
At the end of March 2026, Anthropic's flagship programming tool Claude Code experienced perhaps the most sensational technological event of 2026 - an accidental update of an npm package exposed over 512,000 lines of source code and 4,756 files directly to the public internet.
The entire AI developer community in Silicon Valley is in a frenzy.
Security researchers exploit vulnerabilities, product managers study functional details, and entrepreneurs seek business opportunities, but what has most shaken the industry is that this leak has unveiled a secret that has never been presented so completely before:
How much engineering effort did Anthropic spend on building an extremely sophisticated memory system?
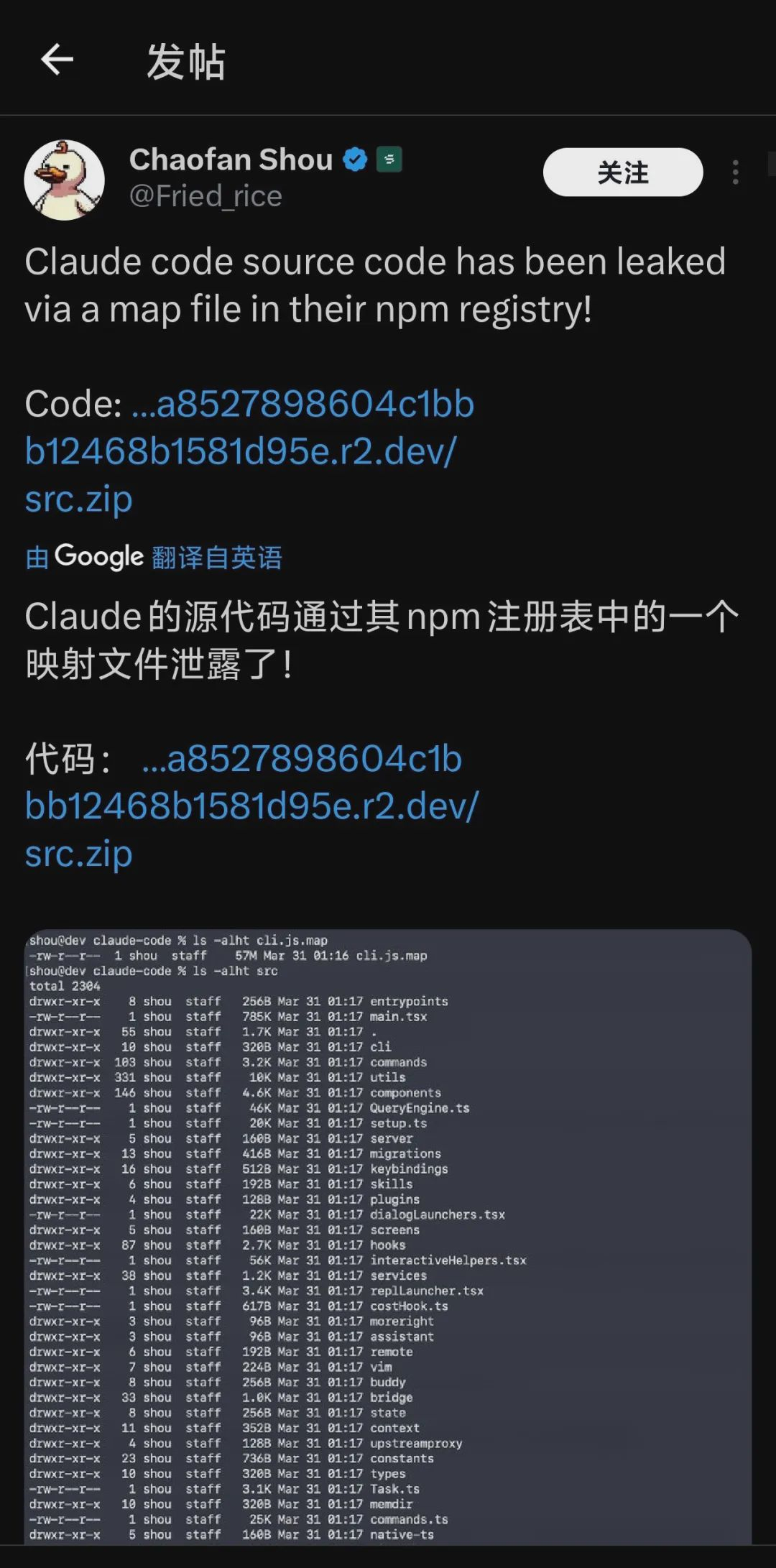
1. The Claude Code leak incident: a rare "perspective"
The source code of Claude Code reveals the engineering depth that top AI companies have in memory systems.
This is not simply "storing conversations"; Anthropic has built a multi-layered, sustainable self-repairing context management architecture: three layers of memory structure + self-repair mechanism.
Claude Code divides memory into four types (user preferences, feedback, project context, reference materials), each with independent storage and retrieval paths; memories are stored in Markdown format, managed through frontmatter for metadata, and indexed with MEMORY.md to provide a "relevance selector" - recalling only the most relevant memory segments, not loading everything.
More critically, there is a self-repairing memory mechanism: when the system detects high context entropy, it automatically triggers a repair process - cleaning up outdated pointers, updating indexes, and organizing fragmented memories. Plus, the KAIROS system - a continuously running background agent that integrates your memories while you sleep.
Claude Code's query engine has five layers of compression built-in: automatic compression → micro-compression → segment compression → context folding; when tokens are running low but tasks are not yet finished, the system injects an invisible meta-instruction: "just continue, no apologies" - user experience is seamless, supported by a complex state machine in the background.

2. Why are all large models struggling with memory systems?
After the leak of Claude Code, the entire industry suddenly reached a consensus: the gap in the models is being bridged by memory systems.
Is there a significant gap between GPT-4 and GPT-3.5? Yes, but if GPT-3.5 had a perfect memory system that remembered all of the user's work scenarios, preferences, and industry knowledge - it might not necessarily lose to GPT-4 on many tasks.
In other words: once you solve the problem of "AI can't remember", the gap in the model itself is not that critical.
Three levels of AI applications:
Layer One: Conversational ability - you ask, it answers; ChatGPT has already done well enough.
Layer Two: Task execution - AI helps you write code, send emails, manage schedules; Claude Code and Cursor are players at this level.
Layer Three: Continuous cognition - AI maintains memory, accumulates experience, and actively suggests in long-term tasks; this is the core threshold of the Agent era, and memory systems are the infrastructure.
An AI without memory starts every conversation from scratch, while an AI with memory is your true "digital twin" - it understands your industry, your style, and your clients faster than any new colleague.
The leak of Claude Code confirms this: Anthropic is already strong enough in model capabilities, but they are still investing heavily in memory systems; this is not a coincidence, it's a strategic choice.

3. Where exactly is the difficulty in memory systems?
Challenge One: What to store? - Not all information is worth remembering; Claude Code's "relevance selector" addresses this issue by recalling on-demand, not loading everything.
Challenge Two: How to remember? - Requires vector databases, semantic understanding, and hierarchical storage; memory needs to be structured for quick retrieval.
Challenge Three: Who owns it? - This is the most critical question: who does your AI memory belong to? Today, most AI products store their memories on platform servers - you do not own it, cannot take it with you, just like your WeChat chat history theoretically belongs to Tencent.
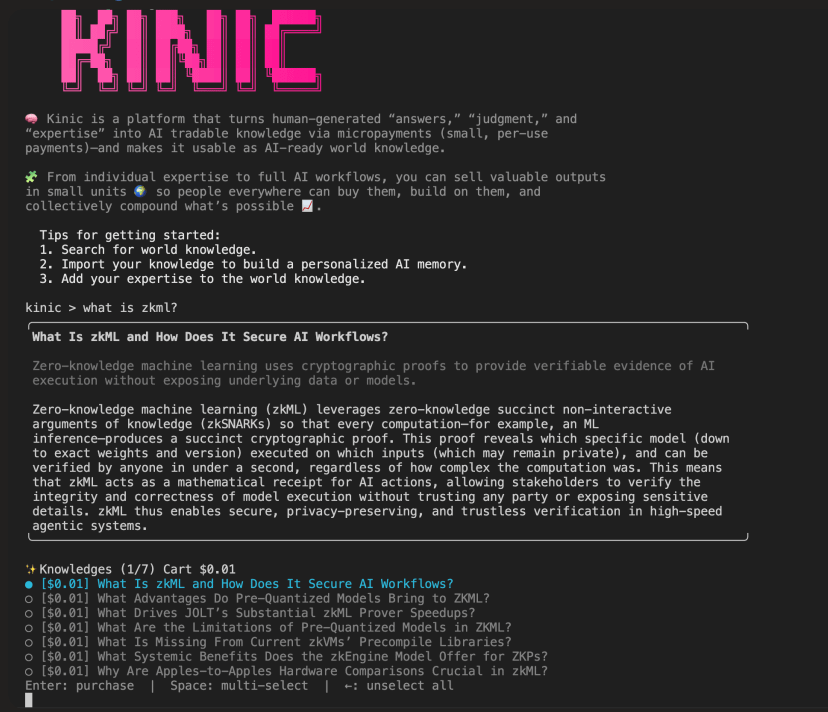
Whoever can solve the problem of "ownership of memory" can establish a truly user-owned AI ecosystem; this is exactly what Kinic aims to achieve.

4. Kinic: Currently the most complete "memory ownership" solution
Kinic (kinic.io) is launched by ICME Labs and is based on the Internet Computer (ICP) blockchain protocol, attempting to fundamentally solve the three challenges of AI memory.
In one sentence: turn everyone’s expertise into "memory assets" that AI can rent for payment.
A specific scenario: you are an interior designer with 15 years of experience; you know the price trends in every area of Beijing, you know what styles are most practical in different layouts, and you have stepped into countless pitfalls, accumulating a wealth of real cases.
Today, if someone wants to gain this experience, they either pay 500 yuan/hour for your consultation or buy a possibly outdated book, but what if this experience could be turned into "professionally mappable AI queryable memory"?
Someone asked AI: "I bought a second-hand apartment of 80 square meters in Beijing, my budget is limited, how to decorate it most practically?"
AI calls upon your memory, providing truly professional answers, and you earn passive income - not by taking orders, but your knowledge earns money for you 24 hours a day.
This is what Kinic refers to as the "context market": turning expertise into AI-rentable contextual assets.

5. Kinic's technological moat: Why is it said to be deep?
Moat One: zkTAM - Zero-Knowledge Trustworthy Agent Memory
This is Kinic's core technological innovation.
Today's AI memory exists in vector databases - but can this memory be tampered with? Is the memory received by AI really what it should receive?
For example: you commission an AI to help you make investment decisions; it queries the memory database for "analyst recommendations for a certain stock"; how do you know this recommendation is real and not maliciously injected?
zkTAM (Zero-Knowledge Trustless Agentic Memory) uses zero-knowledge proofs (zkML) to solve this problem: the embedded vectors of memory can be mathematically proven to be correct and unaltered - no need to trust any centralized server, no need to trust vector databases, no need to trust embedding models.
The JOLT Atlas framework of ICME Labs even achieved 3-7 times performance optimization - this is a hard barrier combining cryptography and engineering capability, this is the "anti-counterfeit label" of memory systems, and also Kinic's moat that is hardest to replicate.
Moat Two: Decentralized storage - you truly own your memory
Kinic's memory does not exist on AWS or Alibaba Cloud; it exists on the Internet Computer (ICP) chain, operating in the form of WASM Canisters.
You own your memory, with keys and full control
Memories cannot be deleted or frozen by any platform
Can be migrated between different AI services - no memory loss when switching platforms
Just like your blockchain wallet - truly belongs to you, not to a company, while the memories of ChatGPT, Claude, and Kimi are stored on platform servers, and you cannot migrate, backup, or truly own them.
Moat Three: Vectune - a vector database optimized for AI memory
The Kinic team has developed the Vectune vector database running on-chain, using VetKey encryption technology to securely store memory content while maintaining query capabilities; traditional services like Pinecone and Weaviate are centralized - your memory exists on someone else's server, while Vectune decentralizes this and solves both encryption and querying issues.
Moat Four: ERC-8004 + x402 - enabling automatic trading between AI agents
This is Kinic's business closed loop, and also the infrastructure of the entire memory economy.
ERC-8004 is Ethereum's "trustworthy agent" standard - it defines how AI agents register identities, accumulate reputations, get verified, and discovered; this solves the problem of "who does the trading".
The x402 protocol (developed by Coinbase) enables automatic micropayments between AI agents - querying professional memory costs 0.1 USD, the system automatically settles without manual intervention, solving the problem of "how to trade".
A combination of both: a complete "memory economy" can self-operate - knowledge creators upload memories → AI agents discover and pay to query → both parties need no trust in each other, with a mathematical guarantee of fairness; this is not imagination, but a payment protocol that has been successfully implemented.

6. Why is it said to represent the future direction?
The leak of Claude Code reveals a validated signal: even top players like Anthropic are investing so much engineering resources into memory systems.
The competition of the Agent era will be a competition of "specialized memory"; imagine this:
An AI for doctors, with 20 years of clinical experience memory
An AI for lawyers, with memory of 500 real cases
An AI for operators, with memory of 1000 event planning experiences
These memories are the truly valuable assets - not the model itself, but the expertise embedded within the model.
Claude Code has already proven this; its strength is not just because of how smart the Claude model is, but because it has the ability to construct, maintain, and use long-term memory.
Kinic's judgment is correct: the competition in AI over the next decade will not be at the model level, but at the memory level.

7. Objectively speaking, Kinic also has limitations
To be frank, Kinic is still in its early stages (Open Beta v0.1), and its limitations are real:
Need 1 KINIC token to deploy memory (high threshold)
Requires dfx CLI + Rust toolchain (extremely unfriendly to ordinary users)
The entire system relies on the ICP blockchain ecosystem (ecosystem is still small, user base is limited)
The business model still needs to be validated in the real market
But these limitations are understandable for a project still in the beta stage - they prioritize building technological moats rather than pursuing user experience.
For the Chinese market, Kinic's concept is more valuable than its specific products; it proves three points:
Memory systems are infrastructure worth reinvesting in
The "ownership" of memory is a real user pain point
The memory economy is technically feasible

Conclusion
The leak of Claude Code has revealed a truth to the entire industry: AI competition has shifted from "who is smarter" to "who remembers more".
Memory systems are not a feature; they are an infrastructure-level track.
The 510,000 lines of code that Anthropic invested in Claude Code is the industry's most honest declaration.
Kinic is currently one of the farthest explorers - it uses zero-knowledge proofs to solve "the credibility of memory", decentralized storage to solve "the ownership of memory", and automatic payments to solve "the trading problem of memory".
The solutions to these three questions may not be the only answers, but at least they prove that this path is feasible.
In the next decade, whoever masters memory will master the gateway to the Agent era.
#Anthropic #claudecode #KINIC #AI
The IC content you care about
Technology Progress | Project Information | Global Activities

Follow the IC Binance channel
Stay updated with the latest information