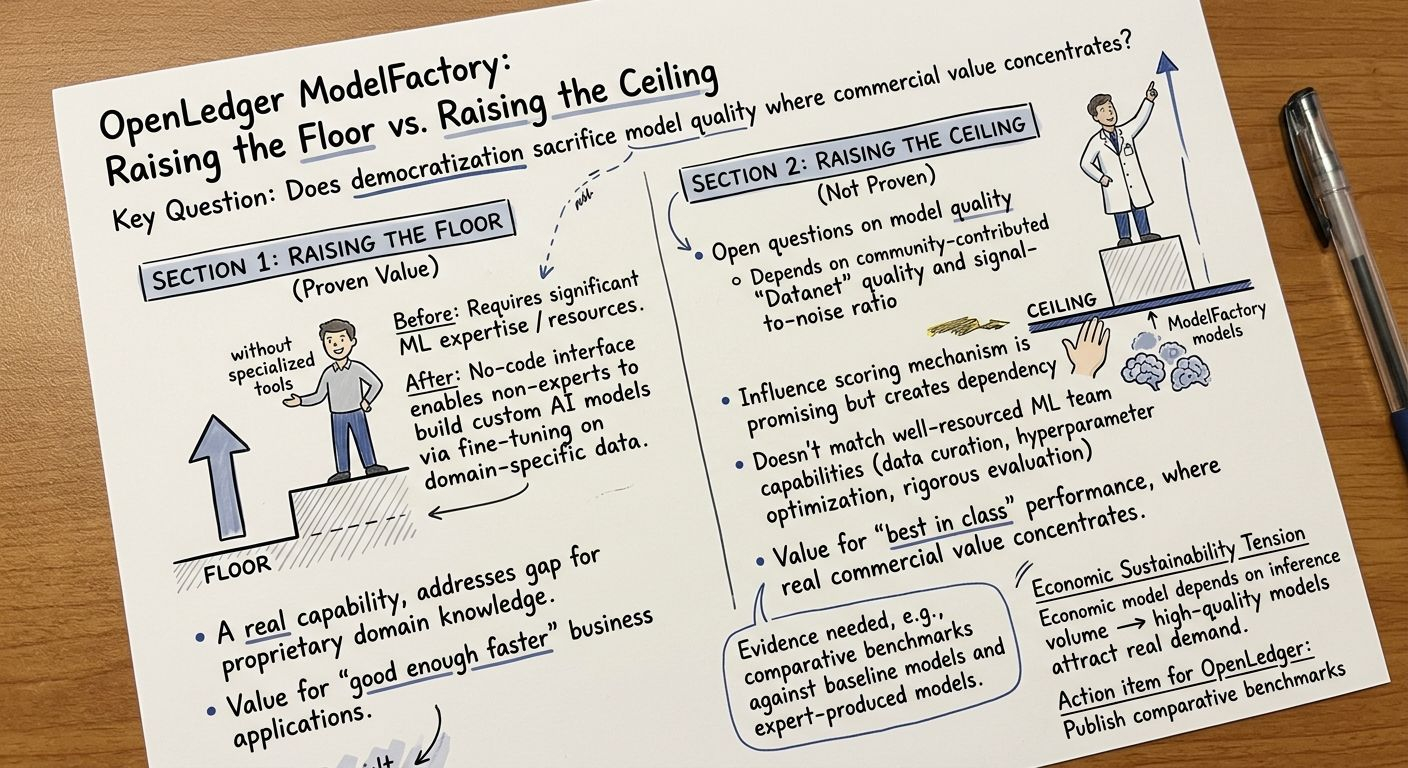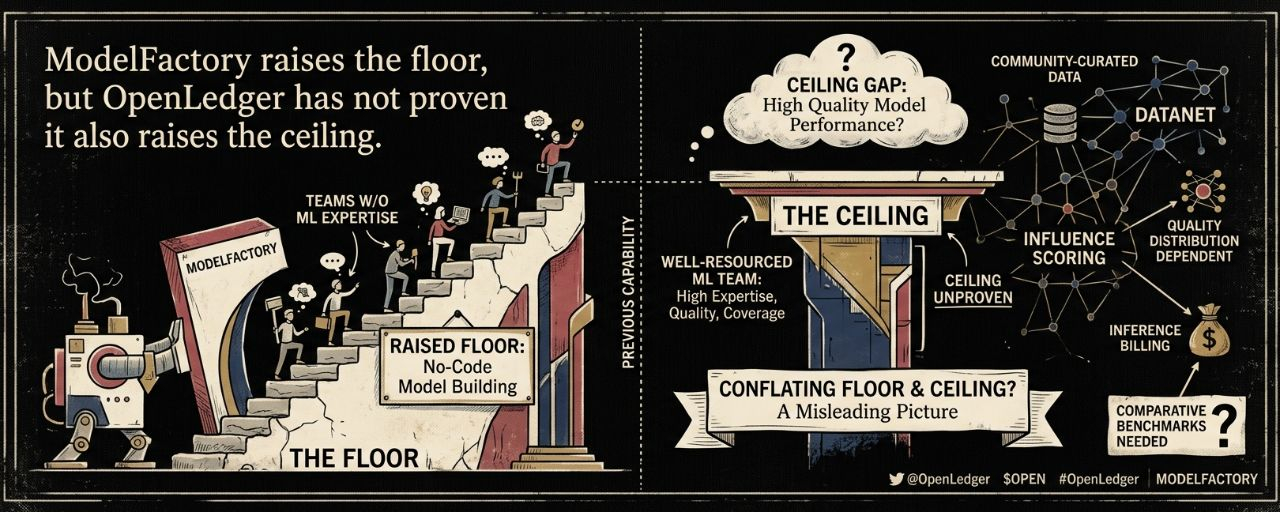
Có một loại đổi mới cụ thể thường được mô tả là sự dân chủ hóa, nhưng thực sự lại là điều gì đó giới hạn hơn và trung thực hơn: nâng sàn. Nâng sàn là giá trị thực. Việc tạo ra một khả năng mà trước đây yêu cầu chuyên môn đáng kể trở nên dễ tiếp cận với những người không có chuyên môn là một bước tiến có ý nghĩa, và tôi không muốn bác bỏ điều đó. Nhưng nâng sàn và nâng trần là hai điều khác nhau, và việc gộp chúng lại với nhau tạo ra một bức tranh sai lệch về những gì một công cụ có thể làm cho những người sử dụng nó. ModelFactory của OpenLedger, theo thiết kế và mô tả trung thực, là một công cụ nâng sàn. Một đội ngũ trước đây không có khả năng xây dựng một mô hình AI tùy chỉnh giờ đây có thể xây dựng một mô hình bằng cách sử dụng giao diện không mã của ModelFactory. Đó là nâng sàn. Điều mà tôi không thể tìm thấy bằng chứng trong tài liệu công khai hiện tại của OpenLedger là ModelFactory cũng nâng trần, có nghĩa là các mô hình mà nó sản xuất tiếp cận hoặc vượt qua chất lượng của những gì một đội ngũ ML có nguồn lực tốt có thể sản xuất mà không cần nó. Và trong không gian chất lượng mô hình AI, trần luôn là nơi mà giá trị thương mại thực sự tập trung.
Hãy xem xét những gì nền tảng thực tế trông như thế nào trước khi ModelFactory xuất hiện. Một đội ngũ không có chuyên môn về ML, không có tài nguyên kỹ thuật, và không có chức năng khoa học dữ liệu hiện có thể sử dụng các mô hình đã được huấn luyện trước thông qua các cuộc gọi API, tùy chỉnh hành vi của chúng thông qua kỹ thuật prompt, và xây dựng các ứng dụng đơn giản dựa trên các mô hình hiện có mà không cần tinh chỉnh gì cả. Đây là một khả năng thực sự. Nhiều ứng dụng hữu ích được xây dựng theo cách này. Những gì họ không thể làm dễ dàng là kết hợp kiến thức miền độc quyền mà không được ghi lại trong mô hình cơ sở, đảm bảo rằng hành vi của mô hình phù hợp với các yêu cầu tổ chức cụ thể của họ, hoặc xây dựng một mô hình với các khả năng chuyên biệt trong một miền hẹp mà mô hình cơ sở xử lý kém. ModelFactory giải quyết khoảng cách này: nó cho phép các đội tinh chỉnh một mô hình cơ sở trên dữ liệu cụ thể của họ để sản xuất một mô hình với hiệu suất miền cải thiện. Đây là một cải thiện thực sự so với nền tảng trước ModelFactory. Câu hỏi là mức độ cải thiện lớn đến đâu và cho những loại nhiệm vụ nào.
Câu hỏi về trần là nơi mọi thứ trở nên phức tạp. Các mô hình được tinh chỉnh xây dựng thông qua các giao diện no-code đơn giản trên dữ liệu Datanet được cộng đồng chọn lọc có những lợi thế chất lượng cụ thể và những hạn chế chất lượng cụ thể. Những lợi thế: dữ liệu được ghi nhận, được đánh giá chất lượng bởi cơ chế xác thực của OpenLedger, và được tổ chức theo miền. Đây là dữ liệu huấn luyện tốt hơn so với việc thu thập ngẫu nhiên dữ liệu trên internet. Những hạn chế: dữ liệu được cộng đồng đóng góp, có nghĩa là độ bao phủ của bất kỳ miền nào phụ thuộc vào ai đã đến đóng góp, những gì họ biết, và chất lượng của các đóng góp của họ. Một Datanet hình ảnh y tế được xây dựng bởi các nhà radiologist thực sự chuyên gia đóng góp dữ liệu được ghi chú cẩn thận sẽ sản xuất một mô hình được tinh chỉnh với giá trị lâm sàng thực. Một Datanet hình ảnh y tế chủ yếu được xây dựng bởi những người không phải lâm sàng nhiệt tình hoàn thành các nhiệm vụ thưởng sẽ sản xuất một mô hình trông ấn tượng trong các bài kiểm tra độ chính tổng quát và thất bại một cách tinh tế trong các trường hợp biên quan trọng về lâm sàng.
Cơ chế điểm ảnh hưởng của OpenLedger được cho là giải quyết điều này bằng cách trọng số các đóng góp theo tác động đo được của chúng đối với hành vi của mô hình, có nghĩa là các đóng góp chất lượng cao nên chiếm ưu thế trong tín hiệu huấn luyện ngay cả khi có các đóng góp chất lượng thấp tồn tại. Đây là một lựa chọn thiết kế suy nghĩ. Nhưng nó tạo ra một sự phụ thuộc vào phân phối chất lượng của các đóng góp mà OpenLedger không thể kiểm soát hoàn toàn: cơ chế hoạt động tối ưu khi có đủ các đóng góp chất lượng cao để thiết lập một tín hiệu rõ ràng. Trong các Datanet sớm, trong các miền mới, hoặc trong các miền mà các chuyên gia thực sự chưa tìm thấy hoặc tham gia với OpenLedger, nền tảng chất lượng của dữ liệu huấn luyện có thể thấp hơn những gì tài liệu ngụ ý. Và một tinh chỉnh ModelFactory được xây dựng trên dữ liệu đó sẽ phản ánh nền tảng chất lượng đó trực tiếp trong hiệu suất của mô hình kết quả.
Khoảng cách trần rõ ràng nhất khi so sánh với những gì một đội ngũ ML có tài nguyên tốt có thể làm bên ngoài bối cảnh ModelFactory. Một đội ngũ có chuyên môn về ML, dữ liệu độc quyền và quyền truy cập vào tài nguyên tính toán có thể chọn lọc dữ liệu huấn luyện của họ với sự chú ý chính xác đến chất lượng và độ bao phủ, tinh chỉnh với việc tối ưu hóa siêu tham số cẩn thận, đánh giá nghiêm ngặt theo các tiêu chuẩn liên quan đến sản xuất, và lặp đi lặp lại qua nhiều chu kỳ huấn luyện dựa trên các chế độ thất bại quan sát được. Quy trình này tạo ra một trần mà ModelFactory, ở dạng hiện tại, không được thiết kế để đạt được. ModelFactory sản xuất đủ tốt nhanh hơn, không phải là tốt nhất trong lớp. Đối với nhiều ứng dụng kinh doanh, đủ tốt nhanh hơn là những gì bạn thực sự cần. Đối với các ứng dụng mà hiệu suất mô hình là một yếu tố phân biệt cạnh tranh thực sự, đủ tốt nhanh hơn không đủ.
Mô hình doanh thu Payable AI tạo ra một sự căng thẳng thú vị ở đây. Hóa đơn suy luận của OpenLedger có nghĩa là các mô hình được triển khai qua nền tảng này sẽ tính phí theo từng cuộc gọi suy luận, với doanh thu được phân phối cho các đóng góp của Datanet. Để mô hình đó tạo ra doanh thu có ý nghĩa cho các đóng góp viên, mô hình được triển khai phải được sử dụng đủ để tạo ra khối lượng suy luận đáng kể. Các mô hình được sử dụng ở quy mô lớn khi chúng thực sự tốt hơn các lựa chọn thay thế cho một trường hợp sử dụng cụ thể. Điều này có nghĩa là tính bền vững kinh tế của mô hình bồi thường cho các đóng góp viên của OpenLedger phụ thuộc vào việc trần phải đủ cao để sản xuất các mô hình thu hút nhu cầu thực, không chỉ đảm bảo nền tảng đủ cao để sản xuất các mô hình hoạt động. Thành công trong việc nâng nền tảng không nuôi dưỡng bánh đà. Trần cần phải đủ cao để nhu cầu suy luận là thực.
Những gì OpenLedger cần công bố để giải quyết điều này một cách đáng tin cậy không chỉ là các chứng thực từ các đội ngũ đã sử dụng ModelFactory. Đó là các tiêu chuẩn so sánh: các mô hình được tinh chỉnh bởi ModelFactory trên các Datanet cụ thể so với các mô hình cơ sở so với các mô hình do các đội ngũ ML chuyên gia sản xuất trong cùng lĩnh vực. Những tiêu chuẩn này sẽ cho tôi biết liệu ModelFactory có phải là một công cụ giúp các đội ngũ phi kỹ thuật sản xuất các mô hình thực sự có khả năng hay là một công cụ sản xuất các mô hình cảm thấy ấn tượng với những người không có chuyên môn để đánh giá chúng một cách nghiêm ngặt. Đây là những sản phẩm rất khác nhau. OpenLedger rõ ràng tin rằng họ đang xây dựng cái trước. Tôi muốn thấy bằng chứng để làm cho niềm tin đó có thể xác minh được.