

Vanar feels like one of those Layer-1 projects that’s trying to solve a very boring problem on purpose: how do you make Web3 feel stable enough that real products can live on it without constant friction? That’s the quiet difference between chains that stay inside crypto circles and chains that actually end up powering consumer apps.
At the center of Vanar’s story is a simple promise: this chain is built for real-world adoption, especially for teams coming from gaming, entertainment, and mainstream brands. On the outside, that looks like “next 3 billion users” messaging. Under the hood, it shows up in the design decisions they highlight again and again—predictable fees, familiar developer tooling, and a stack that tries to make data and logic more useful on-chain instead of leaving everything to off-chain systems.
One reason Vanar stands out right now is that they don’t present the chain as the whole product. They present it as the base layer of a larger “intelligent stack.” In their own words and architecture layout, the idea is that the chain sits at the bottom, then layers above it handle semantic memory, reasoning, automation, and eventually industry-specific application flows. That matters because most real products don’t fail because “the chain can’t do transactions fast enough.” They fail because data becomes messy, compliance becomes messy, workflows become messy, and suddenly the application is 80% glue and 20% blockchain. Vanar is basically saying: let’s build the parts people usually duct-tape together, and make them native.
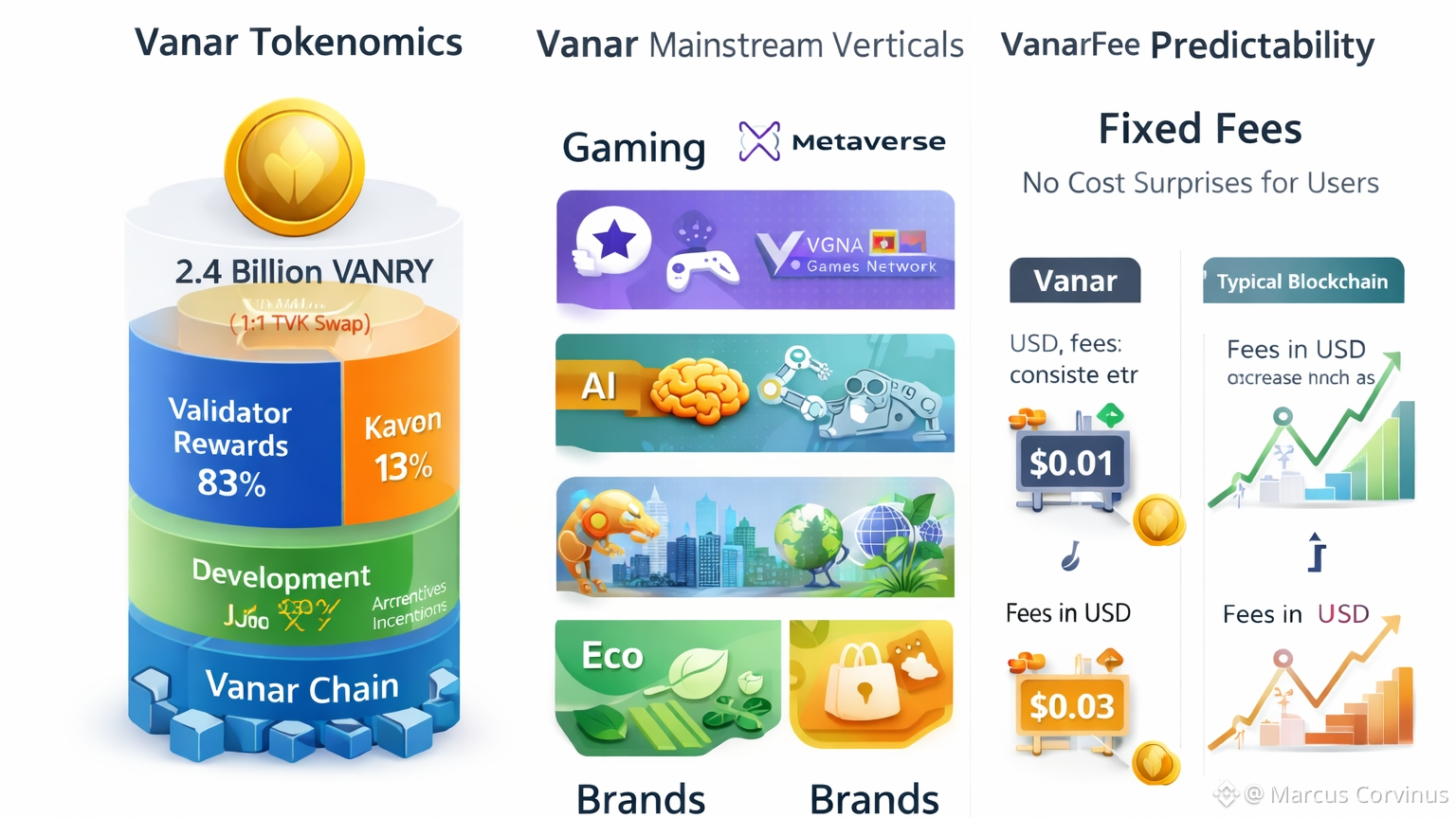
The “why it matters” becomes clearer when you look at their fee philosophy. Vanar documents describe a commitment to determining transaction charges using the USD value concept rather than letting users get whiplash from the gas token’s market swings. Their docs explain that the Vanar Foundation calculates VANRY’s market price using on-chain and off-chain data sources, then integrates that value into the protocol so fees stay consistent, with updates happening on a frequent cadence (their docs describe an update workflow and a token price API feeding the protocol).
This isn’t just a “nice feature.” It’s a very specific bet: if you want mainstream apps, you can’t have a user experience where one day a simple action costs pennies and the next day it costs multiples just because the token price moved. Predictability is what lets builders price products, plan growth, and avoid users feeling punished for simply using an app.
Now, the bigger “behind the scenes” shift in Vanar’s latest positioning is this AI-native stack narrative. On the official site, Vanar describes a five-layer architecture: the transaction layer (Vanar Chain), a semantic memory layer (Neutron), a reasoning layer (Kayon), and then two layers labeled as coming soon—Axon (automation) and Flows (industry applications).
Neutron is described as a semantic compression and storage system that turns raw files into “Seeds” that remain on-chain, verifiable, and usable by apps and agents. The claim is aggressive: compress large files (example: 25MB) down to much smaller representations (example: 50KB) using semantic + heuristic + algorithmic layers, while keeping them cryptographically verifiable. Whether you view this as a breakthrough or a challenge to prove at scale, the intent is very clear—Vanar wants data to be more than dead storage. They want it to become something that can be searched, referenced, and acted on directly.
Kayon is positioned as the reasoning layer that sits above that data. Their description focuses on natural-language querying, contextual reasoning across datasets, and compliance-style workflows that can be enforced “by design.” Again, the important part here is not the marketing words—it’s the direction: if Neutron turns real-world files into on-chain “knowledge objects,” then Kayon is supposed to turn that knowledge into decisions and actions.
So when you ask “what are they doing behind,” the best answer is: they’re trying to build a chain where data + meaning + logic can live together. That’s the infrastructure you need for things like PayFi flows, tokenized real-world assets, and enterprise workflows—because those systems don’t just need a ledger, they need documents, rules, conditions, audits, and triggers. Vanar is directly aiming at that intersection.
The token side is also designed to feel structured, not vague. In the Vanar whitepaper, VANRY is described as the native gas token, similar to ETH’s role on Ethereum. The whitepaper states a max supply of 2.4B tokens, with 1.2B minted at genesis tied to a 1:1 swap from TVK to VANRY, and the remaining 1.2B minted gradually as block rewards over a long timeframe (20 years). It also gives a distribution breakdown for the additional 1.2B: 83% validator rewards, 13% development rewards, 4% airdrops/community incentives, and explicitly “no team tokens.”
Vanar’s docs reinforce the block reward structure and also mention that the inflation rate is designed as an average over 20 years (with higher issuance earlier to support ecosystem needs).
On consensus, Vanar’s documentation describes a hybrid model: Proof of Authority (PoA) governed by Proof of Reputation (PoR), with the Foundation initially running validator nodes and onboarding external validators through a reputation process.
That’s the tradeoff profile in one sentence: they’re choosing stability and controlled onboarding early, while describing a path toward broader validator participation.
What’s next is already visible in how their stack is labeled. Axon (automation) and Flows (industry applications) are presented as the next layers that move Vanar from “infrastructure that stores and reasons” into “infrastructure that automatically executes workflows and ships packaged industry logic.” If Vanar executes well, this is where the project becomes easier for builders: not just primitives, but actual end-to-end rails for real applications.
The benefits, if you boil them down, are practical:
Vanar is aiming for predictable fees that don’t punish users for token volatility, which is critical for mainstream product UX.
Vanar is pushing a stack where data can be stored as verifiable, usable on-chain objects (Neutron Seeds), which targets a real bottleneck for finance and enterprise-style workflows.
Vanar is building reasoning and query layers (Kayon) intended to make on-chain systems feel more “intelligent” and operational, especially for compliance-heavy use cases.
And VANRY tokenomics are described with a clear max supply, long emission schedule, and a distribution model that heavily prioritizes network security incentives.
Where Vanar “exists” in the market is basically this: it’s competing in a world where there are many L1s, but very few that convincingly explain how they’ll serve real workflows that involve documents, rules, payments, and regulation-adjacent logic. Vanar is placing its bet on being that base layer plus the intelligence layers above it.
Now,what’s new.
VANRY’s market data shows it around $0.0071–$0.0072, with roughly $3.1M 24-hour trading volume and about -8% change over the last 24 hours on one widely used tracker (with circulating supply shown around 2.23B and max supply 2.4B).
Another large tracker shows a similar picture with 24h volume closer to ~$4.0M, which is normal because venues and reporting differ, but the direction matches: active trading day with a noticeable dip.
On the “project update” side, I did not see a brand-new official long post dated today on the main blog listing; the most recent official recap surfaced in focusing on the idea that intelligence, memory, and context are becoming the product layer.
