

Набор цифр, который оставляет в замешательстве.
В марте 2026 года директор Государственного статистического управления Лю Лэхун на высоком уровне форума по развитию Китая представил ряд цифр:
1000 миллиардов → 100 триллионов → 140 триллионов
Среднее количество вызовов токенов в нашей стране за день за два года увеличилось более чем натысячу раз.
Что еще более впечатляюще, некоторые модели компаний за 20 дней заработали больше, чем за весь прошлый год.
Честно говоря, когда я впервые увидел это число, я на несколько секунд застыл.
Дело не в том, насколько впечатляющи эти цифры.
В эпоху интернета мы видели слишком много историй о экспоненциальном росте.
А дело в том, что слово 'токен' вдруг из технического жаргона превратилось в экономический показатель, который можно обсуждать на высоком уровне форума.
Когда в речи руководителя бюро начинает появляться технический термин, это уже не просто техническая проблема, а экономическая.
Это напоминает мне примерно 2010 год, когда «трафик данных» был всего лишь техническим термином, используемым внутри телекоммуникационных операторов и интернет-компаний. Обычных людей не волновало, сколько мегабайт они потребляют каждый день. Но несколько лет спустя «тревога по поводу данных» стала общенациональной темой, и за ней последовали пакеты данных, карты данных и экономика данных.
Теперь история, кажется, повторяется, только главные герои превратились в слова.

Что же такое лексический элемент?
Технические специалисты вам скажут:
Токен — это наименьшая единица информации, обрабатываемая большой моделью. Это дискретный сегмент, который модель может понять, и который формируется путем сегментации текста на слова с использованием алгоритмов сегментации слов. Китайский иероглиф может быть токеном, английское слово может быть сегментировано на два или три части, а описание изображения может содержать сотни токенов.
Но это объяснение большинству людей кажется бессмысленным.
Иными словами: каждый раз, когда вы общаетесь с ChatGPT, позволяете ИИ писать код, генерировать изображение или даже просите агента забронировать рейс или упорядочить вашу электронную почту, вы потребляете токены в фоновом режиме. Поставщики моделей почти всегда взимают плату за токены.
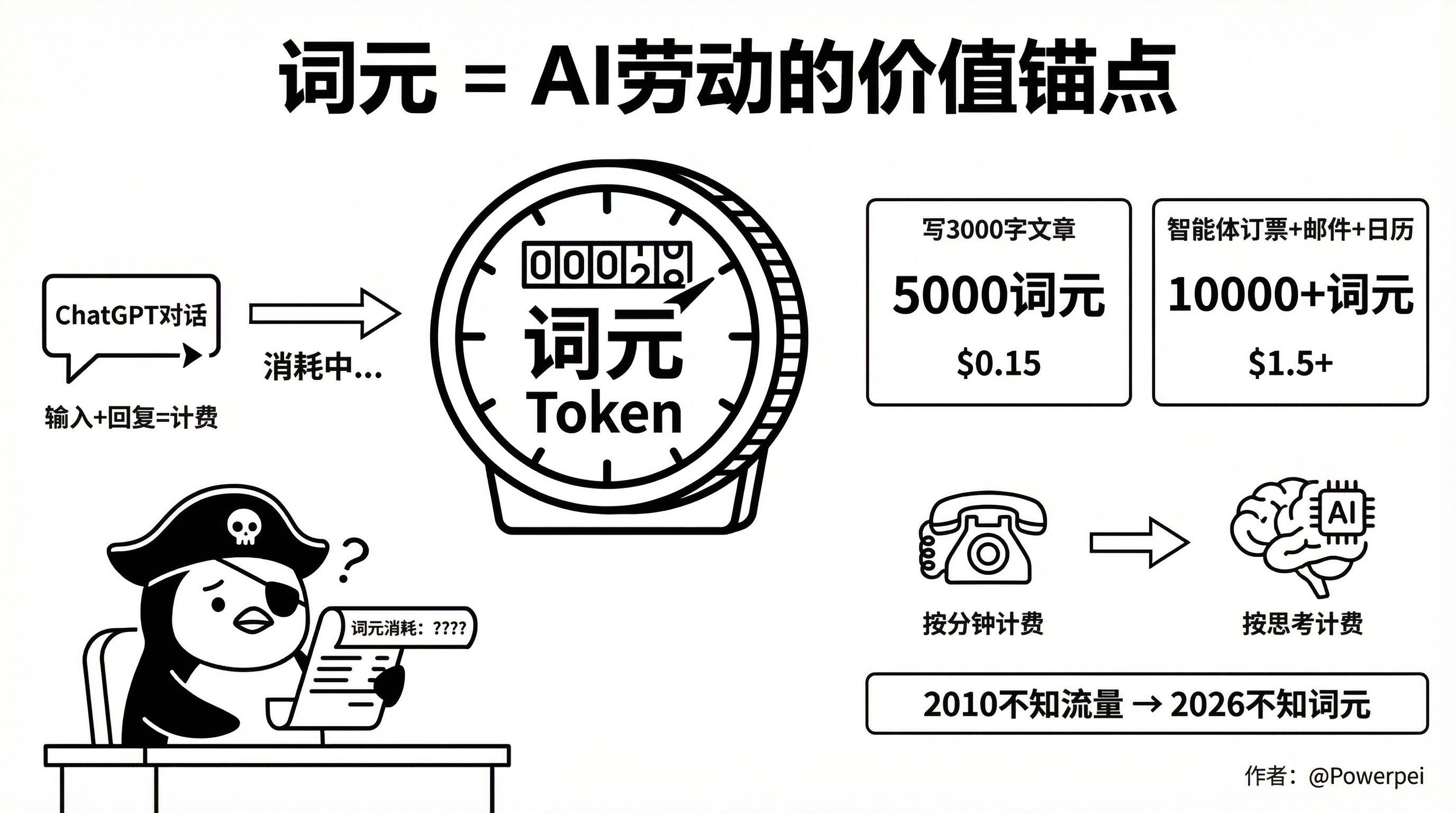
Стоимость вашего ввода и стоимость ответа ИИ отображаются наглядно.
Например
Напишите статью объемом 3000 слов, используя GPT-4.
→ Содержит приблизительно 5000 лексических единиц
→ Стоимость составляет приблизительно 0,15 доллара.
Пусть ИИ-агент выполнит задачи по бронированию авиабилетов, написанию электронных писем и обновлению календаря.
→ Объем потребляемой речи легко превышает 10 000 слов.
→ Затраты увеличились более чем в 10 раз
Это как телефонный звонок: раньше плата взималась за минуту, теперь же ИИ берет плату за количество мыслей. Только теперь мыслительный процесс выражен в словах.
Вопрос в том, знаете ли вы, сколько слов вы потребляете каждый месяц?
Точно так же, как в 2010 году люди не осознавали, сколько данных они использовали.
Национальное управление данных официально присвоило токену название «Экономическая единица», что является не просто вопросом перевода, но и признанием его экономических характеристик. Он определяется как якорь стоимости и расчетная единица в эпоху интеллектуальных технологий. Проще говоря, он обеспечивает количественный стандарт для оценки стоимости труда ИИ.
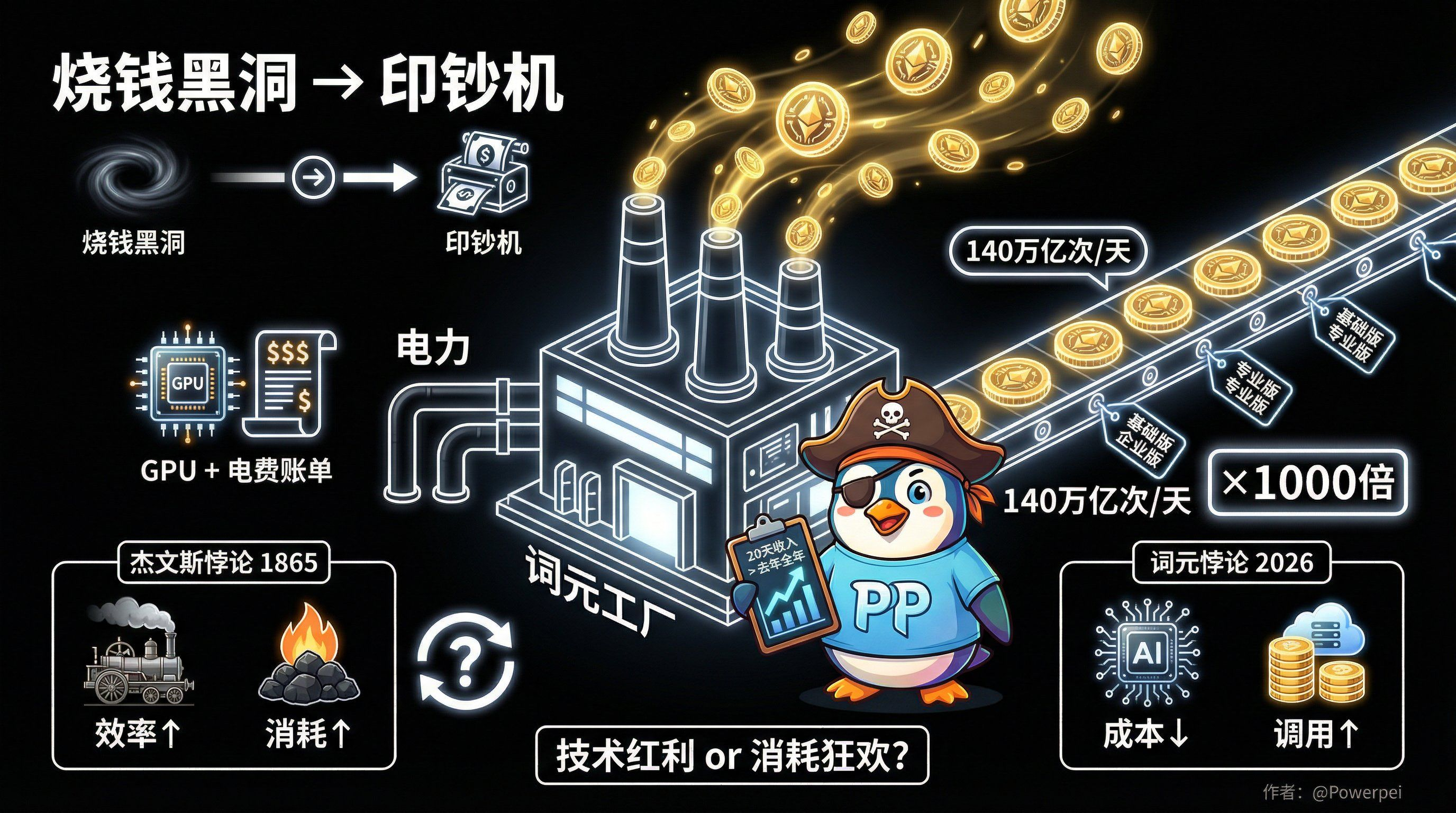
От черной дыры, сжигающей деньги, до машины для печатания денег.
Выручка ведущего производителя моделей за 20 дней превысила его общую выручку за весь предыдущий год.
За последние несколько лет мы слышали бесчисленное количество историй о компаниях, занимающихся искусственным интеллектом, которые растрачивают деньги впустую.
Обучение большой модели может легко обойтись в десятки миллионов долларов, покупка графических процессоров обходится так же дешево, как покупка капусты, а счета за электроэнергию могут не давать финансовому директору спать всю ночь.
В то время лексические единицы чаще рассматривались как статья расходов: сколько лексических единиц потребляется во время обучения, сколько лексических единиц потребляется во время вывода и как оптимизировать затраты, чтобы уменьшить их.
Но теперь ситуация изменилась.
Как только ИИ перейдет на стадию крупномасштабного применения, каждый пользовательский диалог и каждая задача, выполняемая интеллектуальным агентом, будут непрерывно потреблять словарный запас. Чем больше слов потребляется, тем больше продают производители.
Слово «стоимость» трансформировалось в «товар», который можно производить массово, устанавливать многоуровневые цены и торговать в больших масштабах.
Лексическая фабрика Хуан Жэньсюня
На конференции GTC 2026 генеральный директор Nvidia Дженсен Хуанг напрямую предложил концепцию «метаэкономики».
Он переосмыслил понятие центра обработки данных как «лексическую фабрику»:
Звучит здорово, правда? Но вот в чем проблема: разве это не превратит компании, занимающиеся искусственным интеллектом, в «преобразователей электроэнергии»? Вы потребляете электроэнергию для создания слов, я потребляю электроэнергию для создания слов, и в конечном итоге это становится соревнованием, кто сможет преобразовывать слова эффективнее. В чем принципиальная разница между этим и логикой традиционного производства?
Парадокс Джевонса: повышение эффективности ≠ снижение затрат
Что еще более важно, за этой логикой скрывается классическая экономическая ловушка — парадокс Джевонса.
В XIX веке британский инженер Джевонс обнаружил, что по мере повышения эффективности парового двигателя потребление угля фактически увеличивалось, а не уменьшалось, поскольку более дешевая энергия стимулировала более широкое использование. Теперь же значительно сниженная стоимость обработки данных с помощью ИИ, как ни парадоксально, стимулирует еще большее использование, что приводит к непрерывному росту общего потребления и расходов.
Поэтому, когда поставщики моделей радуются "резкому увеличению объема лексических вызовов", я всегда думаю:
Это выгода от повышения эффективности, достигнутая благодаря технологическому прогрессу, или новый потребительский бум?
Новые правила игры в производственной цепочке
Китай ориентируется на экономическую эффективность, а Америка — на премиальность: кто победит?
Метаэкономика создает четкую промышленную цепочку, каждое звено которой подвергается трансформации. Но еще интереснее то, что Китай и Соединенные Штаты идут совершенно разными путями.
С точки зрения производства: у кого дешевле электроэнергия?
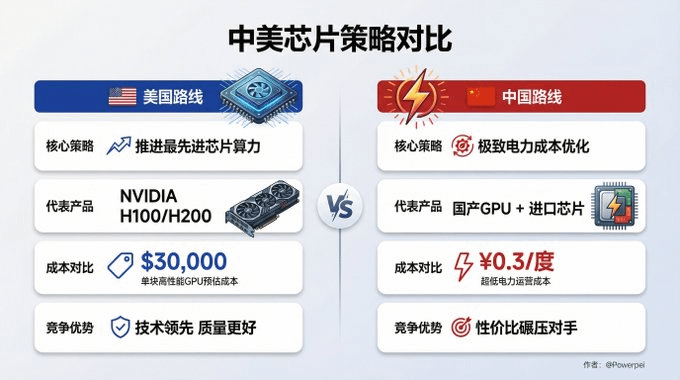
В результате, хотя американская модель может быть более качественной, китайская модель по «экономической эффективности» значительно превосходит своих конкурентов.
Ситуация похожа на индустрию мобильных телефонов: Apple продает продукцию премиум-класса, но Xiaomi и OPPO захватили большую часть мирового рынка, предлагая высокопроизводительные устройства по конкурентоспособным ценам.
Оптимизация: Сколько денег можно сэкономить с помощью этого программного обеспечения?
На мой взгляд, этот слой недооценен больше всего. Без добавления нового оборудования, одной лишь оптимизации программного обеспечения можно увеличить генерацию слов в 3-5 раз.
Пример из практики: Технология маршрутизации на основе моделей.

Например, алгоритмы ускорения вывода (квантование, обрезка, дистилляция) могут увеличить скорость вывода той же модели в 2-3 раза, что эквивалентно производству большего количества токенов при том же количестве электроэнергии.
Именно поэтому будущая конкуренция в сфере ИИ может заключаться не в самих моделях, а в «системах планирования» и «возможностях оптимизации затрат».
Завершение распространения: В чем суть глобального распространения словесных токенов?
Китайские модели, используя свое ценовое преимущество, позволяют осуществлять «лексический экспорт» через API. Это звучит как научная фантастика, но по сути это правда:
➢ Американские компании, использующие китайские API, платят в три раза меньше за миллион слов по сравнению с OpenAI.
➢ Разработчики из Юго-Восточной Азии, Латинской Америки и Африки могут напрямую создавать локальные приложения, используя китайскую модель.
➢ Не требуется таможенное оформление, логистика и даже физическое присутствие.
Это новый вид «цифрового экспорта»: мы продаем не товары, а сам интеллект.
Но возникает вопрос: будут ли США ограничивать распространение слов так же, как ограничивают распространение чипсов? Будет ли введено «словесное эмбарго»? Этот вопрос заслуживает дальнейшего внимания.
Что касается приложений: кто потребляет больше всего токенов?
Три сценария с наибольшим потреблением лексики:
① Интеллектуальный агент службы поддержки клиентов
Специалист по обслуживанию клиентов, использующий искусственный интеллект, обрабатывает 1000 разговоров в день, используя в среднем 5000 ключевых слов на каждый разговор, что в сумме составляет 5 миллионов ключевых слов в день. Средняя по размеру компания электронной коммерции может использовать более 100 миллионов ключевых слов в месяц.
② Генерация кода
Программист, использующий Copilot, может обрабатывать от 100 000 до 200 000 слов в день. Технологическая компания со 100 сотрудниками может обрабатывать до 500 миллионов слов в месяц.
③ Создание контента
Одно из самодостаточных медиа-изданий использует искусственный интеллект для генерации статей, сценариев видеороликов и описаний изображений, обрабатывая от 200 000 до 300 000 слов в день.
В будущем в финансовом отчете каждой SaaS-компании может появиться «символическая стоимость», подобно тому, как сегодня учитываются затраты на облачные сервисы.
«Лексическая черная дыра» разумных агентов
Особого внимания заслуживают интеллектуальные агенты. Я знаю команду стартапа, которая создала административного помощника на основе ИИ, чтобы помочь компаниям справляться с повседневными задачами. Звучало здорово, но в первый месяц после запуска они были ошеломлены:
Анализ затрат по реальному случаю
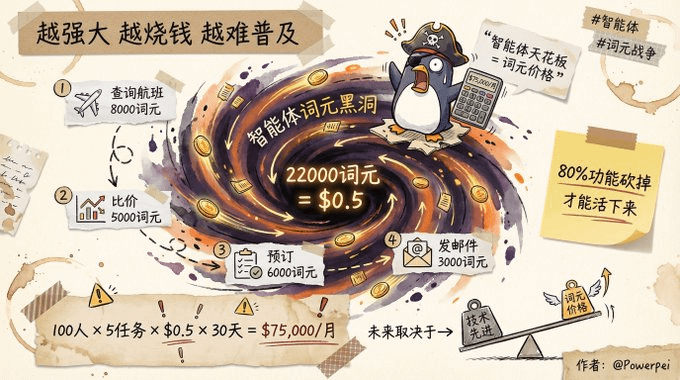
Задание: Забронируйте для своего начальника авиабилеты, отель, такси и конференц-зал на следующую неделю для поездки в Шанхай.
Шаг 1: Проверьте информацию о рейсе.
→ Модель была вызвана 3 раза, израсходовав 8000 токенов.
Шаг 2: Сравните цены и время.
→ Модель была вызвана дважды, израсходовав 5000 токенов.
Шаг 3: Забронируйте и подтвердите.
→ Модель была вызвана дважды, израсходовав 6000 токенов.
Шаг 4: Составьте маршрут и отправьте его по электронной почте.
→ Модель была вызвана один раз, потребив 3000 токенов.
Итого: 22 000 слов, стоимость приблизительно 0,50 доллара.
Если в компании 100 сотрудников, и у каждого сотрудника по 5 таких задач в день:
В итоге команде пришлось сократить 80% функций, оставив только самые необходимые сценарии, чтобы удержать затраты в приемлемом диапазоне.
Основатель сказал мне кое-что:
«Речь идёт не о создании продукта, а о том, чтобы зарабатывать на жизнь. Потолок возможностей интеллектуальных агентов — это не технологии, а цена лексических единиц».
В этом и заключается парадокс интеллектуальных агентов: чем мощнее они, тем дороже становятся; чем дороже они становятся, тем сложнее их популяризировать. Следовательно, будущее интеллектуальных агентов может зависеть не от уровня развития технологий, а от того, насколько можно снизить стоимость лексических единиц.
В некотором смысле, ценовая война в мире только начинается.
Таким образом, правила игры изменились.
Для бизнеса: ➢ Расчет рентабельности инвестиций стал более точным.
В прошлом было сложно количественно оценить выгоды и затраты при анализе проектов в области искусственного интеллекта.
Теперь вы можете четко рассчитать: сколько единиц необходимо для замены сотрудника службы поддержки клиентов, сколько единиц необходимо для обработки контракта и сколько единиц необходимо для составления отчета.
Структура затрат меняется: часть человеческого труда заменяется автоматизацией, а неосновной труд быстро механизируется. В финансовых отчетах объем работы с текстовыми редакторами может стать новым ключевым показателем.
Для отрасли искусственный интеллект действительно перешел из стадии "демонстрации" на стадию "инфраструктуры".
Интеллект перестал быть таинственной способностью, скрытой в «черном ящике», и превратился в повседневный ресурс, который можно измерить, использовать в торговле и оптимизировать, подобно электричеству, воде и циркуляционным потокам.
С макроэкономической точки зрения, ➢ Лексические единицы, как новый тип факторов производства, преобразуют производственную функцию.
Она объединяет энергетику, вычислительные мощности, данные и приложения, порождая новую систему ценностей.
Преимущества Китая в области экологически чистой электроэнергии, стоимости вычислительных мощностей и сценариев применения позволили глобальным устройствам выйти на мировой рынок.
По сути, это подразумевает экспорт электроэнергии и вычислительной мощности в виде цифрового интеллекта.
Но я всегда чувствовал, что что-то не так.
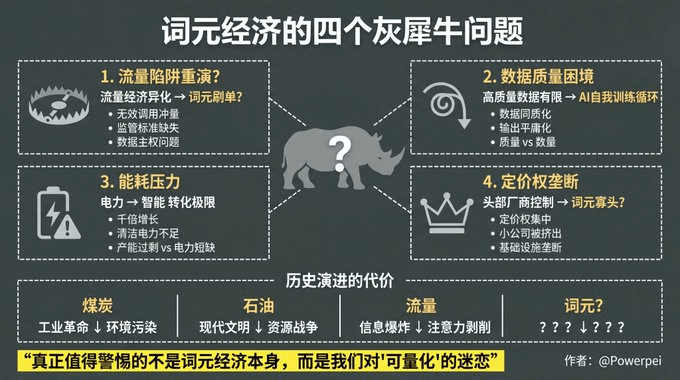
Четыре неудобных вопроса
«Серый носорог» метаэкономики
Во-первых, не станет ли метаэкономика новой «ловушкой для транспорта»?
В эпоху интернета мы стали свидетелями подъема и искажения экономики транспортного потока.
Изначально трафик представлял собой количественную оценку внимания пользователей; позже он превратился в игру чисел, которой можно манипулировать, покупать и подделывать.
Пойдут ли лексические единицы по тому же пути? Когда лексические единицы станут ключевыми показателями, будут ли некоторые люди создавать некорректные запросы для повышения этих показателей? Возникнет ли цепочка «манипулирования лексическими единицами» в отрасли? Смогут ли поддерживающие меры, такие как регулирование, международные стандарты и суверенитет данных, соответствовать этим изменениям?
Во-вторых, сможет ли обеспечиться достаточный объем высококачественных данных?
Ценность лексической единицы зависит не только от её количества, но и, что, возможно, более важно, от её качества. Однако высококачественных данных немного.
Когда все будут лихорадочно создавать лексические единицы, разве источники данных не станут все более однородными? Не попадет ли ИИ в замкнутый круг «самообучения»?
Использование контента, сгенерированного ИИ, для обучения ИИ приводит к всё более посредственным результатам?
В-третьих, как решить проблему чрезмерного энергопотребления?
Суть метаэкономики заключается в преобразовании электроэнергии в интеллект. Но электроэнергия не бесконечна, особенно чистая электроэнергия.
Когда потребление электроэнергии увеличится в тысячу раз, сможет ли энергоснабжение справиться с этим? Возникнет ли противоречие между избытком электроэнергии и её дефицитом?
В-четвертых, кто обладает правом устанавливать цены?
В настоящее время ценообразование на мировые единицы продукции в основном определяется несколькими ведущими поставщиками. Но по мере того, как мировые единицы продукции становятся частью инфраструктуры, приведет ли концентрация ценовой власти к появлению новой монополии?
Возникнет ли «лексическая олигополия»? Будут ли мелкие компании и индивидуальные разработчики вытеснены с рынка?
Эти вопросы пока остаются без ответа. Но я думаю, что прежде чем праздновать «Первый год метаэкономики», нам следует хотя бы вынести эти вопросы на обсуждение.
В заключение
От угля и нефти в индустриальную эпоху до транспорта и данных в информационную эпоху, и теперь до слов в эпоху интеллекта, человеческая экономика всегда развивалась вокруг «основной энергии и единиц измерения». Эта логика верна.
Но каждая эволюция сопровождается новым неравенством, новыми потерями и новым отчуждением:
Уголь положил начало промышленной революции, но также привел к загрязнению окружающей среды.
Нефть принесла современную цивилизацию, но также и войны за ресурсы.
Интенсивный трафик привел к информационному взрыву, но также породил злоупотребление вниманием.
Что принесут лексические элементы? Пока рано делать выводы.
У меня есть смутное ощущение, что когда «мышление» и «творчество» рассматриваются как товары, подлежащие торговле,
Когда каждый результат работы ИИ точно оценивается, мы можем упустить нечто более важное.
Такое стремление к исследованиям, не зависящее от затрат, такое вдохновение, которое невозможно измерить, такая ценность, которая превосходит эффективность.
Возможно, нам следует опасаться не самого слова «экономика», а нашей одержимости поддающимися количественной оценке вещами.
Не всё, что имеет ценность, можно измерить, и не всё, что можно измерить, имеет ценность.
И последний вопрос к вам:
Начала ли ваша компания планировать бюджет на потребление лексики? Когда агенты потребляют лексику как воду, задумываетесь ли вы когда-нибудь: что именно эта лексика создает для нас?