
刚开业的时候只有一台制冰机,每天能出的杯数有上限。后来他换了个思路
不买更多制冰机,改成共享制冰设备,整条街的奶茶店都接进来,设备利用率从30%拉到90%,每家店的边际成本都降了。
他跟我说:关键不是你有多少设备,是设备在不在跑。
我读 @OpenLedger 白皮书里 OpenLoRA 那部分的时候,想到的就是这件事。
先说现有 AI 模型部署的问题是什么。
传统部署方式是一个模型一个实例——你有一个微调过的医疗诊断模型,你需要一台 GPU 跑它;你再有一个法律文书分析模型,你再需要一台 GPU 跑它;金融风险评估模型,再一台。三个模型,三台 GPU,三份成本,三份维护。
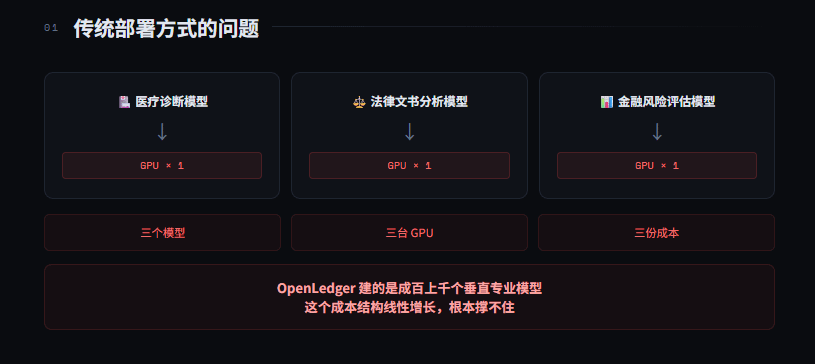
这在通用大模型时代勉强说得过去,因为大家用的是同一个底座,场景差异不大。但 OpenLedger 建的是垂直专业模型每个领域一个深度微调的模型,数量不是三个,是成百上千个。
一个模型一台 GPU,这个成本结构在垂直模型时代根本撑不住。
OpenLoRA 白皮书里的描述是:单块 GPU 可以托管数千个 LoRA 微调模型。
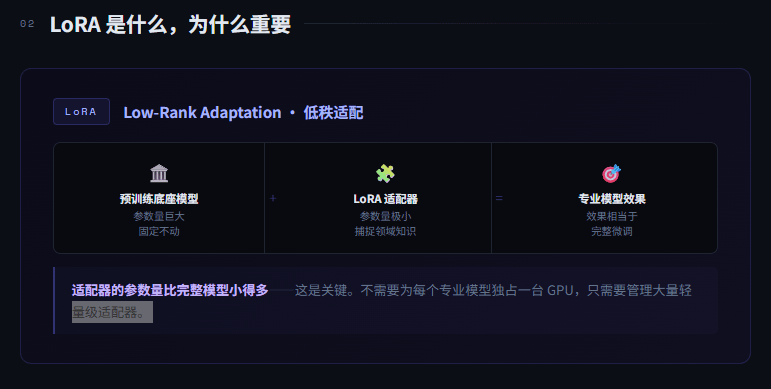
LoRA 是什么。Low-Rank Adaptation,低秩适配。
核心思想是:不需要重新训练整个模型,只需要在预训练好的底座模型上加一小层适配器,这层适配器捕捉特定领域的知识,推理的时候底座模型加上适配器一起跑,效果相当于完整的专业模型。
适配器的参数量比完整模型小得多,这是关键。
OpenLoRA 的多租户架构是:所有专业模型共享同一个预训练底座,存在 GPU 显存里不动;不同模型的 LoRA 适配器按需动态加载,用的时候加载进来用完卸载下一个模型的适配器接着加载。
不是每个模型占一台 GPU,是一台 GPU 按需调度数千个模型的适配器。
白皮书里还提到 SGMV——Segmented Gather Matrix-Vector Multiplication,批量执行多个 LoRA 适配器的计算,让不同模型的推理请求可以同时处理不互相等待。
这件事的意义我觉得有三层。

第一层是成本。垂直模型的价值在于专业性,但专业性意味着数量多单个使用频率相对低。如果每个模型都要独占一台 GPU,大多数时候这台 GPU 是闲着的。
OpenLoRA 把闲置成本分摊掉了,让低频使用的垂直模型在经济上变得可行。
第二层是规模。OpenLedger 的 Datanets 设计允许任何领域建立独立的数据集,理论上可以支持无限多个垂直场景的专业模型。
但这个「无限多」能不能真的实现,取决于部署层能不能撑得住。OpenLoRA 解决了这个天花板——数千个模型跑在同一块 GPU 上,供给侧的扩张不再受硬件成本线性约束。
第三层是生态。当部署成本足够低,开发者提交一个垂直模型的门槛就降低了。门槛降低,模型数量增加生态覆盖的场景更广,更多企业用户愿意接入推理调用增加,数据贡献者的收益增加,模型质量提升。
当然数千个模型共享一块 GPU,调度的复杂度是真实的。
不同模型的推理请求同时到来,底座模型一样但适配器不同批量处理的时候怎么保证不同模型之间不互相干扰、每个请求的延迟在可接受范围内——这是工程问题,不是概念问题。
白皮书里说用了 KvCache 动态管理和请求迁移机制来处理这个问题,但细节层面的实际表现,上线之后才能真正验证。

共享带来效率也带来单点风险。这个权衡在 OpenLoRA 上同样存在,只是规模更大。一块 GPU 跑数千个模型,这件事本身不是终点。
它是让垂直 AI 模型经济上可行的前提条件。没有这一层专业模型的叙事再好,落地的成本结构也撑不住。
$OPEN 建的东西里,OpenLoRA 是最容易被忽略的一块但它是整个系统能不能规模化的地基。