Let me present a real scenario you must have experienced: the same research, you draft with GPT during the day, switch to Claude for structure at night, and then use Gemini for sourcing information the next day – as a result, every time you switch platforms, you have to reinterpret 'who I am, what I am writing, how far I have pushed it, what style I do not want.' You think you are using AI, but in fact, you are paying 'context tax' to AI. This is what I mean: the most expensive thing in the AI era is not computing power, but the fragmentation of memory.
So I increasingly reject the slogan of 'AI Ready'; I only treat it as an engineering problem: for an intelligent agent to complete a task, it must meet at least four conditions – walk with context (memory), be able to explain why it does this (reasoning), turn judgments into executable actions (automation), and settle results with predictable costs (settlement). TPS is certainly important, but it should not be the primary metric; for intelligent agents, 'being able to run a closed loop stably' is much more valuable than 'being able to score.'
Vanar today is not just saying 'we also do AI', but instead presents the 'memory layer' for you to touch. It clearly states with myNeutron: you need a cross-platform universal knowledge base that prevents memory from being locked by a specific model or chat window, ensuring that when switching between platforms like ChatGPT, Claude, Gemini, the knowledge base remains the same and can continuously inject context. This step may seem like 'a product', but essentially it is infrastructure—because only when memory can be carried across platforms, can agents become 'long-term project managers' rather than 'temporary workers for a single session'.
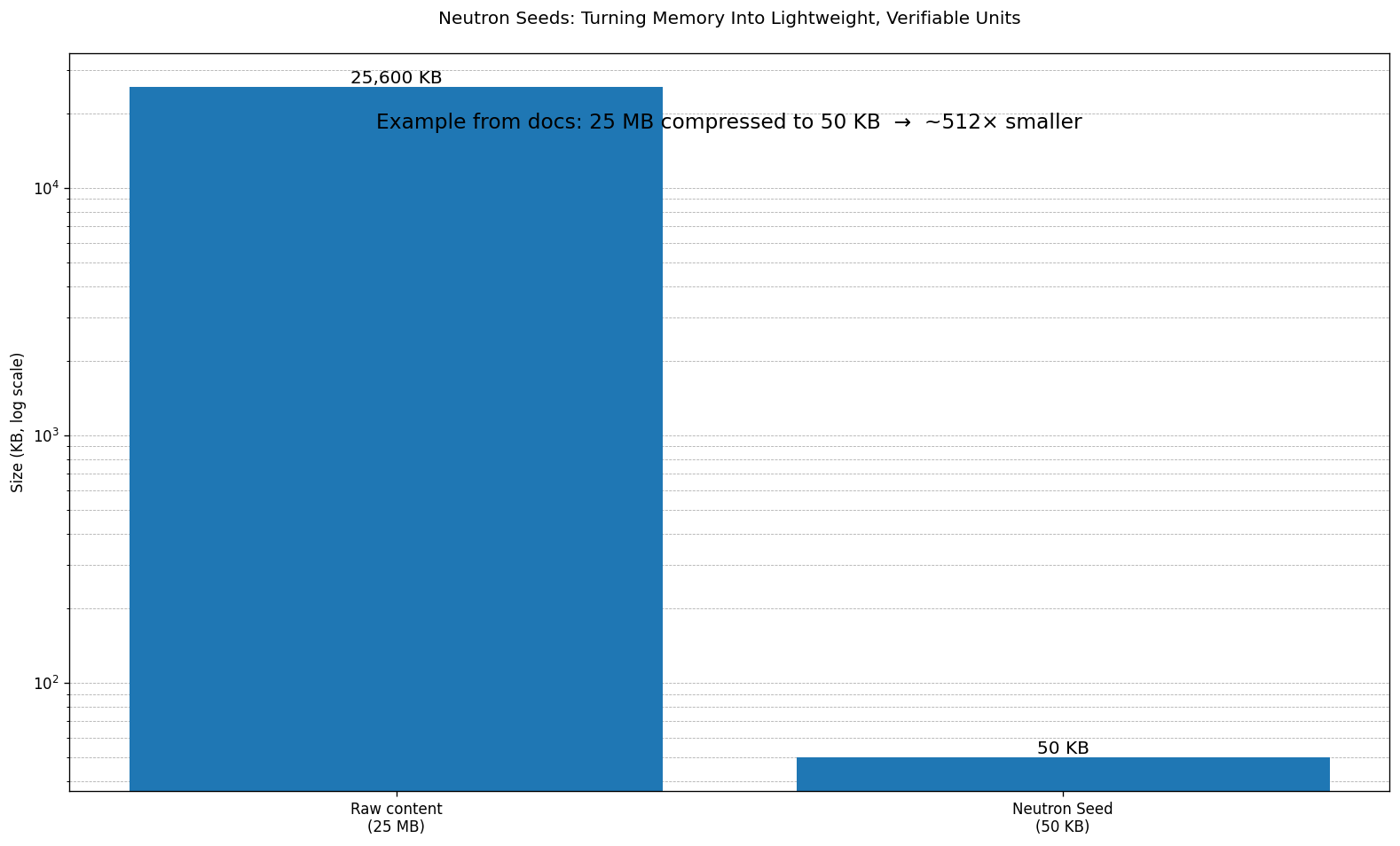
But the significance of myNeutron goes beyond just 'centralizing information'. The truly hardcore part is the layer behind it, Neutron: Vanar has written Neutron as a kind of 'AI-native memory layer', where the core action is not to store files, but to restructure data into programmable Seeds. The official page gives a very powerful number: 25MB compressed to 50KB, using semantic, heuristic, and algorithmic layers of compression to turn raw content into ultra-lightweight, verifiable Neutron Seeds. This number is particularly useful in the article, as it makes the point 'the memory layer is not just a slogan' into a perceivable engineering achievement: it's not just linking to an IPFS, but turning content into semantic units that can be retrieved, referenced, and consumed by agents.
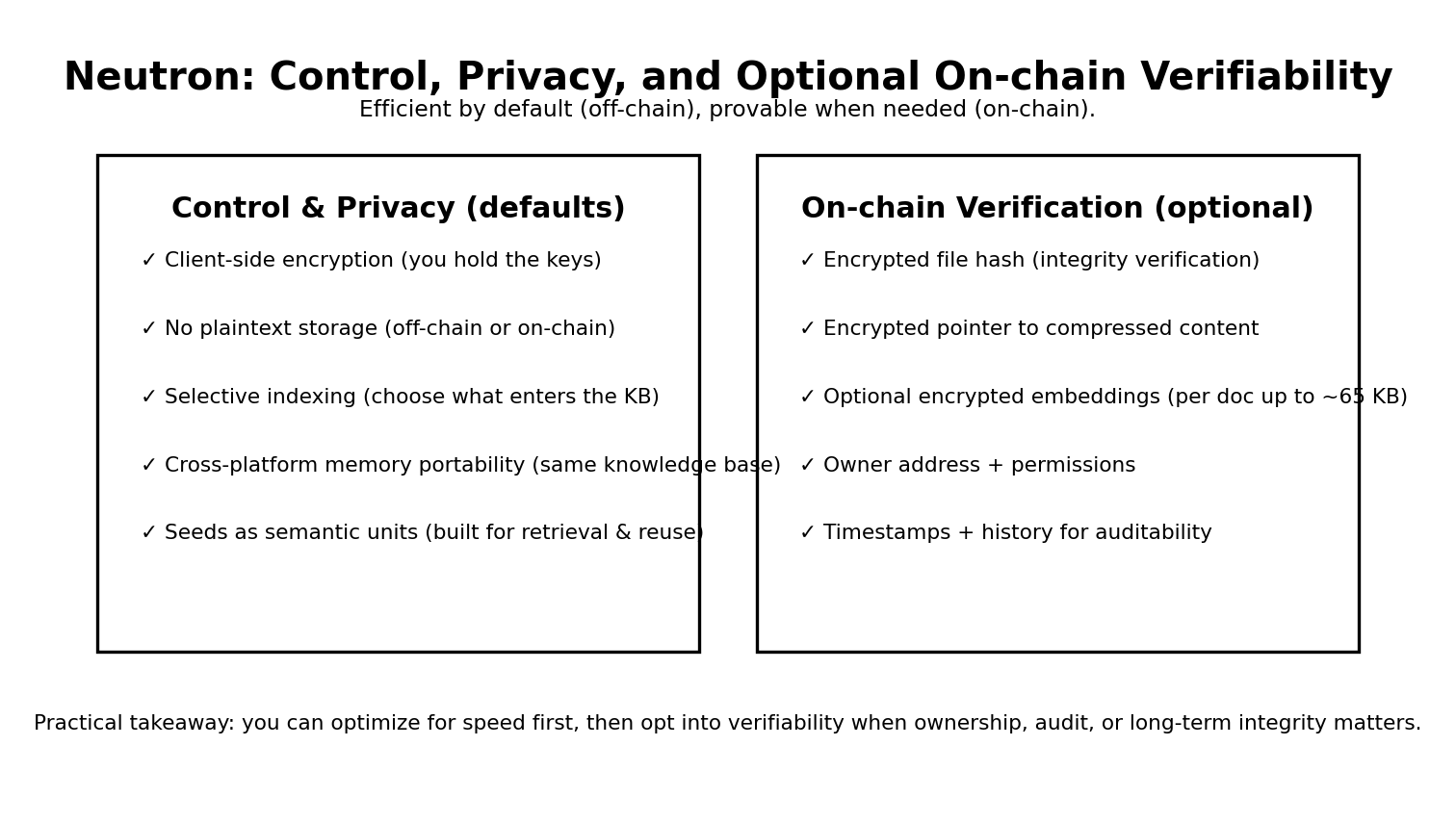
Next, you might ask: What exactly are Seeds? Don't worry, Vanar's documentation defines Seeds in a very 'engineer-like' manner: A Seed is the basic building block of Neutron, and a Seed can represent documents, emails, images, structured paragraphs, visual references and descriptions, and can even include cross-Seed link relationships; the storage approach uses a hybrid architecture—default offchain (fast, flexible), but you can choose to make it an onchain record to gain verification, ownership, long-term integrity, and auditability. This point is crucial: it separates 'efficiency' and 'trustworthiness' for you to choose, rather than forcing you to choose between performance and security.
Looking further down, technical credibility comes from details. The document explains that when a Seed is chosen to go onchain, Neutron uses a dedicated document storage contract, which will include: encrypted file hashes for integrity verification, encrypted pointers to compressed files, and can also store embeddings on-chain in an encrypted manner (up to 65KB per document), while recording owner addresses, permission settings, timestamps, and history. You see, this makes 'verifiable' concrete: verification relies on hashes, permissions rely on addresses, and traceability relies on timestamps and history, rather than just saying 'we are safe'.
The more practical question is that companies may worry: once data enters AI, will it be 'impossible to get out'? Vanar provides a clear answer in Neutron's privacy and ownership documentation: Client-side encryption means that sensitive data is encrypted on your device; No plaintext storage means that whether offchain or onchain, it does not read or store unencrypted content; and Selective indexing allows you to decide which files/messages/folders enter the knowledge base. This actually aligns with the bottom line that companies care most about: ownership is not just 'I can export', but 'I hold the keys, I decide whether to go onchain, and I decide the indexable range'.
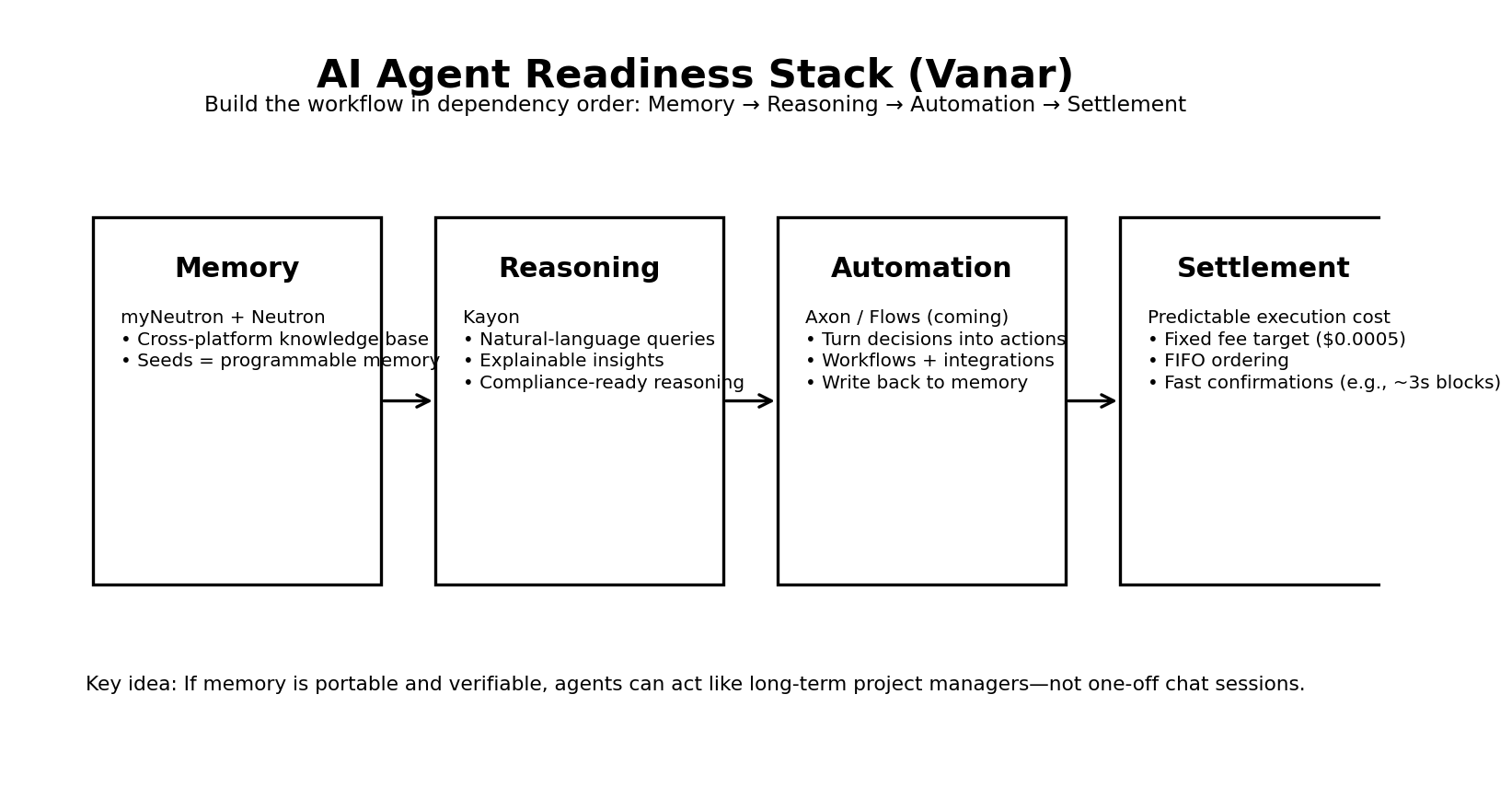
Alright, with the memory layer in place, how does 'reasoning' come to fruition? Vanar positions Kayon in the third layer as the AI reasoning layer: providing natural language blockchain queries, contextual insights, and compliance automation, with the core idea being to turn Seeds, this 'usable memory', into 'explainable judgments'. I like to summarize Kayon in one sentence: it doesn't write answers for you, it organizes your memory into actionable reasoning chains—you no longer ask 'summarize for me', but 'based on this batch of Seeds, give actionable next steps and explain why'.
The automation layer (Axon) and the industry application layer (Flows) are currently marked coming soon on the official website, but this order itself reveals Vanar's thinking: first, make memory a 'portable, verifiable, controllable privacy' infrastructure, then make reasoning an explainable interface, and only then let automation bring reasoning onto the chain. This is what I mean when I say 'AI readiness is not about putting models on-chain', but about assembling the components needed for agents to run workflows according to dependencies—first memory, then brain, then limbs.
Settlement. Once the agent starts running the workflow, it doesn't just execute a few transactions a day; it frequently 'retrieves - judges - executes - writes back to memory'. At this point, the biggest concern is not high fees, but fees that fluctuate like a roller coaster. Vanar's white paper makes this very clear: one of its fundamental commitments is to make transaction fees fixed and predictable, and to anchor low fees to the dollar value, aiming to compress each transaction to the level of $0.0005, while emphasizing that even if the gas token price changes 10x/100x, users should still pay fees close to that level. Transaction ordering also explicitly adopts fixed fee + FIFO (first come, first served), with validators packing according to mempool receipt order, avoiding 'bidding rush' that turns the automated system into an unstable auction market. Furthermore, the white paper also outlines a 3-second block time and a 30 million gas limit per block to make the system more suitable for high-frequency interactions and rapid confirmations.
So now you can connect the logic of today: myNeutron solves 'cross-platform context loss'; Neutron compresses data into Seeds, turning memory into programmable, verifiable semantic units; documents use hybrid storage and onchain contract details to supplement credibility; privacy and ownership use client-side encryption, no plaintext storage, and selective indexing to give companies peace of mind; Kayon turns memory into reasoning interfaces; and finally, the settlement layer uses fixed fees and FIFO to give agents a cost framework that can be budgeted and run long-term.
From the perspective of Web3 enthusiasts, the most appealing aspect of this narrative is: it turns 'on-chain data' from dead links into live assets; from the perspective of crypto investors, more importantly, you finally have a set of 'AI readiness indicators' to track—not by how much AI it claims to do, but by the actual retention of myNeutron's usage, the growth and structural degree of Seeds, the proportion of selective on-chain verifications, and whether the reasoning layer (Kayon) forms high-frequency, reusable queries and automated calls. Because only when 'memory x reasoning x automation x settlement' becomes real traffic, \u003cc-12/\u003e can possibly turn from a narrative asset into a pricing anchor for infrastructural behavior.
What is your biggest pain point with AI right now—is it 'having to repeat context every time', or 'the answers it gives are unexplainable', or 'it cannot be executed automatically', or 'on-chain settlement costs are unpredictable'? Choose one in the comments, and I will directly use your answer to write an executable route for 'cross-chain and scalability'.
\u003cm-35/\u003e \u003cc-37/\u003e \u003ct-39/\u003e
