

Walrus doesn't really get tested when storage nodes are healthy.
@Walrus 🦭/acc gets tested when everything is almost healthy.
A few shards arrive late. A couple peers go quiet. Someone rotates infra. Nothing dramatic. No chain halt. Just the kind of wobble you only notice if you're trying to serve a blob to a user who refreshes twice and then leaves.
That's the quiet failure mode... the blob is still recoverable, but the path to it is not reliably fast enough to feel like storage.
And "feel" is the product.
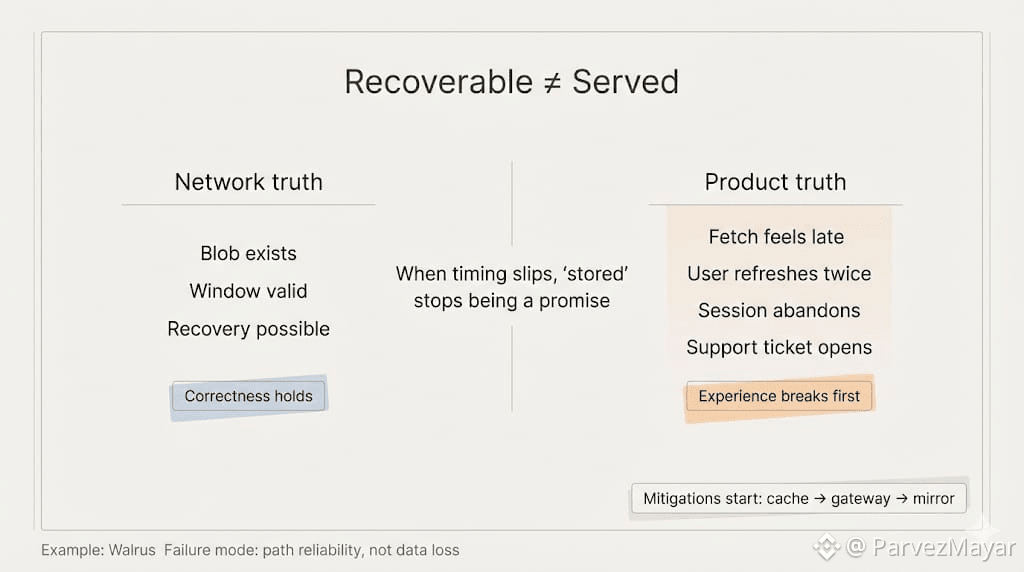
A lot of teams don't announce what happens next. They patch around it. First it's caching. Then it's a fallback gateway. Then it's 'temporary' mirrors. The blob still lives on Walrus, sure, but the user-facing moment starts avoiding it. Not as a boycott. As an instinct.
Because support tickets don't care about erasure coding.
They care about the link working.
This is where Walrus specific mechanics matter, but only in the ugliest place... overlap inside an availability window.
Reads don't pause while the network restores redundancy. Walrus' Repairs don't pause because users are impatient. Bandwidth is bandwidth. Coordination is coordination. When both happen together, the system reveals what it prioritizes: serve now, or rebuild safety first.

Neither choice is morally correct. But you start seeing a pattern.
If you keep reads fast, you borrow from repair capacity and let risk linger.
If you rebuild first, you teach apps that "stored" can still mean "wait."
Builders react to those signatures. Quietly. They don't always roll it back later.
That's how decentralized storage Walrus becomes decentralized archive...not because the data vanished, but because the fastest path to it got demoted over time, one harmless-looking mitigation at a time.
The scary part is you don't see it as a headline.
You see it in architecture diagrams that grow a "just in case" box that never gets removed.

