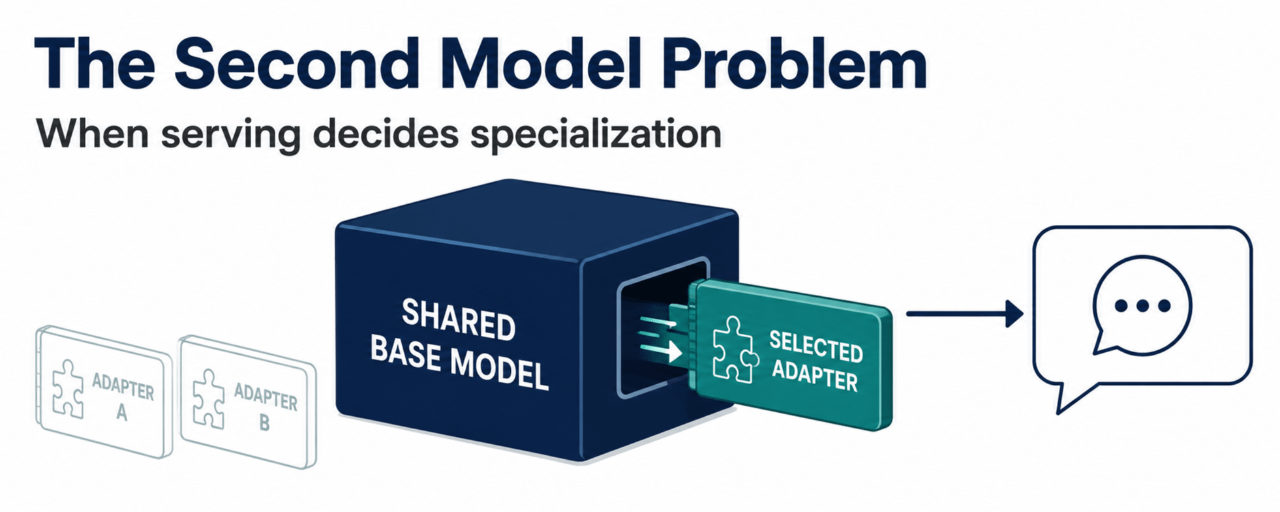

Dễ dàng để ngưỡng mộ mô hình chuyên dụng đầu tiên. Nó trả lời trong miền chính xác, cảm giác sắc nét hơn so với mô hình chung và cung cấp cho người sáng tạo điều gì đó thuyết phục để trưng bày. Cơn đau bắt đầu khi bạn cần một mô hình chuyên ngành thứ hai, rồi đến thứ mười. Nếu mỗi biến thể tinh chỉnh đều yêu cầu một stack phục vụ hoàn toàn riêng biệt, sự chuyên môn hóa không còn là lợi thế sản phẩm mà trở thành hóa đơn cơ sở hạ tầng.
Đó là lý do tại sao tôi quan tâm hơn đến bề mặt OpenLoRA của OpenLedger hơn là một tuyên bố rộng rãi về AI thông minh hơn. Nó liên quan đến khoảng thời gian tồi tệ khi một mô hình đã được làm cho có thể sử dụng. OpenLoRA được thiết kế để chứa các bộ điều hợp LoRA tinh chỉnh ngồi trên một mô hình cơ sở chung, thay vì triển khai mỗi mô hình chuyên ngành như một đơn vị nặng nề riêng biệt. Trong một quyết định sản phẩm thực tế, sự phân biệt là đáng kể. Một nhà xây dựng có thể duy trì khả năng chính xác đang mở rộng hoặc bắt đầu giảm quy mô khi việc phục vụ trở nên quá khó khăn để mang theo.
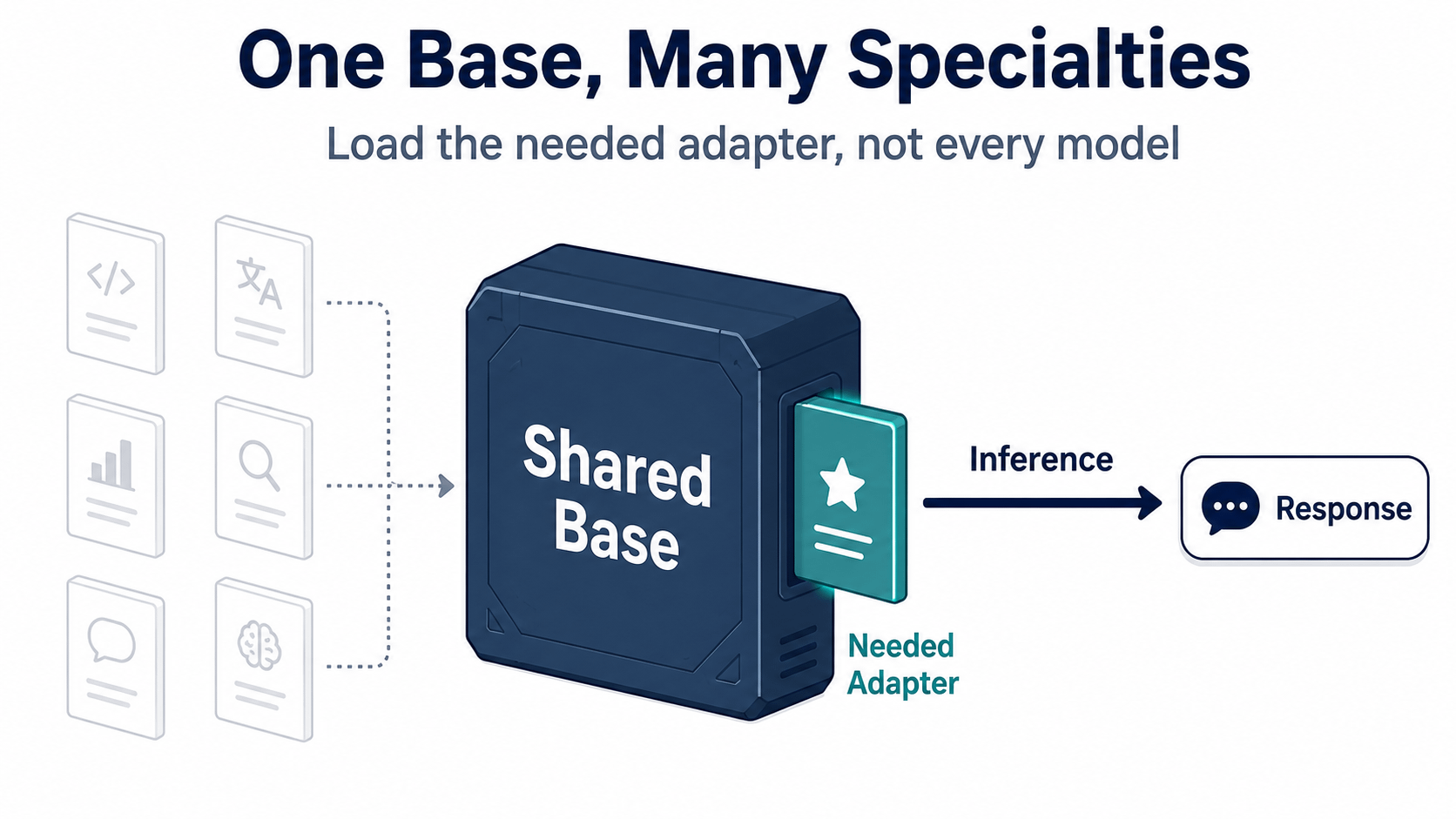
Điều chính là không đào tạo một chuyên môn mới. Nó là gọi đúng cái khi một người dùng thực sự yêu cầu nó.
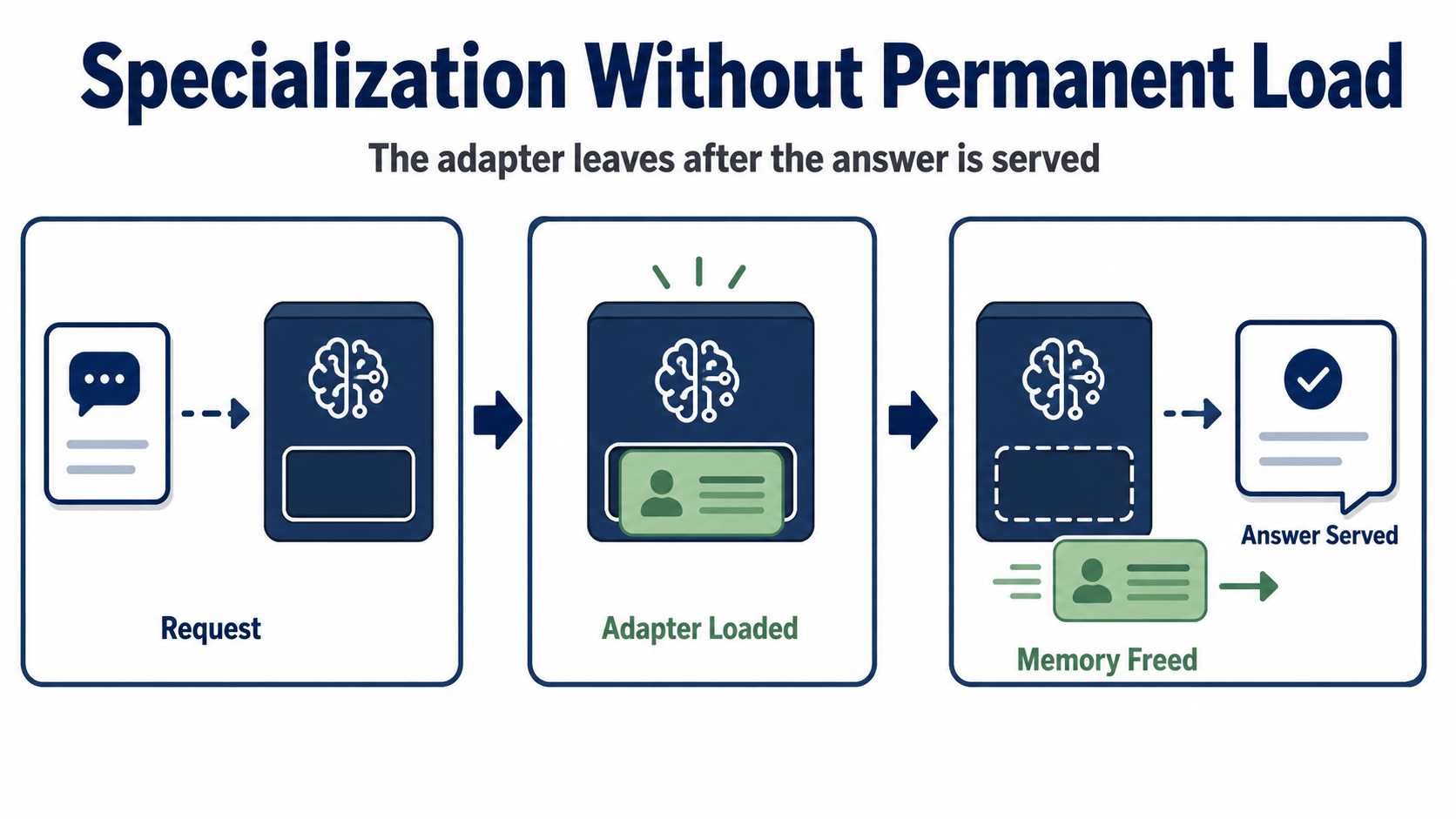
OpenLoRA tải động các adaptor cần thiết, kết hợp chúng vào mô hình cơ bản để suy diễn, và sau đó giải phóng nó sau khi nhận phản hồi để giải phóng RAM GPU. Constructor không cần phải lưu trữ mọi biến thể chuyên gia trong bộ nhớ, chờ đến lượt của nó. OpenLedger mô tả điều này là phục vụ hàng ngàn mô hình đã được tinh chỉnh trên một GPU. Tôi coi đó là một tuyên bố sản phẩm mạnh mẽ. Nó nói rằng tính hữu dụng hẹp nên có thể nhân lên mà không cần một máy riêng ngồi sau mỗi mô hình hẹp.
Đây là nơi chuyên môn hoặc vẫn nằm ngoài buổi trình diễn hoặc được cắt gọn một cách nhẹ nhàng. Một trợ lý có thể dường như dễ dàng với người dùng của nó và yêu cầu nhiều adaptor hẹp đứng sau nó. Bạn cần một chuyên gia cho một yêu cầu, một chuyên gia khác cho cái tiếp theo. Nếu lớp triển khai chỉ có thể làm điều đó bằng cách nhân bản cơ sở hạ tầng, thì nhà xây dựng bị dẫn đến ít lựa chọn hơn và phản hồi thô hơn. Sự cung cấp đang trở nên ít cụ thể hơn trong khi người dùng quay lại yêu cầu nhiều nhiệm vụ cụ thể hơn.
OpenLoRA cược một cách cụ thể hơn. Làm cho mô hình cơ bản trở nên phổ biến. Nhận adaptor cần thiết cho yêu cầu. Kết hợp tại thời điểm suy diễn. Giải phóng bộ nhớ sau phản hồi. Đó không phải là một lời hứa mơ hồ về AI trở nên cá nhân hóa hơn. Đó là một quyết định phục vụ cố gắng tránh mỗi chuyên môn mới trở thành một gánh nặng phần cứng vĩnh viễn mới.
Đây cũng là lý do tại sao OpenLoRA là một góc nhìn OpenLedger sạch hơn so với việc chỉ khen ngợi tinh chỉnh. ModelFactory khám phá bề mặt tinh chỉnh. OpenLoRA theo dõi khoảnh khắc mà một mô hình đã được đào tạo trở nên có thể sử dụng lặp đi lặp lại, hoặc trở thành một tài sản khác quá cồng kềnh để phục vụ rộng rãi. Một nhà xây dựng không thắng chỉ vì có một mô hình. Chiến thắng chỉ xảy ra khi một số mô hình chuyên môn có thể tiếp tục trả lời mà không cần mỗi mô hình yêu cầu một triển khai khác để duy trì.
Có một bài kiểm tra mà tôi sẽ không làm mềm hóa. Kiến trúc sạch: tải động. Nhưng nhu cầu thực sự không phải lúc nào cũng dễ thương. Các yêu cầu không được phân bổ đều. Một số adaptor sẽ được gọi thường xuyên, một số ít, và người dùng đánh giá sản phẩm dựa trên tốc độ phản ứng và chất lượng đầu ra, không phải là một sơ đồ phục vụ đẹp mắt. OpenLoRA chỉ quan trọng nếu nó thực hiện áp lực chuyển đổi khi bạn thực sự yêu cầu nhiều con đường chuyên môn, không chỉ lưu trữ và có sẵn.
Một mô hình chuyên môn không thể phục vụ một cách kinh tế thì chưa phải là một sản phẩm. Đó là một thí nghiệm thành công, nhưng ai đó phải tiếp tục trả giá cho sự khó chịu.
Nếu OpenLoRA có thể vượt qua bài kiểm tra nhu cầu chuyển đổi thực tế, thì một nhà xây dựng OpenLedger sẽ không phải chọn giữa việc cụ thể và có thể triển khai. Nếu không, mỗi chuyên môn mới là một lý do khác để không thêm vào trí thông minh mà người tiêu dùng đã đến tìm kiếm.
#OpenLedger @OpenLedger $OPEN $NEAR $SOL
