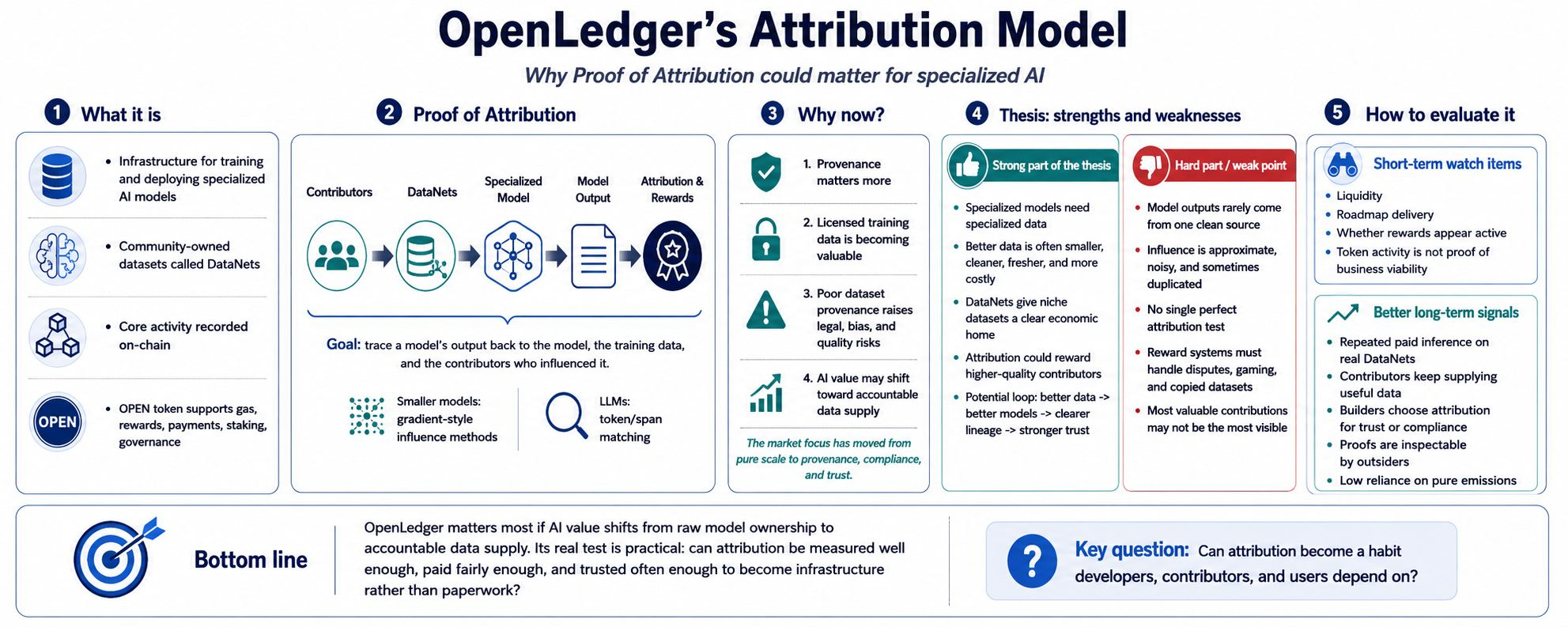

I keep coming back to OpenLedger’s attribution model because it asks a question AI usually leaves vague: who actually helped produce this output? My first instinct was to see it as a payment system for data contributors but that feels too narrow because the deeper idea is that data influence should become visible and measurable instead of disappearing inside a model.
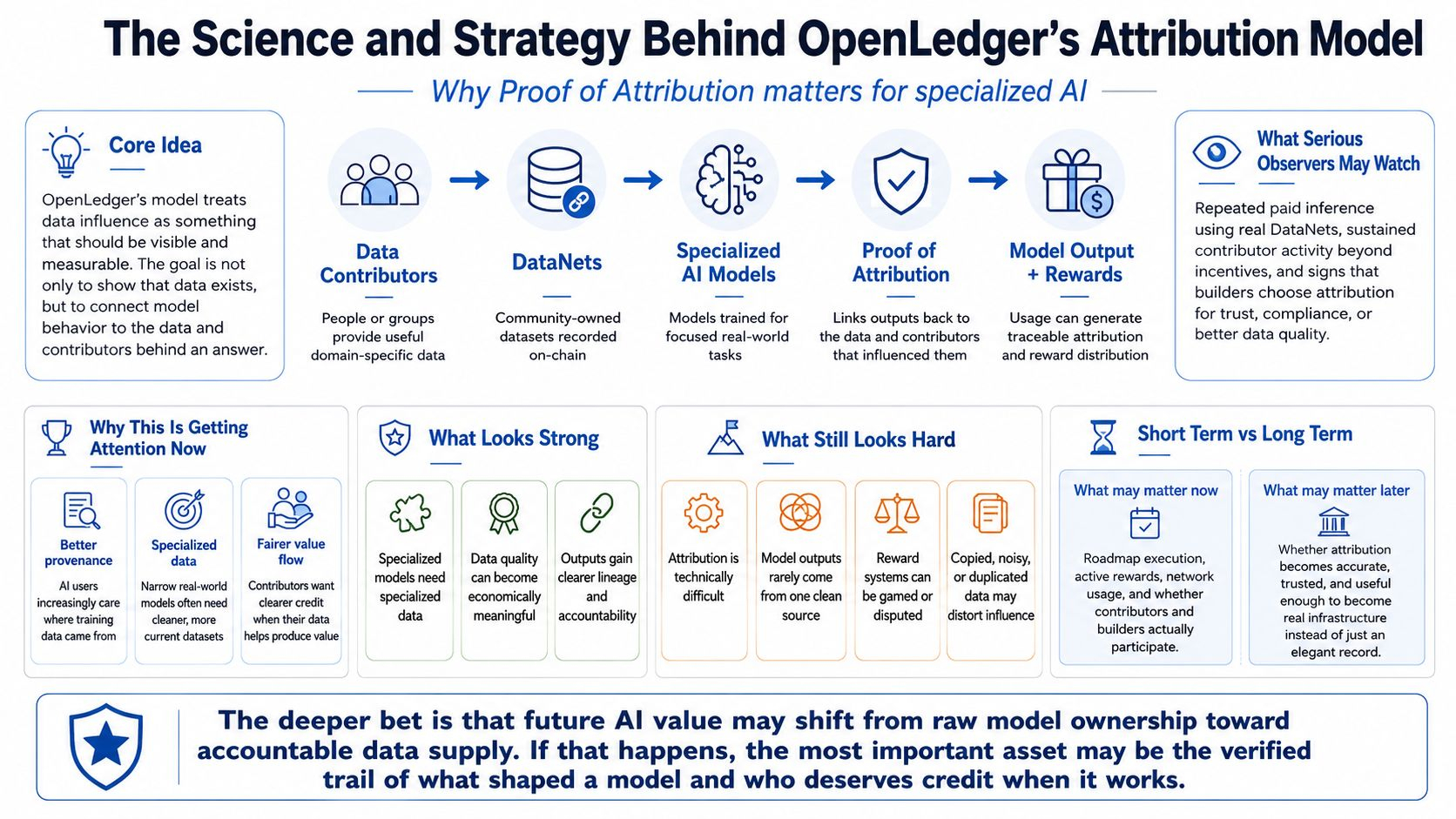
OpenLedger describes itself as infrastructure for training and deploying specialized AI models through community-owned datasets called DataNets with core activity recorded on-chain. Its docs also say that when a model is used the system should be able to trace the model and the data behind it along with the contributors involved. That is the center of Proof of Attribution. It is not just about proving that data exists but about connecting data to model behavior when an answer is produced. OpenLedger’s paper frames this as a way to link outputs back to training data and distribute rewards according to influence by using gradient-style methods for smaller models and token or span matching for larger language models.
I find it helpful to look at the model as a bet on scarcity. Five years ago the loudest AI story was scale through more data and bigger models with more compute behind them. Today the pressure has moved closer to provenance as companies and publishers and researchers and regulators ask where training data came from and whether it was licensed and whether it creates bias or leaves contributors outside the value chain. Reuters has reported on large technology companies seeking licensed training data while MIT Sloan has pointed to legal risk and bias and lower model quality as problems tied to poor dataset provenance. That does not prove OpenLedger’s approach will win but it does explain why the idea feels timely.
The strong part of the thesis is the link between specialized models and specialized data. If a model is meant to answer questions in healthcare or law or mapping or finance or another narrow field then generic web data is not enough. Better data may be smaller and cleaner and more current and more expensive to gather. OpenLedger’s DataNet structure tries to give that data a home while the attribution layer tries to make contribution quality economically meaningful. In theory that creates a useful loop where better contributors earn more while builders get cleaner datasets and users receive outputs with clearer lineage.
The weak point is also clear because attribution is hard and a model output is rarely caused by one clean source. Influence can be approximate or duplicated or noisy or dependent on how the system defines similarity. OpenLedger’s paper is sensible in describing different methods for different model sizes but that also shows the challenge because there is no single magic test that perfectly proves why a model said what it said. A reward system built on imperfect attribution has to manage disputes and gaming and copied datasets along with cases where the most valuable contribution is not the most visible one.
For market participants I would separate the short-term story from the long-term one. In the near term people may watch liquidity and roadmap delivery and whether rewards look active. OPEN is described as the network’s gas token and is also tied to attribution rewards and payments and staking and governance. That can matter for trading but it is not the same as proving the business model. The better signal in my view would be repeated paid inference using real DataNets with contributors who keep supplying data without relying only on incentives and builders choosing attribution because it improves trust or compliance. If rewards mostly come from emissions or if proofs are hard for outsiders to inspect then conviction should weaken.
My thesis is that OpenLedger’s attribution model matters most if AI value moves from raw model ownership toward accountable data supply. In that world the important asset is not just the model. It is the verified trail of what shaped the model and who deserves credit when it works. OpenLedger has a clear reason to exist but its hardest test is practical: can it turn attribution from an elegant record into a habit that developers and contributors and users actually depend on? That is where the long-term question sits because the real issue is whether attribution can be measured well enough and paid fairly enough and trusted often enough to become infrastructure rather than paperwork.

