大多數人使用人工智能時,從未想過其背後那層看不見的基礎。一個聊天機器人瞬間回答問題,一個AI工具編寫代碼,或者一個圖像生成器在幾秒鐘內創作藝術作品。這種體驗感覺順暢且幾乎毫不費力。但在每一個AI系統背後,都存在着大量人類創造的信息,這些信息是多年來從作家、開發者、研究人員、藝術家、在線社區和普通互聯網用戶那裏收集而來。奇怪的是,大多數貢獻者從來不知道他們的數據是如何被使用的,或者他們是否從中獲益。
很長一段時間,這個問題被忽視,因爲人工智能行業發展得如此迅速。公司專注於構建更大的模型,收集更多數據,提高性能。投資者關心增長,用戶關心便利性,開發者關心能力。關於所有權和歸屬的問題一直處於背景中,因爲沒有簡單的方法來解決它們。
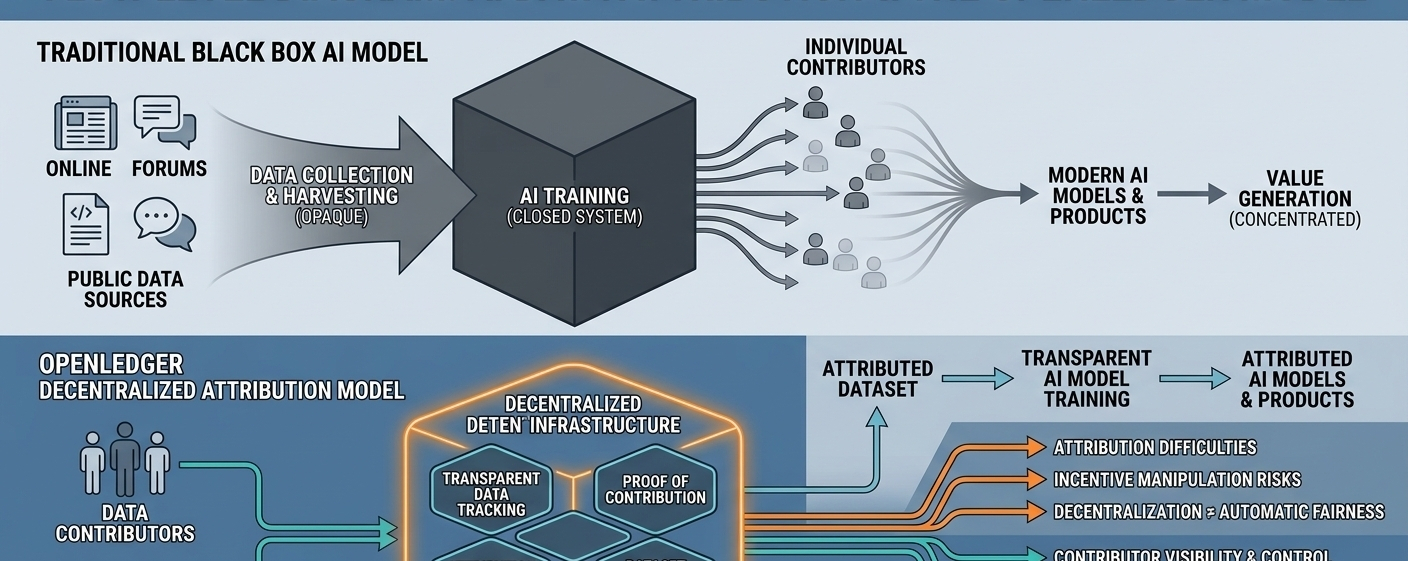
更深層次的問題是,現代人工智能系統極其難以追蹤。一旦數據進入神經網絡,它就成爲更大結構的一部分,信息混合在一起。與傳統數據庫不同,人工智能模型並不會將知識存儲在整齊可見的文件夾中。它們一次性從海量信息中學習模式。因此,很難識別出哪個特定數據集或貢獻者影響了最終輸出。
早期嘗試解決這個問題的項目通常只關注過程中的某一部分。有些項目嘗試去中心化存儲系統。其他項目探索基於區塊鏈的人工智能市場或聯邦學習。研究人員還實驗了數據集水印和創建透明的訓練系統。但大多數這些想法在從理論轉向現實使用時遇到了困難。技術挑戰比預期的要大得多。
這正是 OpenLedger 嘗試定位的空間。該項目並不專注於構建另一個人工智能聊天機器人或直接與大型模型提供者競爭,而是專注於人工智能本身的基礎設施。它更廣泛的論點很簡單:如果人類生成的數據在人工智能發展中扮演如此重要的角色,那麼應該有更好的系統來跟蹤貢獻和理解價值在網絡中的流動。
OpenLedger 背後的一個主要思想是所謂的“歸屬證明”。簡單來說,這是試圖將數據貢獻者與人工智能系統後續使用信息的方式連接起來。該項目希望創建一個結構,使數據集、模型活動和輸出能夠更透明地鏈接,而不是消失在黑箱中。
起初,這個想法聽起來合理,因爲其他數字行業已經依賴於歸屬系統。音樂平臺追蹤流媒體和版權收入。軟件社區監控代碼貢獻。社交平臺上的內容創作者越來越期待擁有和貨幣化工具。與這些行業相比,人工智能在承認貢獻方面仍然運作着令人驚訝的脆弱系統。
OpenLedger 還引入了“數據網”的概念,旨在創建有組織的環境以收集專門的數據集。這個項目建議,社區和貢獻者可以爲特定行業或用例構建更集中化的數據生態系統,而不是完全依賴於龐大的集中式互聯網數據池。
這很重要,因爲人工智能正在逐漸從簡單地收集大量通用在線內容轉變。專業化的人工智能系統現在需要更準確和經過策劃的信息。醫療模型需要可靠的醫學知識。法律人工智能系統依賴於結構化的法律文檔。企業人工智能工具通常需要私有的操作數據。在這些情況下,質量比數量更重要。
OpenLedger 的另一個有趣之處在於,它關注推理過程中的歸屬,而不僅僅是訓練。大多數人工智能用戶從來不知道哪些外部信息源影響了他們所接收到的答案。OpenLedger 嘗試使這些關係更可見。目標不僅是透明性,還有可能在這些數據被積極使用時,貢獻者能夠最終受益。
該項目還通過像 OpenLoRA 這樣的系統探索效率,專注於輕量級的人工智能模型適配器,而不是反覆訓練完全獨立的模型。這種方法背後的思考是務實的。人工智能基礎設施的成本日益高昂,模塊化系統可能爲支持特定人工智能應用提供更靈活的方式,而不必每次都從頭開始重建一切。
不過,這一願景顯然存在清晰的侷限性。人工智能系統內的歸屬仍然是行業中最困難的技術問題之一。神經網絡的工作方式並不像簡單的數學方程,每個輸出都有一個明顯的來源。這些系統中的知識分佈在數十億個參數中,使得完美的歸屬變得極其困難。
還有激勵的問題。任何獎勵貢獻的開放網絡最終都會面臨垃圾信息、操縱和低質量提交的問題。一些參與者自然會試圖利用系統來獲得獎勵,而不是貢獻有意義的數據。在實踐中,保持質量的同時讓參與保持開放,比理論上聽起來要困難得多。
治理又帶來了另一個挑戰。許多去中心化項目開始時承諾公平和社區參與,但影響力往往集中在早期內部人士或技術先進的參與者手中。隨着時間的推移,OpenLedger 可能會面臨類似的問題,因爲去中心化系統並不會自動消除權力不平衡。
隱私問題也仍然沒有解決。完全透明在理論上可能聽起來很吸引人,但許多組織不願意暴露敏感的訓練數據或內部工作流程。金融、醫療保健和企業安全等行業通常優先考慮隱私和操作控制,而不是開放性。找到透明性和機密性之間的平衡並不容易。
即使有這些擔憂,OpenLedger 反映了人工智能行業正在發生的更廣泛轉變。討論正在慢慢超越模型性能,轉向關於所有權、責任和數據關係的更深層次問題。隨着人工智能系統越來越融入日常生活,這些問題變得越來越難以忽視。
那些可以從這樣的系統中受益最多的人是那些在人工智能經濟中目前獲得很少認可的小型貢獻者。獨立研究人員、小衆社區和專業專家往往創造有價值的信息,但對他們的工作如何被後續使用沒有任何可見性。一個透明的歸屬層可能會讓這些貢獻者在生態系統中獲得更多參與。
與此同時,沒有任何保證去中心化基礎設施自動創造公平。擁有更好資源、更大數據集或更強技術知識的參與者仍可能主導系統。開放網絡可以重新分配權力,但不一定使所有參與者的訪問平等。
使 OpenLedger 有趣的是,它並不聲稱解決與人工智能所有權相關的所有問題。更重要的一點是,它突顯了已經存在於行業表面之下的一個弱點。現代人工智能系統在很大程度上依賴於人類生成的知識,但歸屬和參與的機制仍然顯得不完整。
隨着人工智能的不斷髮展,最大的爭論可能最終不僅僅在於哪家公司構建了最聰明的模型。更棘手的問題可能是,貢獻知識的人是否會保持隱形,或者未來的人工智能基礎設施是否會開始將數據貢獻視爲值得以有意義的方式認可的事情。
