What OpenLedger Is Building Could Not Be More Strategically Precise
I want to tell you about a conversation I had with a machine learning engineer at a mid-sized AI company who asked me not to use his name. We were talking about their next training run and somewhere in the middle of the conversation he said something that I have not been able to stop thinking about since. He said the team had recently finished a serious internal audit of what high-quality text data remained on the accessible internet that they had not already used in previous training cycles and the conclusion of that audit was more alarming than anything he had expected when the project started. The well was not dry yet but they could see the bottom and nobody in leadership wanted to say it publicly because saying it publicly meant admitting that the scaling strategy the entire industry had been executing for five years was approaching a hard constraint that more compute could not solve.
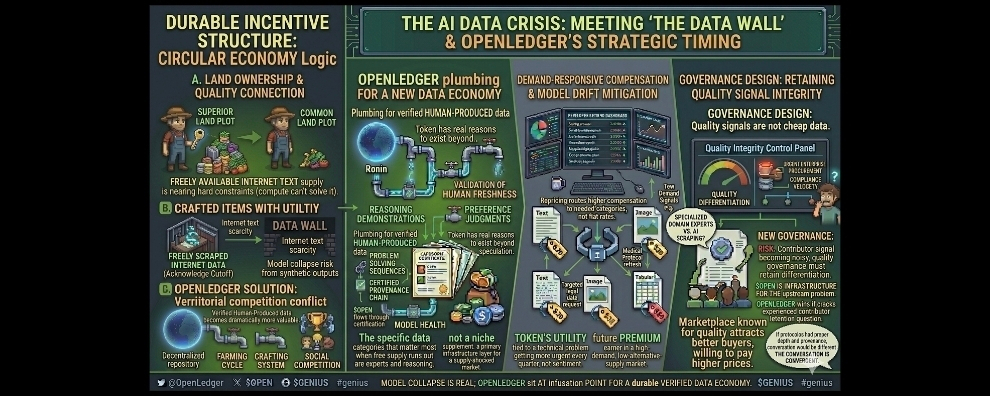
The data wall is the term researchers use for the point at which the supply of high-quality human-generated text available for AI pretraining becomes insufficient to support continued model improvement through the scaling approach that has driven capability gains since 2017. Estimates about when exactly the internet runs out of useful uncontaminated training text vary but the directional consensus among researchers who study this seriously is that the constraint is real measurable and closer than the public statements of major AI organizations suggest. The organizations with the most incentive to be honest about this timeline are also the organizations with the most competitive reason to say nothing about it publicly and that asymmetry means the data wall conversation happens mostly in private research discussions rather than in the press releases and conference presentations that shape public understanding of where AI development actually stands.
This is the context in which I think $OPEN and what @OpenLedger is building deserves to be understood by anyone paying serious attention to where value in the AI infrastructure stack is going to concentrate over the next three years. The protocol is not building a supplement to an abundant data supply. Its building primary infrastructure for a world where the abundant supply is gone and the only path to continued AI capability development runs through mechanisms that can produce verified high-quality human-generated training data on a continuous basis from sources that have never been scraped indexed or included in any previous training run. That is not a niche position in a stable market. Its a central position in a market that is about to experience a supply shock that most of the participants currently ignore.
The specific data categories that matter most when the freely available internet text supply runs out are not the ones that are easiest to collect. High quality reasoning demonstrations from genuine domain experts. Structured problem solving sequences documented by experienced practitioners working through real professional challenges. Preference judgments made by people with actual professional stakes in the quality of the outputs they are evaluating. These categories require human contributors with genuine expertise and they require verification infrastructure that can distinguish expert contributions from sophisticated imitations and the combination of those two requirements is exactly what the OpenLedger contributor and validator architecture was designed to provide.
My honest feeling about the data wall situation is somewhere between vindication and frustration. Vindication because the structural argument for decentralized verified data networks looks more compelling every time another research paper quietly acknowledges that data quantity cannot substitute indefinitely for data quality. Frustration because the mainstream conversation about AI development continues to focus almost entirely on model architecture and compute scaling while treating data infrastructure as an unsexy supporting function rather than the primary constraint that it has already become for organizations trying to push capability frontiers. The engineers know the truth. The research papers contain the truth in careful academic language. And the public conversation continues to discuss AI progress as if the data supply question has been resolved.
But I want to get specific about what the data wall means for the contributor opportunity inside @OpenLedger because I think it changes the earning calculus in a way that most people analyzing the token economics have not fully incorporated. When the supply of freely available training data becomes genuinely scarce the price that AI developers will pay for verified high-quality contributions from human experts does not stay flat. It increases in proportion to how difficult that data is to obtain through alternative means and how critical the specific knowledge domain is for the AI capabilities the developer is trying to build. A contributor who has established a strong verified reputation in a high-demand knowledge domain inside the OpenLedger network before the data wall constraint becomes acute is not just a current earner. They are a future premium earner in a market where their specific position will be harder to replicate as demand increases and alternative supply shrinks.
The multimodal data dimension is where I think the data wall argument gets even more serious and where @OpenLedger has territory to develop that most coverage completely ignores. The next phase of AI capability development is not just about text. Its about verified human expert knowledge expressed across multiple modalities including technical diagrams documented processes annotated images and structured audio that captures professional expertise in forms that pure text cannot convey. A civil engineer explaining a structural failure analysis is providing more useful training signal when they annotate a diagram with their reasoning than when they write a text description of the same analysis and the multimodal contribution infrastructure that OpenLedger is developing creates a pathway for capturing those richer forms of expert knowledge that the text-only scraping model was never equipped to access.
I called my contact back after I started writing this piece and asked him one follow-up question. I asked whether his company had looked at decentralized data protocols as part of their response to the constraint they had identified. He said they had looked briefly and then moved on because the contributor bases were too small and the data quality documentation was insufficient for their internal compliance requirements at the time they reviewed the options. Then he said something that I think is the most important thing anyone working on $OPEN should hear directly. He said if any of those protocols had mature verified contributor depth and proper provenance documentation in the domains they actually needed the conversation would be very different today. That conditional is the entire market thesis for what @OpenLedger needs to execute against and the window for building that verified depth before enterprise buyers start making urgent procurement decisions is not indefinitely open.
The race is not between OpenLedger and other decentralized data protocols. The race is between the current development pace of the contributor and validator network and the timeline on which major AI developers will stop being able to avoid the data quality and sourcing problem that the protocol is built to solve. I dont know precisely when those two lines cross. I know the direction of travel on both and the direction is convergent.
Thats not hype. Thats just the honest read of where the constraints are moving.
