
I've been watching infrastructure plays for years, and one thing that separates durable projects from the noise is not how fast they move when everything is calm, but how they behave when systems break. Walrus approaches that idea head-on. Instead of promising perfect uptime or pretending risk doesn’t exist, it assumes failure will happen and designs around it. Nodes will go offline. Rules and regulations will shift. The question is not if these things happen, but whether the system survives them.
At its core, Walrus is honest about what decentralized storage really is. Storage is not a short-term activity. Data needs to stay available years after it is uploaded, often long after the original user stops paying attention. That creates a structural problem in crypto. Tokens lose favor. Many networks ignore this and rely on optimism. Walrus does the opposite. It tries to lock reliability into the system itself.
The project moved from concept to concrete design in the second half of 2024, when its whitepaper outlined a clear economic and technical structure. The design centers on upfront payments for storage, paid in the WAL token, which are then released gradually over time to storage operators and stakers. This may sound simple, but the implication is important. Operators are paid for staying reliable, not for showing up once. If a node fails, the system has already collected the resources needed to move the data elsewhere.
To explain this without jargon, think of it like a long-term lease with a security deposit. The network doesn’t just trust a landlord to behave. Operators stake it. Stakers back them. If someone disappears or cheats, there is a direct financial consequence. That creates discipline without relying on trust.
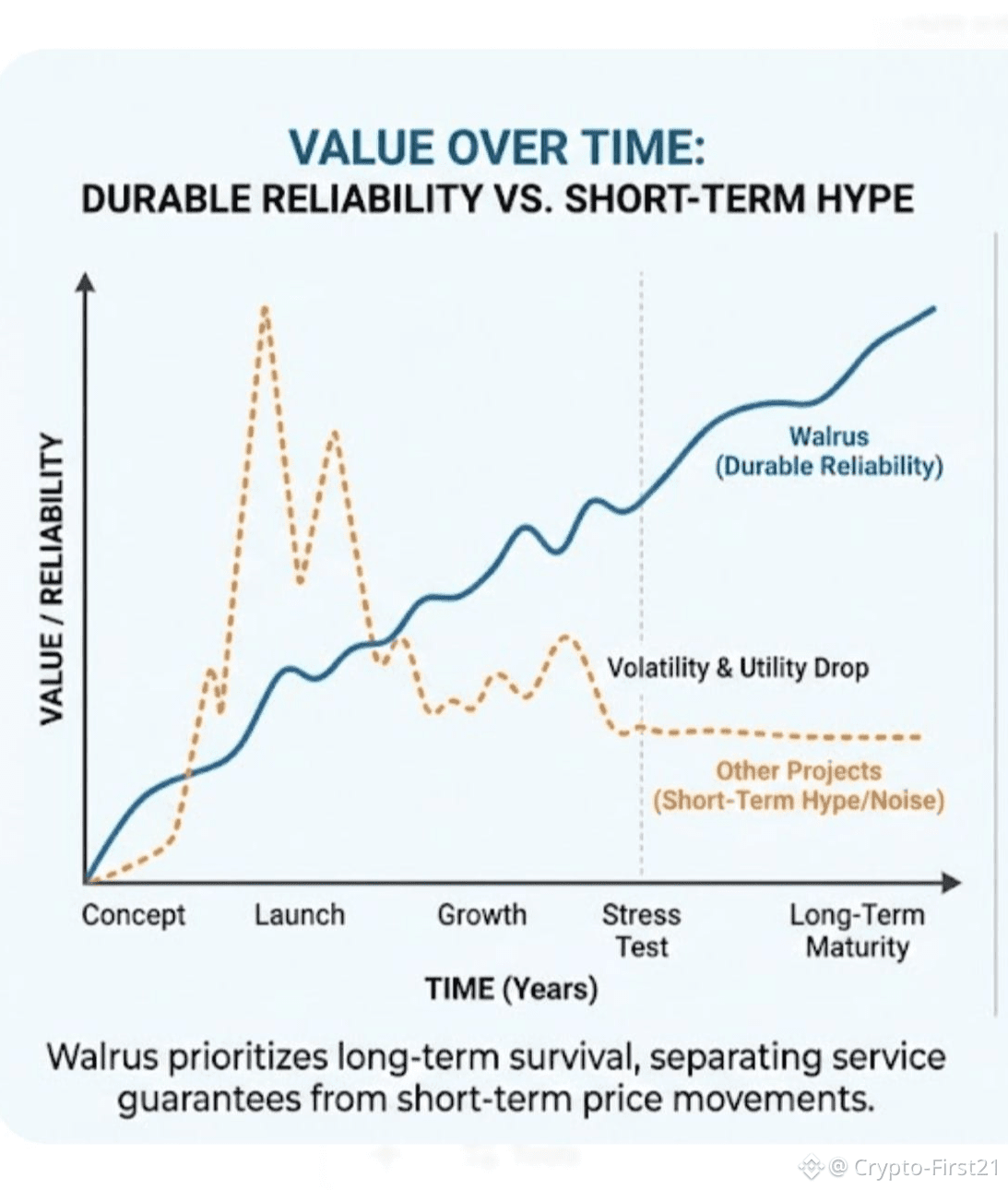
From a market perspective, this approach reduces a specific kind of risk that traders often underestimate. Many storage tokens collapse not because demand disappears, but because providers lose incentive to keep servicing old data. When that happens, utility drops, confidence evaporates, and price follows. Walrus tries to prevent that spiral by separating short-term token price movements from long-term service guarantees. Storage pricing can be stabilized even if WAL is volatile, which matters if you expect real companies to use the network.
This focus is one reason Walrus started gaining attention through 2025. It wasn’t just retail interest. The launch of institutional products tied to WAL signaled that some traditional finance players saw it as infrastructure rather than a quick trade. That doesn’t mean price stops moving. It means the conversation shifts from hype to durability. For a mid-cap protocol, that shift is meaningful.
On the technical side, Walrus leans into redundancy rather than speed. Data is split into pieces and distributed across many independent nodes. Even if several nodes fail at once, the original file can still be reconstructed. Operators must regularly prove that they still hold the data. If they fail those checks, the network reallocates responsibility automatically. There is no manual intervention, no waiting for governance votes while data disappears.
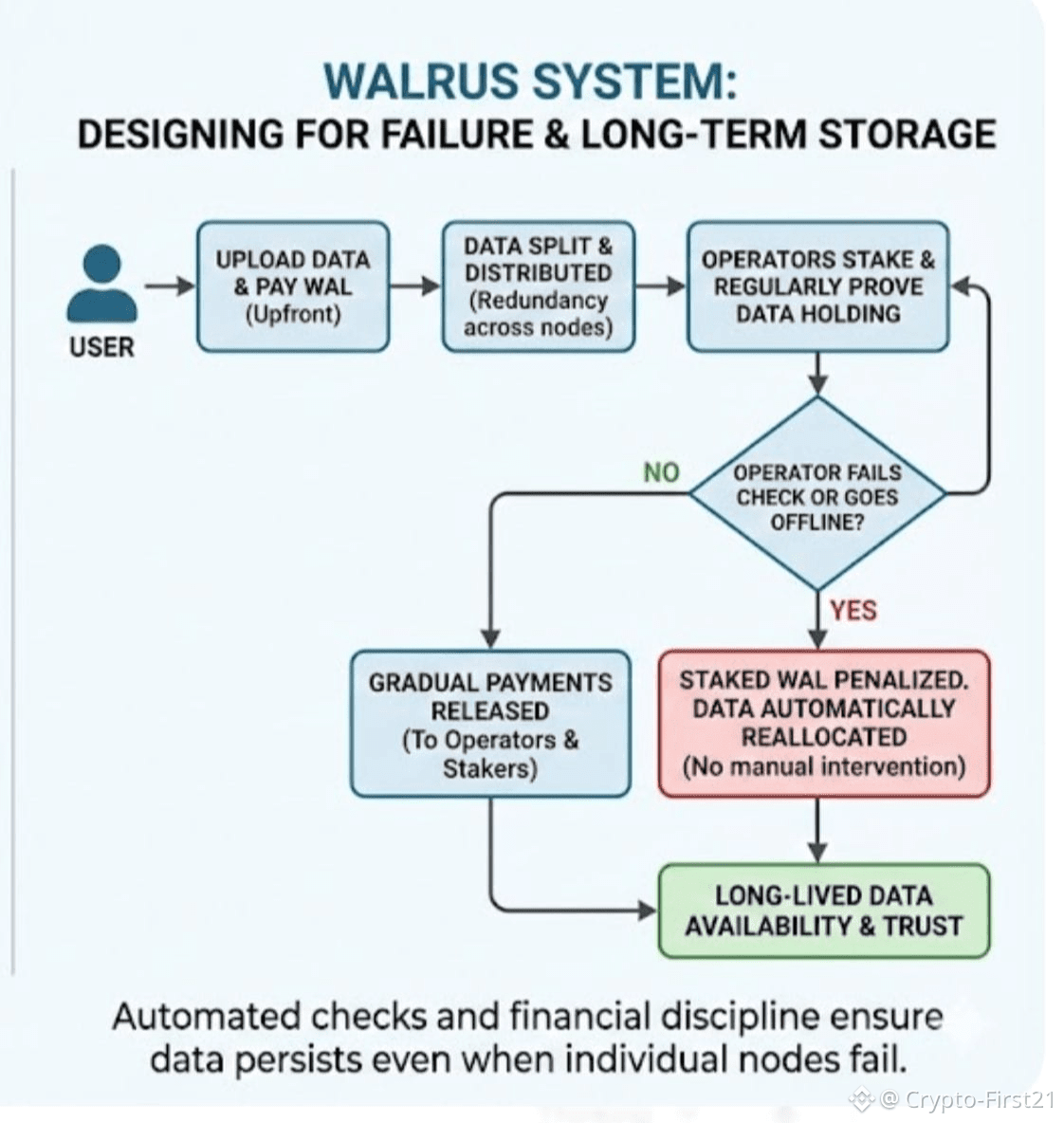
Of course, none of this is free. Strong defenses introduce friction. Proof systems add overhead. Yields can look less attractive compared to riskier alternatives. But these trade-offs reveal intent. Walrus is not optimized for short-term speculation or high churn. It is optimized for long-lived data and users who care about reliability more than speed.
From my perspective, that makes sense. Markets go through cycles. Liquidity dries up. Narratives change. The projects that survive are usually the ones that planned for those moments. Walrus is effectively betting that boring reliability will matter more than flashy performance over time. That is not a popular bet in bull markets, but it tends to age well.
The team’s progress reflects that mindset. They focused on shipping core infrastructure, integrating with their base ecosystem, and slowly expanding tooling rather than rushing features. Incentive programs were used to attract early operators and developers, but without permanently inflating rewards. That balance is hard to get right, and it won’t be clear whether it worked until the network has been running under stress for several years.
So how should someone approach Walrus today? First, understand that it is not designed to move fast. If your thesis depends on quick narratives and explosive short-term adoption, this may feel underwhelming. Second, study how value flows through the system. Look at who gets paid, when they get paid, and what happens when they fail. That tells you more about long-term sustainability than any roadmap slide. Third, watch real usage. Storage networks prove themselves quietly, through uptime and retrieval success, not headlines.
I don’t see Walrus as a perfect system. No protocol is immune to regulatory pressure, design mistakes, or unexpected attacks. But I do respect its central idea. Designing for failure does not mean expecting the worst. It means accepting reality. In markets and in systems, things break. The networks that survive are the ones that plan for that truth early, not the ones that deny it. That is why Walrus is worth understanding, even if it never becomes the loudest name in the room.

