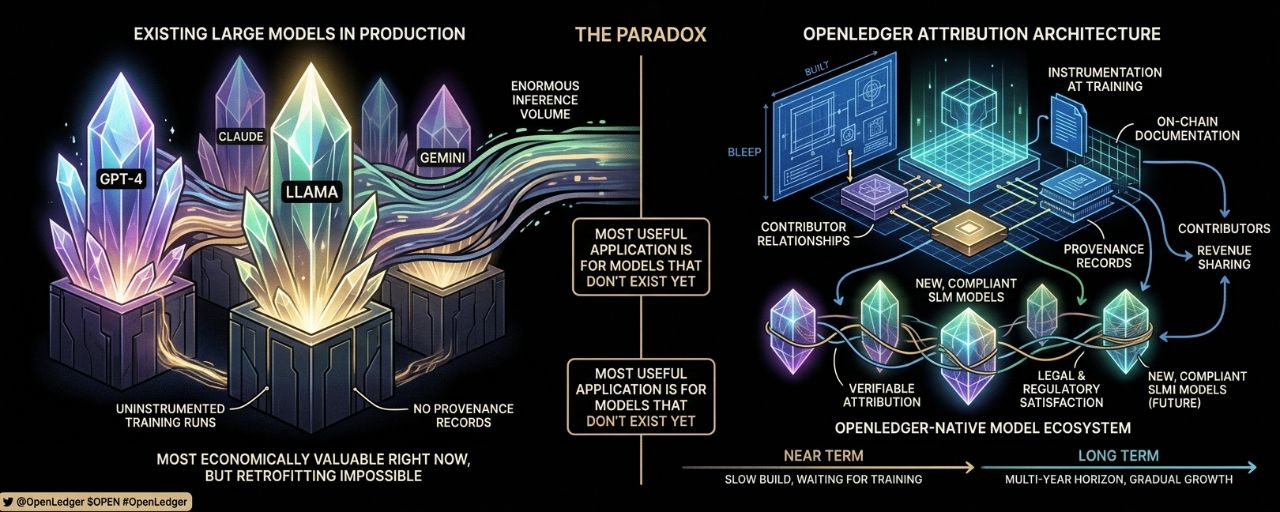
There's a fundamental paradox in OpenLedger's go-to-market position that I've been thinking through carefully, and I don't think it has a clean resolution. Understanding it clearly matters for evaluating what OpenLedger can realistically accomplish in its near term versus its long term.
The paradox is this: OpenLedger's attribution infrastructure is designed to be embedded at the moment of training. Attribution-at-training means that the provenance records, the contributor relationships, the on-chain documentation, all of it gets created during the training process. The most useful application of OpenLedger's system is to new models that haven't been trained yet, because those models can have attribution built in from the start.
But the most economically valuable AI models in the world right now are the ones already in production. GPT-4, Claude, Gemini, Llama, Mistral, and the hundreds of specialized fine-tunes built on top of them. These models are generating enormous inference volume. They're the models that businesses and developers are paying for right now. And they're almost entirely beyond OpenLedger's current attribution system, because they were trained before OpenLedger's infrastructure existed, and retrofitting attribution to pre-existing models is architecturally much harder than building it in from the start.
This is not just a market access problem. It's a credibility gap. OpenLedger can offer compelling theoretical benefits for AI models trained going forward, but demonstrating those benefits requires waiting for new models to be trained, deployed, and reach meaningful inference scale. That demonstration timeline is measured in months to years, not days or weeks.
Meanwhile, the AI models that most people interact with daily are the large foundation models where OpenLedger's attribution system has no current foothold.
Let me be specific about why retrofitting is hard.
Attribution-at-training works because the training process is instrumented to log, for each data point, its relationship to the model's evolving weights. This instrumentation needs to be integrated into the training framework at the level of the training loop itself. It's not a post-processing step. It's not something you can add to a model's inference pipeline after the fact. The records it creates reflect what happened during training, and if training happened without the instrumentation, those records simply don't exist.
You can't create retroactive Proof of Attribution records for a model like GPT-4. The training runs were not instrumented in the way OpenLedger requires. The relationship between specific training examples and the model's weights is not recoverable from the model alone. What you have is a model with capabilities that presumably reflect its training data, but without the documentation that would allow verifiable attribution.
Some approximate attribution methods, including influence functions applied post-hoc to pre-trained models, can generate estimated influence scores for training data points without full instrumentation. But these are approximations with significant additional error beyond what you'd get from properly instrumented training, and they're computationally expensive for large models. They're research tools, not production attribution infrastructure.
What this means practically is that OpenLedger's initial adoption comes from new model development rather than from the existing model ecosystem. That's a smaller and slower-growing market than the existing model ecosystem, but it's also the market where the economic case for provenance is clearest, because new model developers can make the decision to use OpenLedger before they've incurred the training cost, rather than after.
There's a version of this story where the paradox resolves itself over time. As new models trained with OpenLedger's attribution are deployed, they gradually replace older models in high-value use cases. The cardiology AI trained on an OpenLedger Datanet competes with the fine-tuned GPT-4 that the hospital system is currently using, and if it performs comparably but with superior provenance documentation, it wins the enterprise procurement decision. Over a multi-year horizon, the OpenLedger-native model ecosystem could grow to represent a meaningful fraction of AI inference, with the attribution revenue flowing to contributors and the provenance documentation satisfying legal and regulatory requirements.
That's the optimistic long-term resolution. And it might be the right one. But it requires patience that the token economics timeline may not support, and it requires the performance quality of OpenLedger-native models to be competitive with models trained on much larger datasets without provenance constraints.
The performance question is the harder one. Models trained specifically through OpenLedger Datanets start with the datasets that contributors have structured and submitted through the platform. Those datasets, in the early period, are smaller and more constrained than the massive web-crawled datasets that large models are trained on. Smaller, curated datasets can produce better performance on specific specialized tasks, which is the Specialized Language Model thesis. But "better on specific tasks" has to translate into "better enough to win the enterprise procurement decision" against incumbents with substantially more resources.
There's also a path where OpenLedger addresses the existing model ecosystem more directly, through retroactive attribution approximations, through selective fine-tuning attribution for incremental updates, or through a different positioning that focuses on the provenance records for new training runs rather than attribution for existing models. None of these fully resolve the paradox, but they might reduce its practical impact.
What I want to flag most clearly is this: the paradox is real, it's not a temporary implementation challenge, and understanding it calibrates expectations about what OpenLedger can accomplish in the near term versus what requires a longer horizon to develop. The infrastructure is excellent for what it's designed to do. What it's designed to do is most valuable for a model ecosystem that is still being built.
