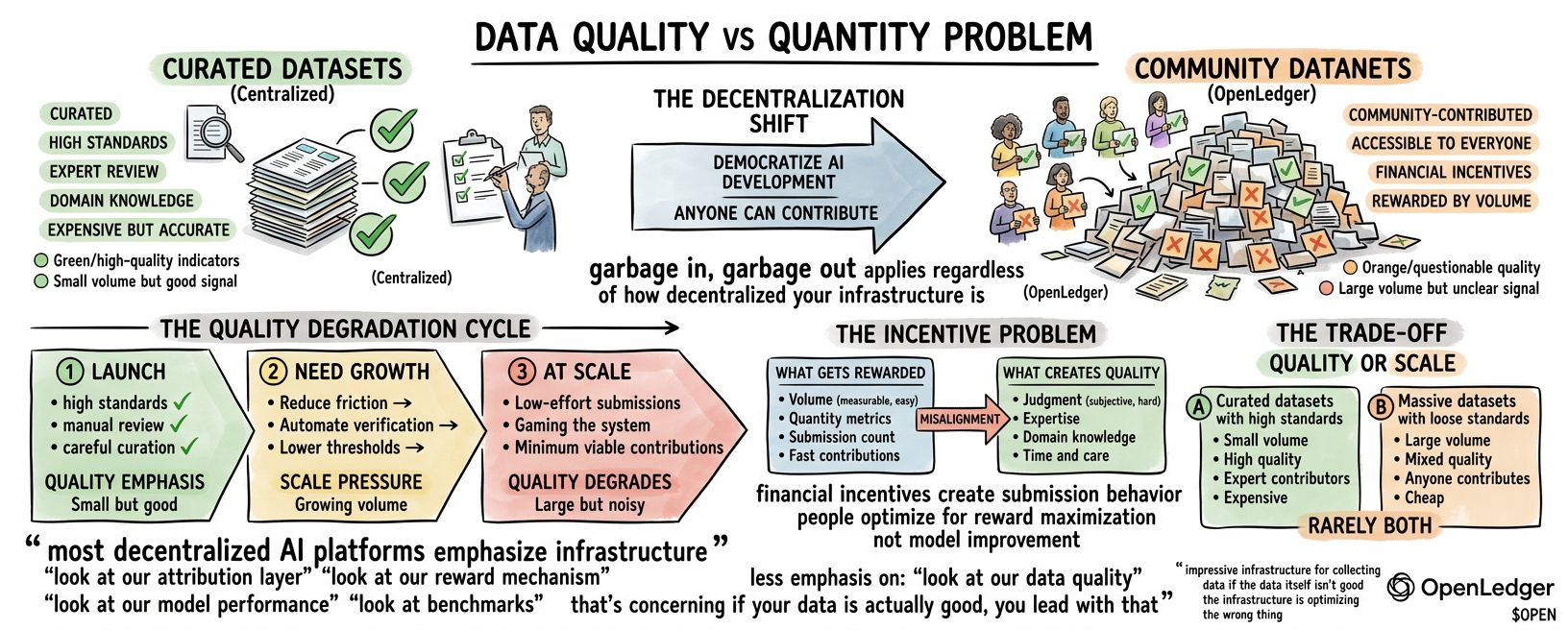
Problema calității datelor în AI descentralizat.
Nu mecanismul de verificare. Provocarea fundamentală de a te asigura că atunci când recompensezi oamenii pentru contribuirea de date, ei contribuie cu date bune în loc să manipuleze sistemul de recompense cu trimiteri de minim efort care trec standardele minime dar nu îmbunătățesc performanța modelului.
Această distincție contează pentru că gunoiul intră, gunoiul iese se aplică indiferent de cât de decentralizată este infrastructura ta.
OpenLedger permite oricui să creeze datanete sau să contribuie la cele existente. Contributorii încarcă date, le verifică pe blockchain și câștigă recompense. Cu cât contribui mai mult, cu atât câștigi mai mult.
Ce nu pot spune este dacă "accesibil pentru toată lumea" produce seturi de date valoroase sau dacă produce zgomot care diluează semnalul.
Provocarea este că stimulentele financiare creează comportamente de trimitere. Când plătești oamenii pentru a contribui cu date, ei contribuie cu date. Dar datele pe care le contribuie optimizează pentru maximizarea recompensei, nu neapărat pentru îmbunătățirea modelului.
Cele mai multe colectări de date crowdsourced se confruntă cu această problemă. Ai nevoie de volum. Așa că reduci barierele. Recompensezi cantitatea.
Și primești trimiteri de minim efort. Manipulând sistemul. Contribuții minime viabile care se califică pentru plată dar nu adaugă valoare.
@OpenLedger are mecanisme de verificare. Datele sunt revizuite. Există control al calității.
Ce urmăresc este dacă acele mecanisme funcționează la scară sau dacă funcționează inițial și se rup când volumul crește și verificarea devine costisitoare în raport cu recompensele.
Cele mai multe platforme încep cu standarde ridicate. Apoi au nevoie de creștere. Așa că reduc frecarea. Automatizează verificarea.
Și calitatea se degradează. Treptat. Setul de date crește, dar calitatea medie a contribuțiilor scade.
Poate OpenLedger a rezolvat asta. Poate verificarea lor se scalează fără degradare.
Poate nu au făcut-o și se confruntă cu aceeași alegere. Calitate sau scară. Poți avea seturi de date curate cu standarde înalte. Sau seturi de date masive cu standarde slabe. Rareori ambele.
Riscurile pentru performanța modelului depind de dacă stimulentele de contribuție sunt aliniate cu calitatea sau doar cu cantitatea. Dacă recompensele se corelează cu îmbunătățirea reală a modelului, contributorii optimizează pentru calitate. Dacă recompensele se corelează cu volumul, contributorii optimizează pentru volum.
Cele mai multe sisteme de recompense optimizează pentru lucruri măsurabile. Volumul este măsurabil. Calitatea este subiectivă. Așa că sistemele recompensează volumul și speră că calitatea va urma.
De obicei nu funcționează. Calitatea necesită judecată. Expertiză. Cunoștințe de domeniu. Timp. Acestea sunt costisitoare. Volumul este ieftin.
Prefer să văd dovezi că datanetele OpenLedger produc modele mai bune decât alternativele centralizate. Nu doar seturi de date mai mari. Performanță mai bună a modelului.
Dacă modelele antrenate pe datele OpenLedger performează similar sau mai rău, atunci descentralizarea nu aduce valoare.
Întrebarea calității datelor contează pentru că modelele AI sunt doar la fel de bune ca datele lor de antrenament. Poți avea infrastructură perfectă, atribuire transparentă, compensație corectă. Dacă datele subiacente sunt mediocre, modelele tale vor fi mediocre.
Cele mai multe platforme AI descentralizate subliniază infrastructura lor. Uitați-vă la stratul nostru de atribuire.
Mai puțin accent pe: uitați-vă la calitatea datelor noastre. Uitați-vă la performanța modelului.
Asta e îngrijorător. Dacă datele tale sunt de fapt bune, te promovezi cu asta. Dacă infrastructura ta este impresionantă dar datele tale sunt discutabile, vorbești despre infrastructură.
Poate, OpenLedger are date puternice. Poate, modelele lor performează bine. Poate nu am văzut standardele de referință. pentru că nu le-au publicat încă.
Poate, datele sunt mediocre și speră că volumele compensează pentru calitate.
Asta ar putea funcționa pentru unele cazuri de utilizare. Mai multe date pot depăși calitatea mai slabă dacă ai suficient compute.
Nu funcționează pentru domenii specializate. Date medicale, date legale, date științifice. Nu poți compensa contribuțiile de calitate scăzută cu volum.
Privesc să văd ce tip de AI devine OpenLedger. Modele generice unde volumul contează? Sau modele specializate unde calitatea este critică?
Întrebarea calității datelor este fundamentală. Poți construi o infrastructură impresionantă pentru colectarea și atribuierea datelor. Dacă datele în sine nu sunt bune, infrastructura optimizează lucrul greșit.
Și, sincer, am încredere în platformele care pun accent pe performanța modelului mai mult decât în platformele care pun accent pe infrastructură evitând în același timp comparațiile de performanță.
