人工智能的快速發展暴露出一個巨大的結構性問題:數據壟斷。目前,大型集中式科技公司控制着絕大多數的AI訓練數據、基礎設施和模型部署。這創造了一個封閉的生態系統,獨立創作者、數據貢獻者和開源開發者完全被排除在價值循環之外。
這正是@OpenLedger OpenLedger 介入改變遊戲規則的地方。基於斯坦福大學十多年的深入學術研究,該網絡正在設計去中心化AI的最終執行層。它提供了一個安全的、區塊鏈原生的環境,數據、模型和自主AI代理可以無縫互動,具備絕對的密碼學證明和自動化的價值分配。
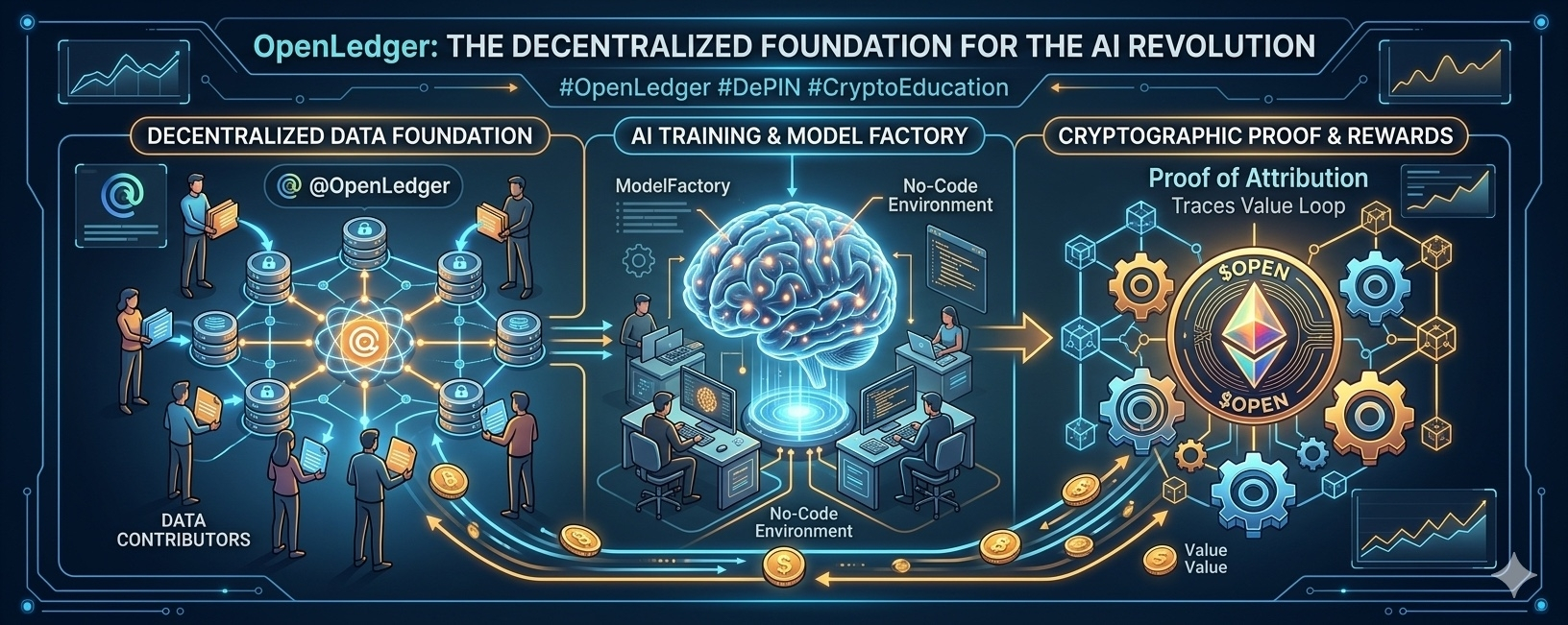
🛠️ 核心架構:如何解決AI數據危機
與其作爲一個黑箱運作,用戶不知道他們的數據如何被使用,#OpenLedger生態系統採取透明的多層次方法來處理AI開發的生命週期:
數據集:這些是專門的衆包中心,旨在從全球聚合獨特、高質量的數據集。
ModelFactory:一個高度可訪問的無代碼環境,允許開發者設計、訓練和測試AI模型,而無需大量資本或專有服務器設置。
歸屬證明:這是協議經濟的核心。它加密追蹤確切哪些數據點影響了特定模型的輸出或推理,確保貢獻者根據其實際價值獲得公平回報。
📈 現實世界的集成與$OPEN 的實用性
與純粹依賴概念炒作的項目不同,$OPEN代幣的實用性與核心鏈上操作直接掛鉤。它作爲生態系統的原生燃料代幣,支持從模型推理費用、質押機制到跨網絡治理決策的所有內容。
該協議的實際效用已通過大規模網絡集成得到驗證。從與Injective的合作以實現完全可驗證的鏈上AI代理執行,到與Story Protocol合作解決AI訓練數據和版權許可的法律複雜性,基礎設施正在走出實驗室,進入實時Web3經濟。
隨着對去中心化計算能力、可驗證數據來源和倫理AI開發需求的增長,專門的第一層協議的角色將變得不可否認。基礎設施資產在牛市中通常不是最響亮的,但它們始終是構建長期價值的資產。