
I have spent over a decade watching blockchain projects launch with grand promises, only to see most of them settle into quiet irrelevance or outright failure. The pattern is familiar: initial excitement, a wave of enthusiastic builders, some token price action, and then the slow realization that real usage is harder than the whitepaper suggested. So when I look at OpenLedger and its upcoming Phase 1, I find myself approaching it with the same cautious curiosity I've applied to dozens of others. Not dismissive, exactly, but wary. The project positions itself as an AI-focused blockchain emphasizing on-chain attribution, verifiable provenance, and incentives for data and model contributions. It's an interesting premise in a space increasingly dominated by centralized AI giants hoarding their datasets. Yet the deeper question it forces me to confront one I've seen play out repeatedly is whether the core architectural choices around visibility and verification can actually sustain long-term adoption, or if they're just another compelling narrative that crumbles under everyday friction.f2216401bc22
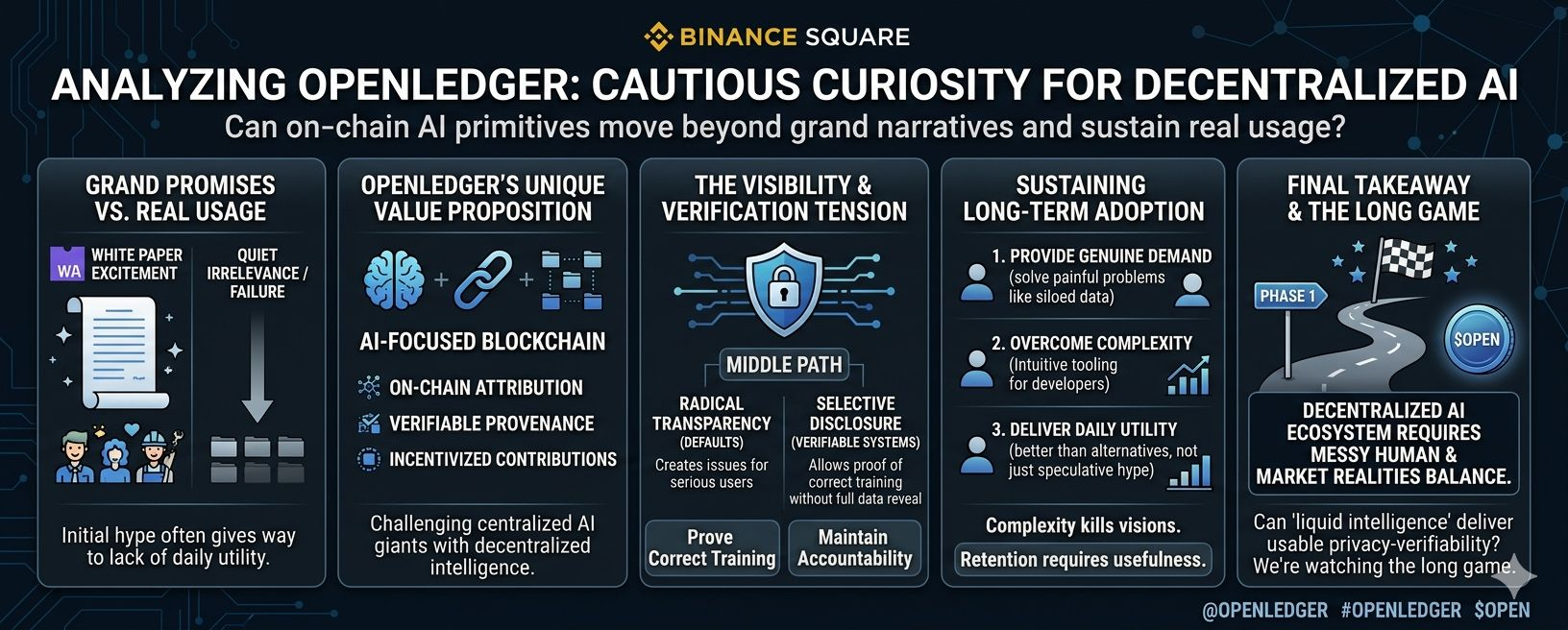
Most blockchains have defaulted to radical transparency. Every wallet address, every transaction, every smart contract interaction sits there forever, publicly auditable by anyone with an internet connection. On one level, this is powerful. It creates trust through openness no need to take anyone's word when you can verify the ledger yourself. But after years of observing DeFi exploits, wallet drainings, and regulatory scrutiny, I've come to see how this exposure creates real problems for anything approaching mainstream or serious use. Who wants their investment history, trading strategies, or data contributions permanently etched for competitors, tax authorities, or opportunistic attackers to scrutinize? For individual users, it can feel invasive. For institutions or serious developers working on valuable IP, it's often a non-starter. Privacy isn't just a nice-to-have; in many real-world contexts, it's a prerequisite for participation at scale.
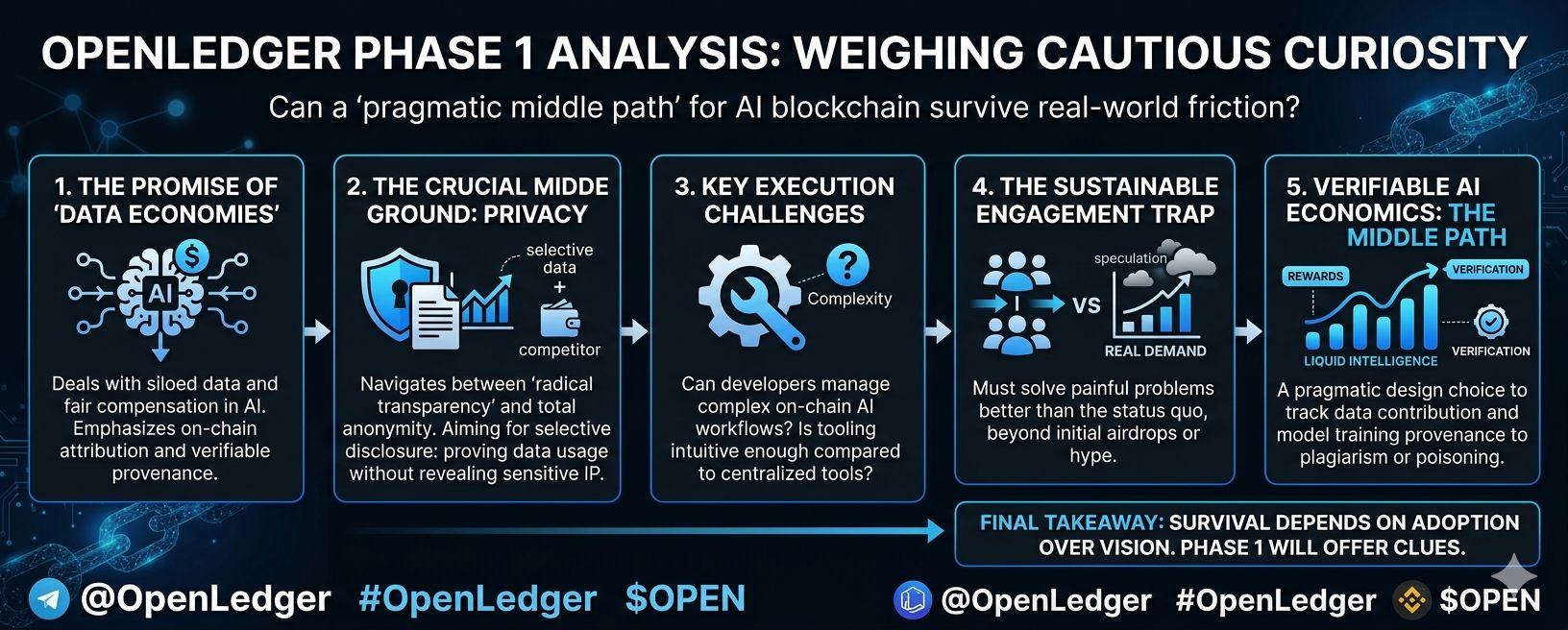
This is where projects like OpenLedger try to navigate a difficult middle path. Rather than full anonymity or total exposure, they lean into verifiable systems on-chain tracking of contributions to datasets (via what they call Datanets), model training provenance, and mechanisms to reward participants fairly while maintaining some level of accountability. It's not pure privacy in the Zcash sense, but an attempt at selective disclosure: prove that data was used or a model was trained correctly without necessarily revealing every underlying detail to the world. In theory, zero-knowledge-style techniques or similar cryptographic tools could help here, allowing verification without full revelation. It's a thoughtful design choice for an AI blockchain, where trust in training data and attribution is paramount to prevent poisoning, plagiarism, or uncompensated extraction.08fb47
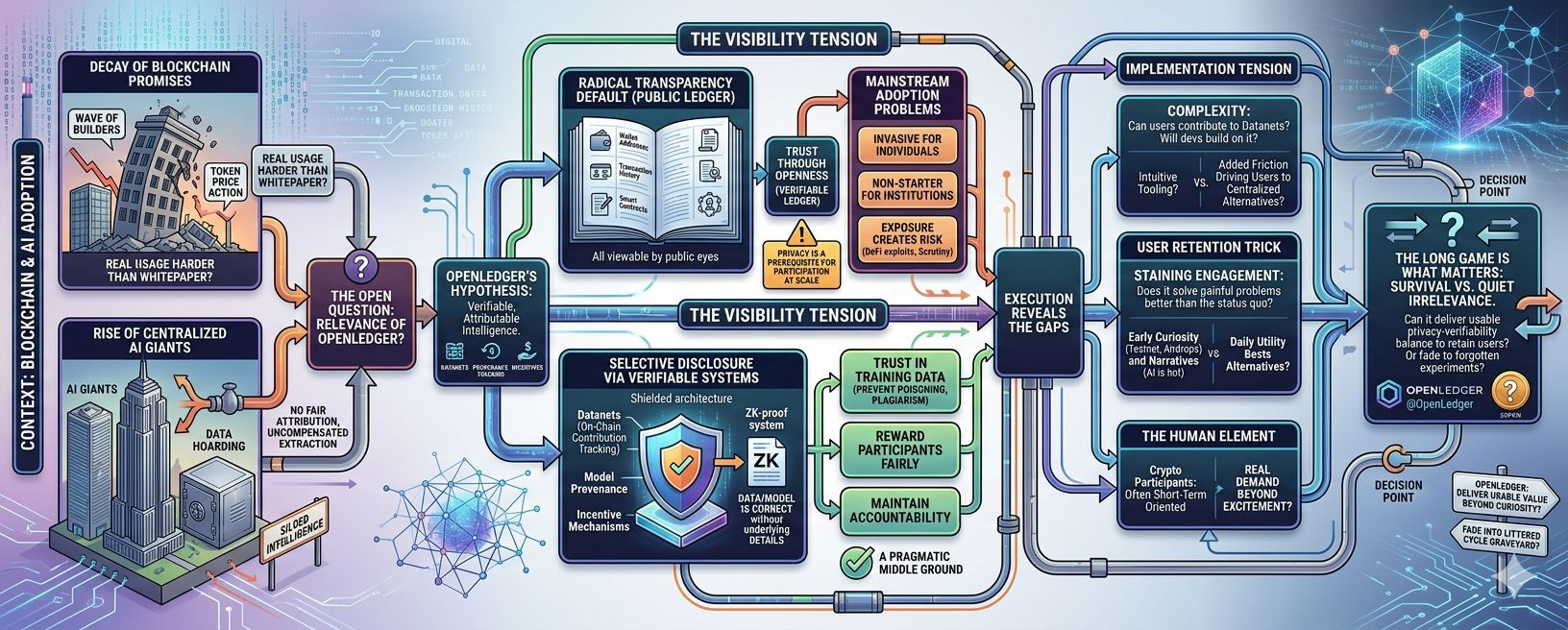
Yet I've learned to temper any quiet optimism. Paper designs often look elegant. Teams talk convincingly about balancing privacy and verifiability. But execution reveals the gaps. Will developers actually find the tooling intuitive enough to build on it, or will the added complexity of managing on-chain AI workflows data curation, model deployment, attribution proofs create enough friction to drive them back to centralized alternatives that just work faster? User retention is even trickier. Early curiosity brings testnet participants chasing potential airdrops or incentives, but sustaining engagement requires that the system solves painful problems better than the status quo. In AI, the painful problems are real: siloed data, lack of fair compensation, opaque training processes. OpenLedger's Phase 1, focused on these data intelligence layers and community contributions, seems aimed squarely at that. But history suggests many such experiments attract initial liquidity and hype only for activity to taper off once the novelty fades or better-funded centralized options iterate quicker.ba3290
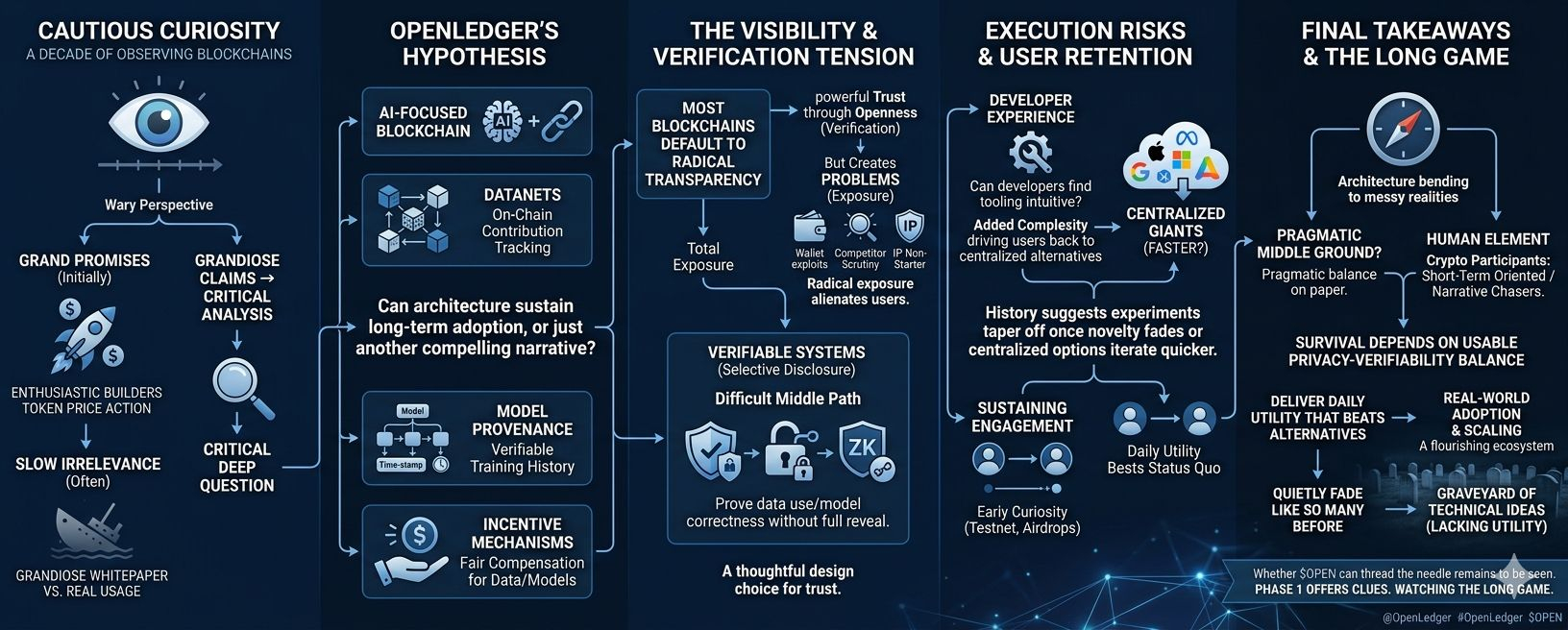
I've watched privacy-focused chains struggle with this exact tension. Radical transparency alienates users who need discretion, while heavy privacy layers can introduce performance costs, regulatory headaches, or reduced composability that limits network effects. OpenLedger doesn't seem to be going full privacy maximalist; it's leaning into transparency for the sake of verifiable AI economics rewarding data providers, tracking model provenance, making intelligence "liquid" in a decentralized way. That's a pragmatic middle ground on paper. The question is whether it translates into something people stick with. Complexity has killed more elegant blockchain visions than outright scams ever did. If contributing to a Datanet or verifying an AI agent's output feels cumbersome compared to uploading to a big tech platform, adoption may stall at enthusiasts and speculators rather than reaching the broader builders needed for a thriving ecosystem.
There's also the human element I've observed time and again. Crypto participants are often short-term oriented. They chase narratives AI is hot right now, decentralized data sounds noble but real retention comes from daily utility that beats alternatives. Will OpenLedger's system create enough genuine demand for on-chain AI primitives that it survives beyond the initial Phase 1 excitement?
Or will it join the graveyard of projects that had solid technical ideas but couldn't overcome coordination problems, developer experience hurdles, or simply insufficient real-world need for their particular flavor of decentralization?
I'm not here to hype or bury it. After so many cycles, I've grown weary of both extremes. OpenLedger @OpenLedger (OpenLedger) represents one more attempt to make blockchain relevant to the exploding AI landscape, with its $OPEN token playing a role in incentives and governance. Whether its approach to verifiable, attributable intelligence can thread the needle between necessary privacy concerns and the transparency that makes blockchain valuable remains to be seen. Phase 1 will offer some clues—data collection, early model interactions, community testing. But the long game is what matters. In a space littered with forgotten experiments, survival depends less on initial vision and more on whether the architecture bends to messy human and market realities. Can it deliver enough usable privacy-verifiability balance to retain users beyond curiosity, or will it quietly fade like so many before it? That's the open question I'll be watching. #OpenLedger

