
我有个做区块链开发的朋友前两年一直在以太坊上面做项目。
有次聊天他跟我说了一句话,我一直记着:以太坊是一把很好的锤子,但不是所有东西都是钉子。
他当时说的是 DeFi 的性能瓶颈问题。但我最近读完 @OpenLedger 白皮书之后,得这句话用在 AI 和区块链的关系上,更准确。
以太坊和 Solana 设计出来是为了解决什么问题?
金融交易。资产转移。数字所有权。
这些东西的核心需求是:记录谁拥有什么确保转移过程不可篡改,保证合约执行确定性。
这套逻辑在 DeFi 和 NFT 里跑得很好。但放到 AI 开发里问题来了。
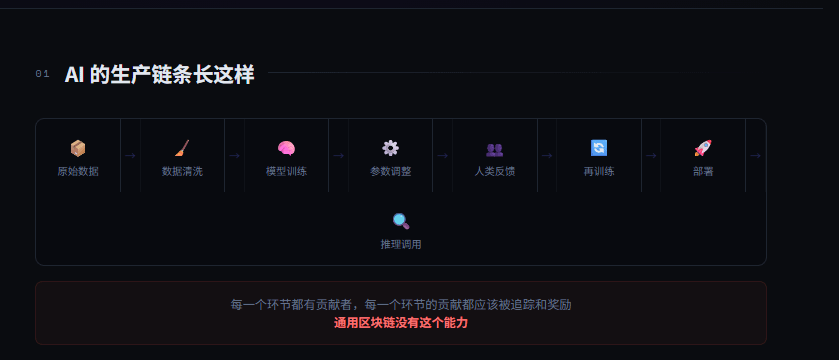
AI 的生产过程不是一笔交易是一条漫长的链条。
原始数据 → 数据清洗 → 模型训练 → 参数调整 → 人类反馈 → 再训练 → 部署 → 推理调用。每一个环节都有贡献者每一个环节的贡献都应该被追踪和奖励。
通用区块链没有这个能力。
白皮书里说得很直接:通用区块链缺乏原生的归因支持 模型版本控制与结构化数据流,以及细粒度的奖励系统。它们无法表示一个 AI 系统从原始数据到部署模型的完整生命周期。

换句话说你把以太坊当 AI 基础设施用,就像用银行的转账系统来管理一家工厂的生产流程——不是不能用,是根本不是为这件事设计的。
具体差在哪里白皮书里有一张对比表我展开说一下。
以太坊没有原生的数据归因追踪。
你可以在链上记录一笔交易但你没办法追踪「这条训练数据对这个模型输出贡献了多少」。#OpenLedger 的 Proof of Attribution 是专门为这件事设计的,用影响力函数计算每条数据对模型输出的实际影响,然后按比例分配推理收益。
以太坊的奖励给验证者和矿工是对维护网络安全的人的补偿。OpenLedger 的奖励给数据贡献者和模型开发者,是对创造 AI 价值的人的补偿。这两套激励结构针对的是完全不同的行为。
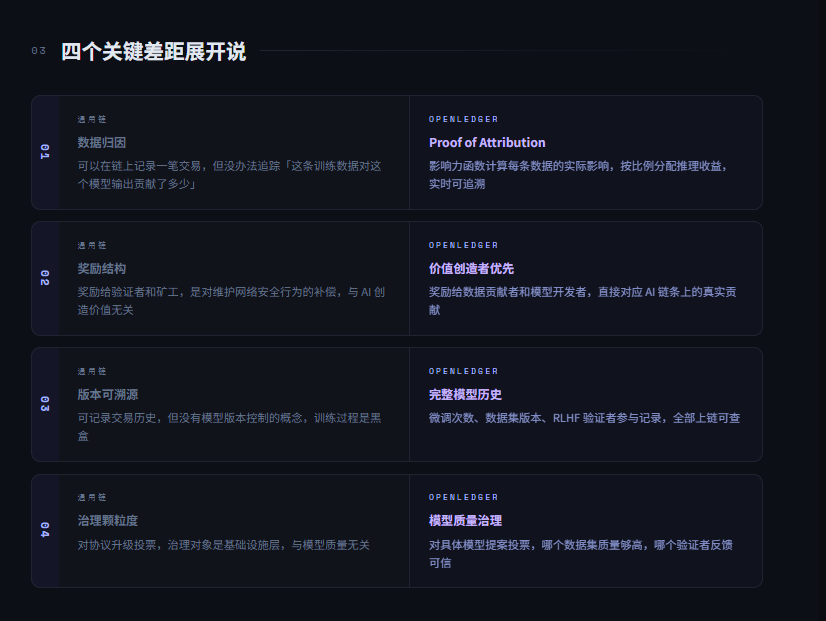
通用区块链可以记录交易历史,但没有模型版本控制的概念。一个模型经历了多少次微调、每次用了哪个版本的数据集、RLHF 阶段哪些验证者参与了评分
这些在以太坊上根本没有对应的数据结构。OpenLedger 模型的完整发展历史可查。
以太坊的治理投票是对协议升级的投票。OpenLedger 的治理投票是对模型质量的投票
哪个模型提案值得推进集质量够高,哪个验证者的反馈可信。治理的颗粒度完全不同。
我得说一个容易被忽略的细节。
OpenLedger 没有说要取代以太坊白皮书里用的词是「EVM 兼容」。底层还是跑在以太坊的安全性和流动性上,用 rollup 做扩展保留了以太坊生态的接入能力。
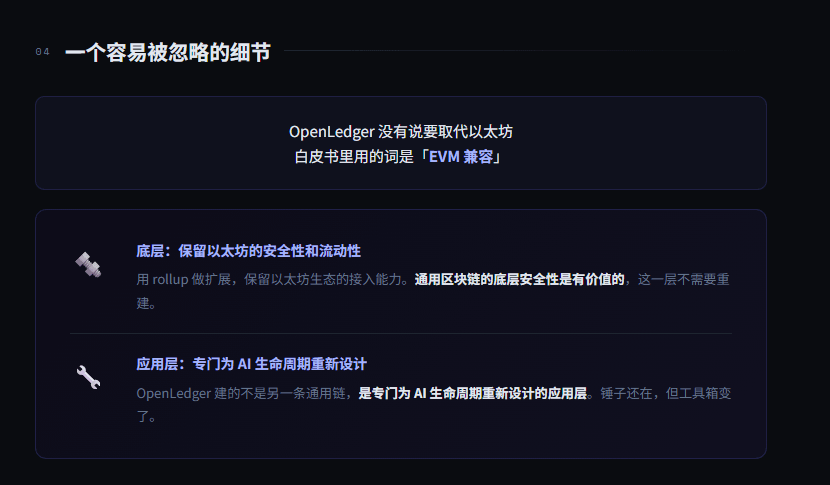
这个选择本身说明一件事:通用区块链的底层安全性是有价值的,但上面的应用层需要重新设计。OpenLedger 建的不是另一条通用链是专门为 AI 生命周期重新设计的应用层。
就像我朋友说的以太坊是一把很好的锤子。
OpenLedger 不是换一把新的锤子,是专门为 AI 这颗钉子重新设计了一套工具。
这件事在 AI 监管收紧的背景下变得更重要。欧盟 AI 法案要求高风险 AI 系统能够解释决策逻辑,能够追溯训练数据来源。通用区块链给不了这个,OpenLedger 的链上归因记录天然满足这个要求。

$OPEN 合规不是加分项,在监管收紧之后是准入门槛。能提供完整训练历史和数据溯源的 AI 基础设施