And What I Discovered Changed How I Think About Earning From AI
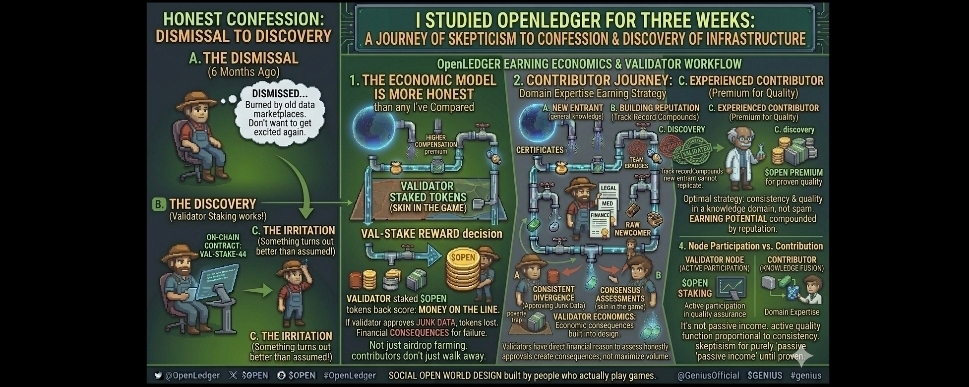
Three weeks. I spent three weeks trying to poke holes in this project before writing about it because I refused to be another crypto blogger recycling the whitepaper and calling it analysis. I looked at the contributor mechanics the token flow the validation system and the actual earning potential for someone sitting right now with a laptop and genuine knowledge about something. And I kept arriving at the same uncomfortable conclusion that the economic model here is more honest than anything I have compared it against in the AI data space.
Let me tell you what OpenLedger actually is in plain language because most coverage buries the simple version under layers of technical positioning. @OpenLedger is a network where real people contribute real knowledge to train AI systems and get paid in $OPEN tokens for the quality of what they provide. You dont need to be a developer. You dont need to run expensive hardware. You need to know something that an AI system needs to learn and you need to be able to structure that knowledge in a way that passes independent validation by other network participants who also have skin in the game.
The earning mechanics are what I spent the most time examining because this is where most projects lie to you with vague promises about passive income that require reading seventeen footnotes before the actual conditions become visible. OpenLedger rewards contributors based on three things that happen in sequence. Your submission enters the network and gets assessed by validators for quality uniqueness and relevance to active training demand. If it clears validation your reward weight gets calculated against current demand for that data category and your personal contribution reputation score. And your reputation score from previous validated submissions influences how much weight your current contribution carries in the reward calculation.
That third element is the one I find most interesting from a pure earning strategy perspective. It means the optimal behavior for a contributor is not to spam the network with volume hoping something sticks. Its to build a consistent track record of quality in a specific knowledge domain because that track record compounds your reward rate over time in a way that a new entrant with identical knowledge cannot immediately replicate. I dont see many projects with earning mechanics that actually reward sustained quality over short-term extraction and the ones that do tend to have better long-term contributor retention which is the health metric that matters most for a data network.
My honest reaction when I first understood the validation incentive structure. I was genuinely surprised. Validators who stake $OPEN to participate in quality assessment earn rewards for accurate evaluations but face economic consequences when their assessments consistently diverge from network consensus without justification. That accountability mechanism means validators have a direct financial reason to assess submissions honestly rather than approving everything to maximize their processing volume. Most decentralized quality networks I have reviewed collapse because the validation layer has no real downside for approving low quality work but @OpenLedger has built the economic consequences for bad validation directly into the staking design.
But here is what I think most potential contributors completely miss when they first look at this project. The categories of knowledge that earn the highest reward weights are not the categories where the most contributors are competing. Everybody understands that general knowledge contributions exist at scale on the internet already and that the marginal value of adding another factual summary about a well-documented topic is low. The high reward categories are specialist domains where verified human expertise is genuinely scarce and where the gap between what AI systems currently know and what they need to know to function in real professional environments is significant. If you have spent years working in a specific technical field a specific industry or a specific regional context that is underrepresented in existing AI training data you are sitting on earning potential that the current $OPEN reward structure is specifically designed to compensate.
The node participation side of the network is something I want to address directly because it represents a different kind of engagement than contribution and I dont think the two get clearly distinguished in most coverage. Running a validator node in the OpenLedger network requires staking $OPEN as a commitment mechanism and participating in the quality assessment process for incoming submissions. The reward for accurate validation is real and the staking requirement creates a natural quality filter that prevents the validator layer from being flooded with participants who have no economic commitment to making accurate assessments. Its not passive income and I want to be clear about that because anything marketed as passive income in crypto deserves skepticism until proven otherwise. Its active participation in a quality assurance function that earns rewards proportional to the accuracy and consistency of your assessments.
And the demand side of this equation is what I keep coming back to when I think about whether the contributor economics are sustainable over a full market cycle. The organizations building AI systems are not going to stop needing verified human-origin training data because a bear market arrived. The regulatory pressure for documented data provenance is increasing not decreasing. The model capability ceiling created by training data quality limitations is a technical reality that no amount of architecture innovation resolves without better data. The demand fundamentals that justify contributor compensation are structural rather than speculative and structural demand is what I look for when I try to assess whether a token-based reward system can survive conditions that kill pure speculation.
I want to be direct about what I think a regular person reading this should actually do with the information I have shared. If you have domain expertise in any field where AI deployment is currently producing unreliable results which is most professional fields you should seriously investigate what contributing to @OpenLedger actually requires in practice. Not because I am telling you $OPEN will moon and not because I am certain the execution matches the design. But because the economic model creates a genuine pathway for people with real knowledge to participate in the AI training economy on terms that are more transparent and more fairly structured than anything the conventional data labeling industry has ever offered to contributors at any scale.
The project earns my continued attention because the mechanics hold up under the kind of pressure I apply to things I actually care about getting right. Im still skeptical about the pace of enterprise adoption. Im still watching the validator quality consistency data carefully. But the core earning model is the most honest version of this concept I have reviewed and I think that honesty is worth stating plainly.
